Phantom Rows
The phantom reads anomaly is a special case of Non-repeatable reads when Transaction 1 repeats a ranged SELECT ... WHERE query and, between both operations, Transaction 2 creates new rows (i.e., INSERT) or deletes existing rows (i.e., DELETE) (in the target table) which fulfill that WHERE clause.
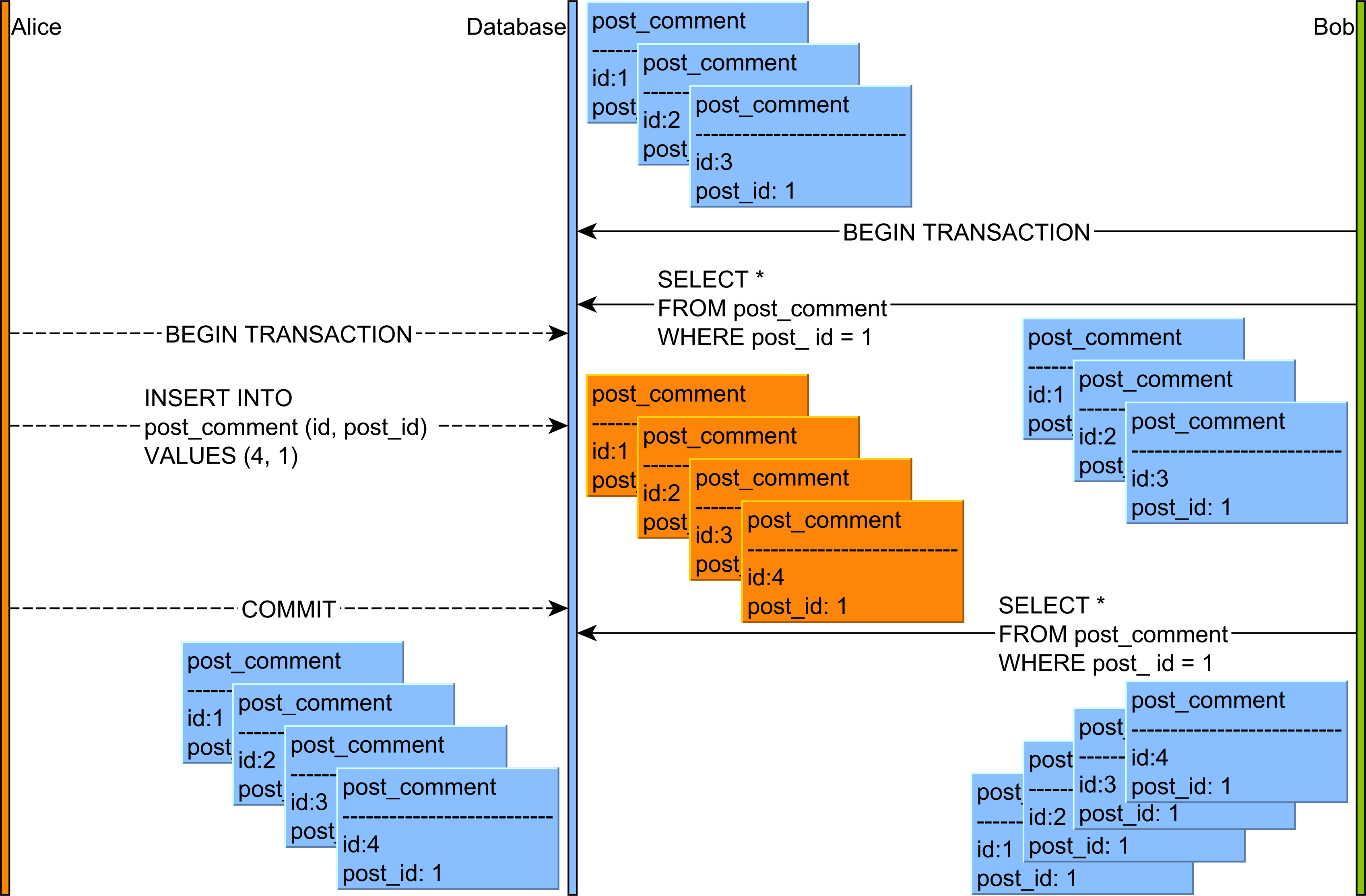
In the diagram above, the flow of statements goes like this:
- Alice and Bob start two database transactions.
- Bob’s reads all the
post_comment records associated with the post row with the identifier value of 1.
- Alice adds a new
post_comment record which is associated with the post row having the identifier value of 1.
- Alice commits her database transaction.
- If Bob’s re-reads the
post_comment records having the post_id column value equal to 1, he will observe a different version of this result set.
How to aviod Phantom Reads
If the highest level of isolation (i.e., SERIALIZABLE isolation level) were maintained, the same set of rows should be returned both times, and indeed that is what is mandated to occur in a database operating at the SERIALIZABLE isolation level. However, at the lesser isolation levels, a different set of rows may be returned the second time.
In the SERIALIZABLE isolation mode, Query 1 would result in all records with post_id =1 being locked, thus Query 2 would block until the first transaction was committed. In REPEATABLE READ mode, the range would not be locked, allowing the record to be inserted and the second execution of Query 1 to include the new row in its results.
How to prevent:
The 2PL-based Serializable isolation prevents Phantom Reads through the use of predicate locking while MVCC (Multi-Version Concurrency Control) database engines address the Phantom Read anomaly by returning consistent snapshots.
However, a concurrent transaction can still modify the range of records that was read previously. Even if the MVCC database engine introspects the transaction schedule, the outcome is not always the same as a 2PL-based implementation. One such example is when the second transaction issues an insert without reading the same range of records as the first transaction. In this particular use case, some MVCC database engines will not end up rolling back the first transaction.
...
