Knowledge
Refer to https://swsmile.info/post/data-structure-heap/
面试中碰到的
The minimum total weight of chocolates after d days
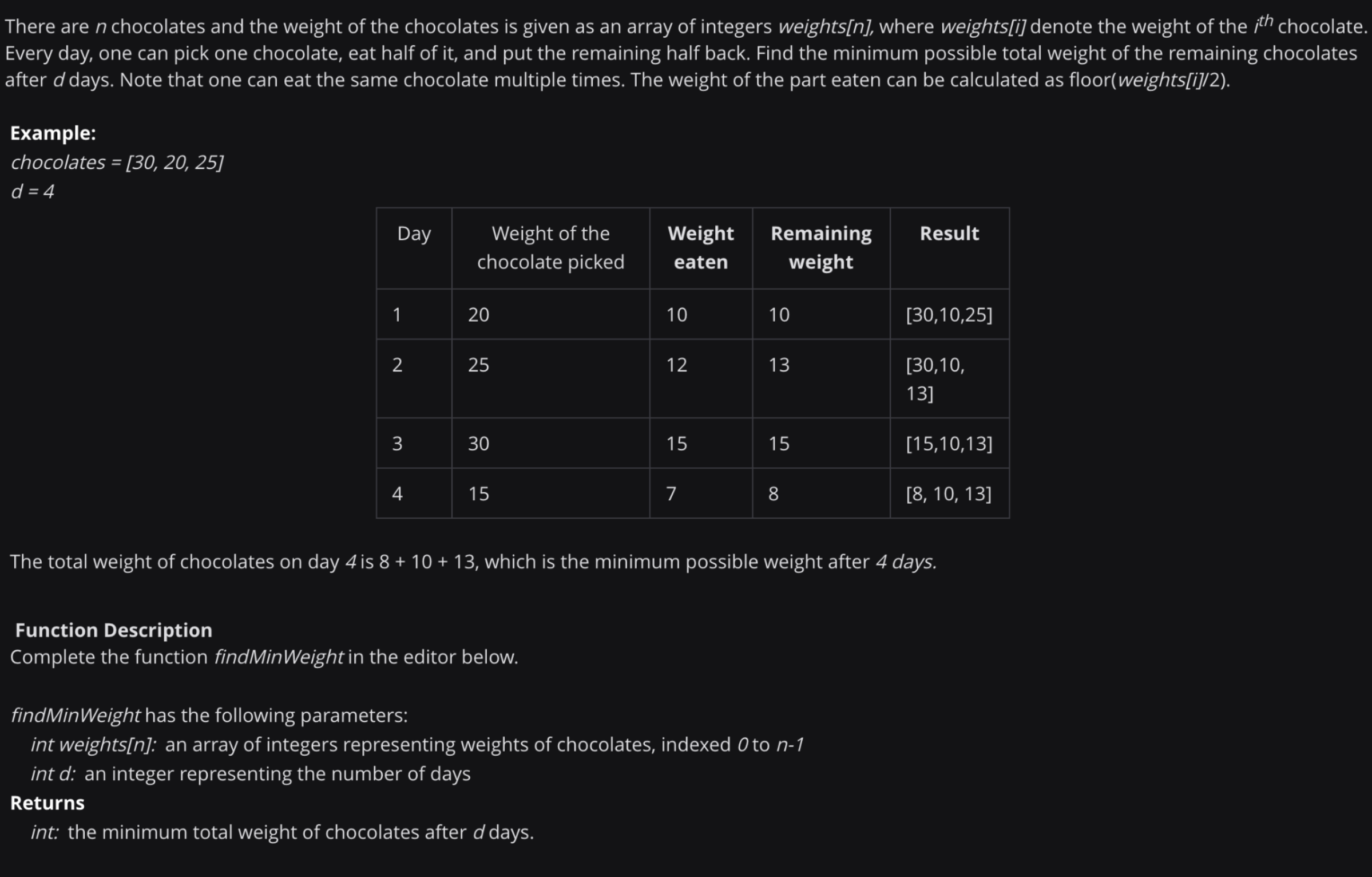
from typing import List
import heapq
def findMinWeight(weights: List[int], d: int) -> int:
"""
Find the minimum total weight of chocolates after d days.
Parameters:
weights (list of int): The weights of each chocolate.
d (int): The number of days.
