String
- Strings in Python can be enclosed in either single quotes (’) or double quotes ("), or three of each (’’’ or “”")
- Double quoted strings can contain single quotes inside them, as in
"Bruce's beard" - and single quoted strings can have double quotes inside them, as in
'The knights who say "Ni!"' - triple quoted strings: strings enclosed with three occurrences of either quote symbol (either single or double quotes)

- can even span multiple lines
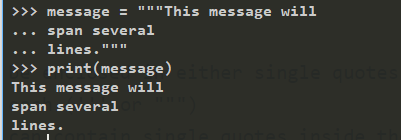
For example:
str1 = 'I told my friend, "Python is my favorite language!"'
str2 = "The language 'Python' is named after Monty Python, not the snake."
str3 = "One of Python's strengths is its diverse and supportive community."
Index
In Python, indexes are coded as offsets from the front, and so start from 0: the first item is at index 0, the second is at index 1, and so on.
>>> S = 'Spam'
>>> len(S)
4
>>> S[0]
'S'
>>> S[1]
'p'
In Python, we can also index backward, from the end—positive indexes count from the left, and negative indexes count back from the right:
>>> S[-1] # The last item from the end in S
'm'
>>> S[-2] # The second-to-last item from the end
'a'
The last item from the end in S # The second-to-last item from the end
Concatenation
first_name = "ada"
last_name = "lovelace"
full_name = first_name + " " + last_name
Repetition
>>> S * 8 # Repetition
'SpamSpamSpamSpamSpamSpamSpamSpam'
String Slices
The “slice” syntax is a handy way to refer to sub-parts of sequences – typically strings and lists. The slice s[start:end] is the elements beginning at start and extending up to but not including end. Suppose we have s = “Hello”
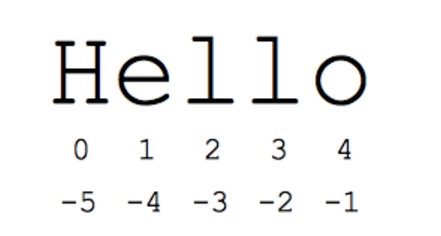
- s[1:4] is ’ell’ – chars starting at index 1 and extending up to but not including index 4
- s[1:] is ’ello’ – omitting either index defaults to the start or end of the string
- s[:] is ‘Hello’ – omitting both always gives us a copy of the whole thing (this is the pythonic way to copy a sequence like a string or list)
- s[1:100] is ’ello’ – an index that is too big is truncated down to the string length
The standard zero-based index numbers give easy access to chars near the start of the string. As an alternative, Python uses negative numbers to give easy access to the chars at the end of the string: s[-1] is the last char ‘o’, s[-2] is ’l’ the next-to-last char, and so on. Negative index numbers count back from the end of the string:
- s[-1] is ‘o’ – last char (1st from the end)
- s[-4] is ’e’ – 4th from the end
- s[:-3] is ‘He’ – going up to but not including the last 3 chars.
- s[-3:] is ’llo’ – starting with the 3rd char from the end and extending to the end of the string.
It is a neat truism of slices that for any index n, s[:n] + s[n:] == s. This works even for n negative or out of bounds. Or put another way s[:n] and s[n:] always partition the string into two string parts, conserving all the characters. As we’ll see in the list section later, slices work with lists too.
Immutability
Also notice in the prior examples that we were not changing the original string with any of the operations we ran on it. Every string operation is defined to produce a new string as its result, because strings are immutable in Python—they cannot be changed in place after they are created.
In other words, you can never overwrite the values of immutable objects. For example, you can’t change a string by assigning to one of its positions, but you can always build a new one and assign it to the same name. Because Python cleans up old objects as you go, this isn’t as inefficient as it may sound:
>>> S 'Spam'
>>> S[0] = 'z' # Immutable objects cannot be changed
...error text omitted...
TypeError: 'str' object does not support item assignment
>>> S = 'z' + S[1:] # But we can run expressions to make new objects
>>> S
'zpam'
Strictly speaking, you can change text-based data in place if you either expand it into a list of individual characters and join it back together with nothing between, or use the newer bytearray type available in Pythons 2.6, 3.0, and later:
>>> S = 'shrubbery'
>>> L = list(S)
>>> L
['s', 'h', 'r', 'u', 'b', 'b', 'e', 'r', 'y']
>>> L[1] = 'c'
>>> ''.join(L)
'scrubbery'
String Methods
- s.lower(), s.upper() – returns the lowercase or uppercase version of the string
- s.strip() – returns a string with whitespace removed from the start and end
- s.isalpha()/s.isdigit()/s.isspace()… – tests if all the string chars are in the various character classes
- s.startswith(‘other’), s.endswith(‘other’) – tests if the string starts or ends with the given other string
- s.find(‘other’) – searches for the given other string (not a regular expression) within s, and returns the first index where it begins or -1 if not found
- s.replace(‘old’, ’new’) – returns a string where all occurrences of ‘old’ have been replaced by ’new’
- s.split(‘delim’) – returns a list of substrings separated by the given delimiter. The delimiter is not a regular expression, it’s just text. ‘aaa,bbb,ccc’.split(’,’) -> [‘aaa’, ‘bbb’, ‘ccc’]. As a convenient special case s.split() (with no arguments) splits on all whitespace chars.