Returns:
int: The minimum total weight of chocolates after d days.
"""
# Convert the list of chocolate weights into a max-heap.
# Python's heapq module implements a min-heap, so we store negative values
# to simulate a max-heap.
max_heap = [-w for w in weights]
heapq.heapify(max_heap) # time: O(n)
# Each day, eat half of the heaviest chocolate.
for _ in range(d): # time: O(dlogn)
# Remove the heaviest chocolate, eat half of it, and put back the rest.
heaviest = -heapq.heappop(max_heap) # time: O(1)
eaten = heaviest // 2
remaining = heaviest - eaten
# Add the remaining part back to the heap.
heapq.heappush(max_heap, -remaining) # time: O(logn)
# The total weight is the sum of the negatives of the max-heap values.
total_weight = -sum(max_heap) # time: O(n)
return total_weight
# Example usage:
chocolates = [30, 20, 25]
days = 4
findMinWeight(chocolates, days)
解析
215. Kth Largest Element in an Array
- quick select:如果能保证
p 左边的元素们都小于或等于p 指向的元素,且p 指向的元素小于p 右边的元素们。且 p 右边有 k-1 个元素,则 p 一定指向 第k大的元素
# Sort
# - time: O(nlog(n))
# - space: O(1) or O(n) depending on the sorting algorithm.
def findKthLargest(self, nums: List[int], k: int) -> int:
nums.sort()
return nums[len(nums) - k]
# min-heap
# - time: O((n-k)logn)
# - space: O(1)
def findKthLargest(self, nums: List[int], k: int) -> int:
heapq.heapify(nums) # time: O(n)
while len(nums) > k: # time: O((n-k)logn)
heapq.heappop(nums)
return heapq.heappop(nums)
# min-heap
# - time: O(n + klogn)
# - space: O(1)
def findKthLargest(self, nums: List[int], k: int) -> int:
for i in range(len(nums)): # time: O(n)
nums[i] = -nums[i]
heapq.heapify(nums) # time: O(n)
while k > 1:
heapq.heappop(nums)
k -= 1
return -nums[0]
# QuickSelect (like quick sort) - myself1,提交会超时
# Time Complexity:
# - Best Case: O(n)
# - Average Case: O(n),因为 n + n/2 + n/4 +... = 2n -> O(n),即每做完一次 partition,长度都会少一半
# - Worst Case: O(n^2), 如果是 [1,2,3,4,5,6],每做完一次 partition 会变成 [1,2,3,4,5], [1,2,3,4] ... -> 所以是O(n^2)
# Space Complexity: O(n) # 算上递归使用的调用栈
def findKthLargest(self, nums, k):
"""
:type nums: List[int]
:type k: int
:rtype: int
"""
def quickSelect(l, r):
pivotIdx = r # Just randomly choose a pivot. In this case, I choose the rightmost element as the pivot
pivot = nums[pivotIdx]
# p is the pointer
p = l
for i in range(l, r): # [l, r] 表示需要被进行 partition 的范围
if nums[i] <= pivot:
# 把 <= pivot 的元素,都放到 p 索引的左边
nums[i], nums[p] = nums[p], nums[i]
p += 1
# 把 pivot 对应的元素(nums[pivotIdx])和 p 指向的元素交换,以使得在 p 左边的元素都比 p 对应的元素小或等于,而且 p 右边的元素对比 p 对应的元素大
# nums = [3,2,1,5,6,4], k = 2 -> nums = [3,2,1,4 (p),6,5], 即 4 左边的元素都 <= 4,4 右边的元素都 > 4。后续继续去处理 [6, 5]
nums[pivotIdx], nums[p] = nums[p], nums[pivotIdx]
if p == len(nums) - k:
# 这时,在 p 左边的元素都比 p 对应的元素小或等于,而且 p 右边的元素都比 p 对应的元素大。所以直接得出答案
return nums[p]
elif p < len(nums) - k:
# 这时,说明在 p 右边的元素都比 p 对应的元素大,而要找的第 k 大的元素在 p 右边,因而要对 p 右边的元素们进行 partition,所以 left = p + 1
return quickSelect(p + 1, r)
else:
return quickSelect(l, p - 1)
return quickSelect(0, len(nums) - 1)
# QuickSelect (like quick sort) - myself2,提交会超时
# Time Complexity:
# - Best Case: O(n)
# - Average Case: O(n),因为 n + n/2 + n/4 +... = 2n -> O(n),即每做完一次 partition,长度都会少一半
# - Worst Case: O(n^2), 如果是 [1,2,3,4,5,6],每做完一次 partition 会变成 [1,2,3,4,5], [1,2,3,4] ... -> 所以是O(n^2)
# Space Complexity: O(n) # 算上递归使用的调用栈
def findKthLargest(self, nums, k):
"""
:type nums: List[int]
:type k: int
:rtype: int
"""
def partition(l, r):
pivotIdx = r # Just randomly choose a pivot. In this case, I choose the rightmost element as the pivot
pivot = nums[pivotIdx]
# p is the pointer
p = l
for i in range(l, r): # [l, r] 表示需要被进行 partition 的范围
if nums[i] <= pivot:
# 把 <= pivot 的元素,都放到 p 索引的左边
nums[i], nums[p] = nums[p], nums[i]
p += 1
# 把 pivot 对应的元素(nums[pivotIdx])和 p 指向的元素交换,以使得在 p 左边的元素都比 p 对应的元素小或等于,而且 p 右边的元素对比 p 对应的元素大
# nums = [3,2,1,5,6,4], k = 2 -> nums = [3,2,1,4 (p),6,5], 即 4 左边的元素都 <= 4,4 右边的元素都 > 4。后续继续去处理 [6, 5]
nums[pivotIdx], nums[p] = nums[p], nums[pivotIdx]
return p
l, r = 0, len(nums) - 1
while l < r:
p = partition(l, r)
if p == len(nums) - k:
# 这时,在 p 左边的元素都比 p 对应的元素小或等于,而且 p 右边的元素都比 p 对应的元素大。所以直接得出答案
break # 不能直接在这 return,因为比如 [1], k = 1 的情况
elif p < len(nums) - k:
# 这时,说明在 p 右边的元素都比 p 对应的元素大,而要找的第 k 大的元素在 p 右边,因而要对 p 右边的元素们进行 partition,所以 left = p + 1
l = p + 1
else:
r = p - 1
return nums[len(nums) - k]
# QuickSelect (like quick sort) - optimal
# Time Complexity:
# - Best Case: O(n)
# - Average Case: O(n),因为 n + n/2 + n/4 +... = 2n -> O(n)
# - Worst Case: O(n^2), 如果是 [1,2,3,4,5,6],每次做完会变成 [1,2,3,4,5], [1,2,3,4] ... -> 所以是O(n^2)
# Space Complexity: O(1)
def partition(self, nums: List[int], left: int, right: int) -> int:
mid = (left + right) >> 1
nums[mid], nums[left + 1] = nums[left + 1], nums[mid]
if nums[left] < nums[right]:
nums[left], nums[right] = nums[right], nums[left]
if nums[left + 1] < nums[right]:
nums[left + 1], nums[right] = nums[right], nums[left + 1]
if nums[left] < nums[left + 1]:
nums[left], nums[left + 1] = nums[left + 1], nums[left]
pivot = nums[left + 1]
i = left + 1
j = right
while True:
while True:
i += 1
if not nums[i] > pivot:
break
while True:
j -= 1
if not nums[j] < pivot:
break
if i > j:
break
nums[i], nums[j] = nums[j], nums[i]
nums[left + 1], nums[j] = nums[j], nums[left + 1]
return j
def quickSelect(self, nums: List[int], k: int) -> int:
left = 0
right = len(nums) - 1
while True:
if right <= left + 1:
if right == left + 1 and nums[right] > nums[left]:
nums[left], nums[right] = nums[right], nums[left]
return nums[k]
j = self.partition(nums, left, right)
if j >= k:
right = j - 1
if j <= k:
left = j + 1
def findKthLargest(self, nums: List[int], k: int) -> int:
return self.quickSelect(nums, k - 1)
ref
- https://www.youtube.com/watch?v=XEmy13g1Qxc
- https://neetcode.io/problems/kth-largest-integer-in-a-stream
355. Design Twitter
- we need a
countto indicate the creat_time of a tweet - self.userId2Tweets records the tweets that a user posts with [self.count, tweetId]
- Every time an user posts a tweet, we are gonna append [self.count, tweetId] to self.userId2Tweets
- and then we could get the latest tweet of this user by index = len(self.userId2Tweets[userId]) -1, count, tweetId = self.userId2Tweets[userId][index]
- we could for-loop all followers of an user, and get their latest tweets
- and then heapify them
- If less than 10, get the previous tweets of the current tweets, until reaching 10.