- s.join(list) – opposite of split(), joins the elements in the given list together using the string as the delimiter. e.g. ‘—’.join([‘aaa’, ‘bbb’, ‘ccc’]) -> aaa—bbb—ccc
title() - Changing case in a String
name = "ada lovelace"
print(name.title()) #Ada Lovelace
title() displays each word in titlecase, where each word begins with a capital letter. This is useful because you’ll often want to think of a name as a piece of information. For example, you might want your program to recognize the input values Ada, ADA, and ada as the same name, and display all of them as Ada.
Several other useful methods are available for dealing with case as well. For example, you can change a string to all uppercase or all lowercase letters like this:
name = "Ada Lovelace"
print(name.upper()) #ADA LOVELACE
print(name.lower()) #ada lovelace
Adding Whitespace to Strings with Tabs or Newlines
To add a tab to your text, use the character combination \t as shown at u:
>>> print("Python")
Python
>>> print("\tPython")
Python
To add a newline in a string, use the character combination \n:
>>> print("Languages:\nPython\nC\nJavaScript")
Languages:
Python
C
JavaScript
strip() \ lstrip() \ rstrip() - Stripping Whitespace
Python can look for extra whitespace on the right and left sides of a string. To ensure that no whitespace exists at the right end of a string, use the rstrip() method.
>>> favorite_language = ' python '
>>> favorite_language
'python '
>>> favorite_language.rstrip()
'python'
>>> favorite_language.lstrip()
'python '
>>> favorite_language.strip()
'python'
Avoiding Type Errors with the str() Function
Often, you’ll want to use a variable’s value within a message. For example, say you want to wish someone a happy birthday. You might write code like this:
age = 23 message = "Happy " + age + "rd Birthday!"
print(message)
You might expect this code to print the simple birthday greeting, Happy 23rd birthday! But if you run this code, you’ll see that it generates an error:
Traceback (most recent call last):
File "birthday.py", line 2, in <module>
message = "Happy " + age + "rd Birthday!"
TypeError: Can't convert 'int' object to str implicitly
When you use integers within strings like this, you need to specify explicitly that you want Python to use the integer as a string of characters. You can do this by wrapping the variable in the str() function, which tells Python to represent non-string values as strings:
age = 23 message = "Happy " + str(age) + "rd Birthday!"
print(message)
find()
the string find method is the basic substring search operation (it returns the offset of the passed-in substring, or −1 if it is not present), and the string replace method performs global searches and replacements; both act on the subject that they are attached to and called from:
>>> S = 'Spam'
>>> S.find('pa')
1
>>> S
'Spam'
>>> S.replace('pa', 'XYZ')
'SXYZm'
>>> S
'Spam'
split()
split() splits a string into substrings on a delimiter (handy as a simple form of parsing), perform case conversions, test the content of the string (digits, letters, and so on), and strip whitespace characters off the ends of the string:
>>> line = 'aaa,bbb,ccccc,dd'
>>> line.split(',') # Split on a delimiter into a list of substrings
['aaa', 'bbb', 'ccccc', 'dd']
>>> S = 'spam'
>>> S.upper() # Upper- and lowercase conversions
'SPAM'
>>> S.isalpha() # Content tests: isalpha, isdigit, etc.
True
>>> line = 'aaa,bbb,ccccc,dd\n'
>>> line.rstrip() # Remove whitespace characters on the right side
'aaa,bbb,ccccc,dd'
>>> line.rstrip().split(',') # Combine two operations
['aaa', 'bbb', 'ccccc', 'dd']
built-in dir function
This function lists variables assigned in the caller’s scope when called with no argument; more usefully, it returns a list of all the attributes available for any object passed to it. Because methods are function attributes, they will show up in this list. Assuming S is still the string, here are its attributes on Python 3.3 (Python 2.X varies slightly):
>>> dir(S) ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
You probably won’t care about the names with double underscores in this list—they represent the implementation of the string object and are available to support customization. The add method of strings, for example, is what really performs concatenation; Python maps the first of the following to the second internally, though you shouldn’t usually use the second form yourself (it’s less intuitive, and might even run slower):
>>> S + 'NI!'
'spamNI!'
>>> S.__add__('NI!')
'spamNI!'
Unicode Strings
Python’s strings also come with full Unicode support required for processing text in internationalized character sets. Characters in the Japanese and Russian alphabets, for example, are outside the ASCII set. Such non-ASCII text can show up in web pages, emails, GUIs, JSON, XML, or elsewhere.
>>> 'sp\xc4m' # 3.X: normal str strings are Unicode text
'spÄm'
# b'...' represents this is bytes and \x represents this is a hexadecimal
>>> b'a\x01c' # bytes strings are byte-based data
b'a\x01c'
# u'...' represents this is an Unicode string and \u... represents this is a Unicode encode
>>>U = u'sp\u00c4m' # Unicode strings in 2.X and 3.3+
String backslash characters

Raw Strings Suppress Escapes
This is just the sort of thing that raw strings are useful for. If the letter r (uppercase or lowercase) appears just before the opening quote of a string, it turns off the escape mechanism. The result is that Python retains your backslashes literally, exactly as you type them. Therefore, to fix the filename problem, just remember to add the letter r on Windows:
myfile = open(r'C:\new\text.dat', 'w')
Alternatively, because two backslashes are really an escape sequence for one backslash, you can keep your backslashes by simply doubling them up:
myfile = open('C:\new\text.dat', 'w')
Reference
- Learning Python
- Python Crash Course (2nd Edition) : A Hands-On, Project-Based Introduction to Programming