- and then we could get the latest tweet of this user by index = len(self.userId2Tweets[userId]) -1, count, tweetId = self.userId2Tweets[userId][index]
class Twitter:
def __init__(self):
self.count = 0
self.tweetMap = defaultdict(list) # userId -> list of [count, tweetId]
self.followMap = defaultdict(set) # userId -> set of followeeIds
def postTweet(self, userId: int, tweetId: int) -> None:
self.tweetMap[userId].append([self.count, tweetId])
self.count -= 1
def getNewsFeed(self, userId: int) -> List[int]:
res = []
minHeap = []
self.followMap[userId].add(userId)
for followeeId in self.followMap[userId]:
if followeeId in self.tweetMap:
index = len(self.tweetMap[followeeId]) - 1
count, tweetId = self.tweetMap[followeeId][index]
heapq.heappush(minHeap, [count, tweetId, followeeId, index - 1])
while minHeap and len(res) < 10:
count, tweetId, followeeId, index = heapq.heappop(minHeap)
res.append(tweetId)
if index >= 0:
count, tweetId = self.tweetMap[followeeId][index]
heapq.heappush(minHeap, [count, tweetId, followeeId, index - 1])
return res
def follow(self, followerId: int, followeeId: int) -> None:
self.followMap[followerId].add(followeeId)
def unfollow(self, followerId: int, followeeId: int) -> None:
if followeeId in self.followMap[followerId]:
self.followMap[followerId].remove(followeeId)
ref
621. Task Scheduler
- we wanna compute the task which is the most frequently first, so that the ideal count may be as small as possible
- So we use a MinHeap to store the counts that every task needs to be computed
- After a task is computed, we add its count_to_compute into a queue with computable_until_when.
- After a computation, we check the queue to see whether there is a task which is computable
- if yes, pop it from the queue, and add it to the maxHeap
- If nothing in the maxHeap and nothing in the queue, it means that we finish everything
# maxHeap - myself
# - time: O(n*m), n is the size of tasks, and m is the idea time, since image we have [A, A, A, A] and n is 10, so we need n*m
# - space: o(1) # since we have at most 26 different characters, O(n0)
def leastInterval(self, tasks, n):
"""
:type tasks: List[str]
:type n: int
:rtype: int
"""
m = {}
for task in tasks:
m[task] = m.get(task, 0) + 1
minHeap = []
for count in m.values():
minHeap.append(-count)
heapq.heapify(minHeap)
stage = [] # 存储了被 complete 一次后的任务,[<还有多少次没完成>,<可以执行该任务的最小时刻>]
time = 0
# time: O(n*m), n is the size of tasks, and m is the cooldown time, since image we have [A, A, A, A] and n is 10, so we need n*m
while minHeap or stage:
if stage:
count, minTimestampToAdd = stage[0]
if minTimestampToAdd <= time: # 超过了 n,因而可以重新放入 heap,等待被重新执行了
stage.pop(0)
heapq.heappush(minHeap, -count)
if minHeap:
count = -heapq.heappop(minHeap)
count -= 1
if count > 0:
stage.append([count, n + time + 1])
time += 1
return time
# maxHeap - Needcode
# - time: O(n*m), n is the size of tasks, and m is the idea time, since image we have [A, A, A, A] and n is 10, so we need n*m
# - space: o(1) # since we have at most 26 different characters, O(n0)
def leastInterval(self, tasks: List[str], n: int) -> int:
m = {} # space: O(n)
for task in tasks: # time: O(n)
if task not in m:
m[task] = 1
else:
m[task] += 1
frequencies = [] # space: O(n)
for frequency in m.values(): # time: O(n)
frequencies.append(-frequency)
heapq.heapify(frequencies)
time = 0
queue = [] # (count_to_compute, computable_until_when) # space: O(n)
while frequencies or queue: # time: O(n*m), n is the size of tasks, and m is the idea time, since image we have [A, A, A, A] and n is 10, so we need n*m
time += 1
if len(frequencies) > 0:
count_to_compute = heapq.heappop(frequencies)
count_to_compute += 1
if count_to_compute < 0:
queue.append((count_to_compute, time + n))
if queue:
frequency, computable_until_when = queue[0]
if computable_until_when <= time:
queue.pop(0)
heapq.heappush(frequencies, frequency)
return time
ref
703. Kth Largest Element in a Stream
- use min heap with the size of K to memorise the k largest elements
- 更像 medium
# brute force - sort
class KthLargest(object):
def __init__(self, k, nums):
"""
:type k: int
:type nums: List[int]
"""
self.k = k
nums.sort() # time: O(nlogn), space: O(1)/O(n)
if len(nums) > k:
nums = nums[len(nums) - k:] # 只取 从第 k 大元素到最大的元素,i.e., 比最k大元素还小的元素会被移除 # space: O(n-k)
self.arr = nums
# time: O(k), space: O(k)
def add(self, val):
"""
:type val: int
:rtype: int
"""
self.arr.append(val)
... # time: O(logk), space: O(1),用 binary search 找到要插入的位置
... # time: O(k), 插入元素
if len(self.arr) > self.k:
self.arr = self.arr[len(self.arr) - self.k:] # 取从第 k 大元素到最大的元素 # space: O(k), time: O(k)
return self.arr[len(self.arr) - self.k]
# priority queue/ min-heap
# - 我们可以使用一个大小为 k 的最小堆来存储前 k 大的元素,其中优先队列的队头为队列中最小的元素,也就是第 k 大的元素。
# - 在每次 add()的时候,将新元素 push() 到堆中,如果此时堆中的元素超过了 K,那么需要把堆中的最小元素(堆顶)pop()出来。
# - 此时堆中的最小元素(堆顶)就是整个数据流中的第 K 大元素。
# - 为什么使用小根堆?
# - 因为我们需要在堆中保留数据流中的前 K 大元素,使用小根堆能保证每次调用堆的 pop() 函数时,从堆中删除的是堆中的最小的元素(堆顶)。因为比该元素还小的元素,不会影响最后的结果
# - 为什么能保证堆顶元素是第 K 大元素?
# - 因为小根堆中保留的一直是堆中的前 K 大的元素,堆的大小是 K,所以堆顶元素是第 K 大元素。
class KthLargest(object):
# 初始化时间复杂度为:O(nlogk) ,其中 n 为初始化时 nums 的长度
# 空间复杂度:O(1),不包括 nums 本身占用的空间
def __init__(self, k, nums):
"""
:type k: int
:type nums: List[int]
"""
# minHeap with k Largest integer
self.k, self.minHeap = k, nums
heapq.heapify(self.minHeap) # minHeap with K largest elements, time: O(n)
# pop elements until k elements are left in the heap, time: O((n-k)logn),最多总共需要 pop n-k 次
# 为什么要pop:我们不 care 比 第k大元素 还小的元素,因为比该元素还小的元素,不会影响最后的结果
while len(self.minHeap) > k:
heapq.heappop(self.minHeap) # O(logn)
# 单次插入时间复杂度为:O(logk)
# 空间复杂度:O(k)。需要使用优先队列存储前 k 大的元素
def add(self, val):
"""
:type val: int
:rtype: int
"""
heapq.heappush(self.minHeap, val) # time: O(logk)
# 在每次 add() 的时候,将新元素 push() 到堆中,如果此时堆中的元素的数量超过了 K,那么需要把堆中的最小元素(堆顶)pop() 出来。因为我们不 care 比 第k大元素 还小的元素
if len(self.minHeap) > self.k: # only keep k elements in the list
heapq.heappop(self.minHeap) # time: O(logk)
return self.minHeap[0] # the smallest element of the heap is the kth largest element
ref
- https://www.youtube.com/watch?v=hOjcdrqMoQ8
- https://neetcode.io/problems/kth-largest-integer-in-a-stream
- https://leetcode.cn/problems/kth-largest-element-in-a-stream/solutions/600598/shu-ju-liu-zhong-de-di-k-da-yuan-su-by-l-woz8/
- https://leetcode.cn/problems/kth-largest-element-in-a-stream/solutions/600618/mian-shi-ti-jing-gao-jing-dian-topk-ben-u7w30/
973. K Closest Points to Origin
- Python uses the first element to sort
# sort
# - time: O(nlogn)
# - space: O(1) or O(n) depending on the sorting algorithm.
class Solution:
def kClosest(self, points: List[List[int]], k: int) -> List[List[int]]:
points.sort(key=lambda p: p[0]**2 + p[1]**2)
return points[:k]
# min-heap
# - time: O(n + klogn)
# - space: O(n)
class Solution:
def kClosest(self, points, k):
"""
:type points: List[List[int]]
:type k: int
:rtype: List[List[int]]
"""
minHeap = [] # space: O(n)
for x, y in points:
minHeap.append([x * x + y * y, x, y]) # Python uses the first element to conduct "heapify"
heapq.heapify(minHeap) # time: O(n)
res = []
while k > 0: # time: O(k)
v = heapq.heappop(minHeap) # time: O(logn)
res.append([v[1], v[2]])
k -= 1
return res
# quick select
# todo
# - time: O(n) in average case, O(n^2) in worst case
# - space: O(1)
def kClosest(self, points, k):
euclidean = lambda x: x[0] ** 2 + x[1] ** 2
def partition(l, r):
pivotIdx = r
pivotDist = euclidean(points[pivotIdx])
i = l
for j in range(l, r):
if euclidean(points[j]) <= pivotDist:
points[i], points[j] = points[j], points[i]
i += 1
points[i], points[r] = points[r], points[i]
return i
L, R = 0, len(points) - 1
pivot = len(points)
while pivot != k:
pivot = partition(L, R)
if pivot < k:
L = pivot + 1
else:
R = pivot - 1
return points[:k]
ref
1046. Last Stone Weight
- 因为Python里没有maxHeap,只有minHeap
- 所以可能把所有的元素都变成负数
# sort
# - time: O(n^2logn)
# - space: O(1) or O(n) depending on the sorting algorithm.
def lastStoneWeight(self, stones: List[int]) -> int:
while len(stones) > 1:
stones.sort()
cur = stones.pop() - stones.pop()
if cur:
stones.append(cur)
return stones[0] if stones else 0
# binary search
# - time: O(n^2)
# - space: O(1) or O(n) depending on the sorting algorithm.
def lastStoneWeight(self, stones: List[int]) -> int:
stones.sort()
n = len(stones)
while n > 1:
cur = stones.pop() - stones.pop()
n -= 2
if cur > 0:
l, r = 0, n
while l < r:
mid = (l + r) // 2
if stones[mid] < cur:
l = mid + 1
else:
r = mid
pos = l
n += 1
stones.append(0)
for i in range(n - 1, pos, -1):
stones[i] = stones[i - 1]
stones[pos] = cur
return stones[0] if n > 0 else 0
# heap
# - time: O(nlogn)
# - space: O(1)
class Solution(object):
def lastStoneWeight(self, stones):
"""
:type stones: List[int]
:rtype: int
"""
# By default, Python inits a min-heap
# maxHeap
for idx, stone in enumerate(stones):
stones[idx] = -stone
heapq.heapify(stones) # time: O(n)
while len(stones) > 1: # time: O(n)
largest = heapq.heappop(stones) # time: O(logn)
second = heapq.heappop(stones) # time: O(logn)
stone3 = abs(-largest - (-second))
heapq.heappush(stones, -stone3) # time: O(logn)
if not stones:
return 0
return -stones[0]
# bucket sort
class Solution(object):
# 没理解为什么time是 O(n+w)
# time: O(n+w), n is the length of the stones array and w is the maximum value in the stones array.
# space: O(w), w is the maximum value in the stones array.
def lastStoneWeight(self, stones):
"""
:type stones: List[int]
:rtype: int
"""
maxStone = max(stones)
buckets = [0] * (maxStone + 1) # space: O(w),w is the maximum value in the stones array.
for stone in stones: # time: O(n)
buckets[stone] += 1
first = maxStone
while first > 0: # time: O(w)
if buckets[first] % 2 == 0: # smash,因为含有偶数块重量为 first 的石头时,质量直接抵消了
first -= 1
continue
buckets[first] -= 1 # 取出重量为 first 的一块 stone
i = first
while i > 0 and buckets[i] == 0:
i -= 1
if i > 0: # 说明遇到了重量不为 0 数量的 bucket
second = i
buckets[second] -= 1 # 取出重量为 second 的一块 stone
buckets[first - second] += 1 # smash
# 不能直接 first = second,因为 first - second 可能比 second 大
first = max(first - second, second) # time: O(w) 因为最多每次 first 向右推 w
else:
return first
return 0
ref