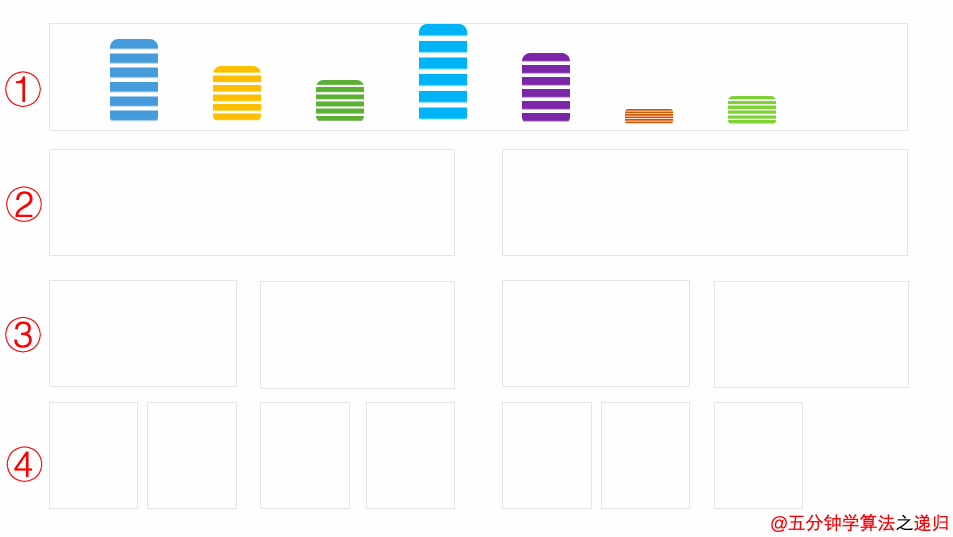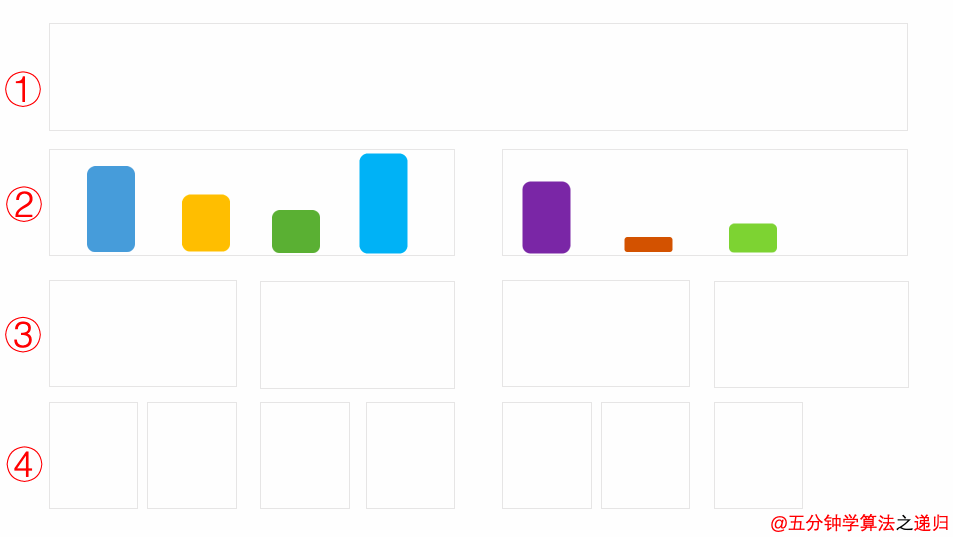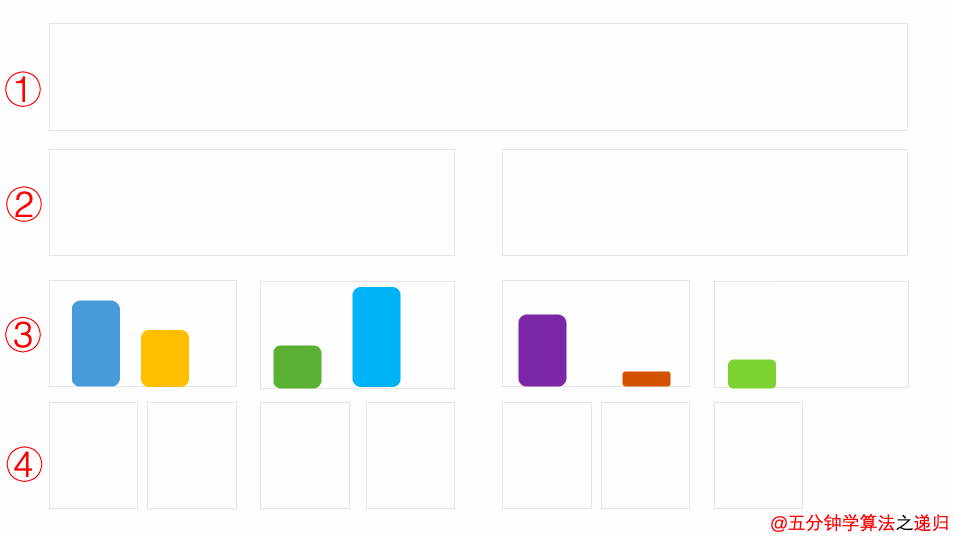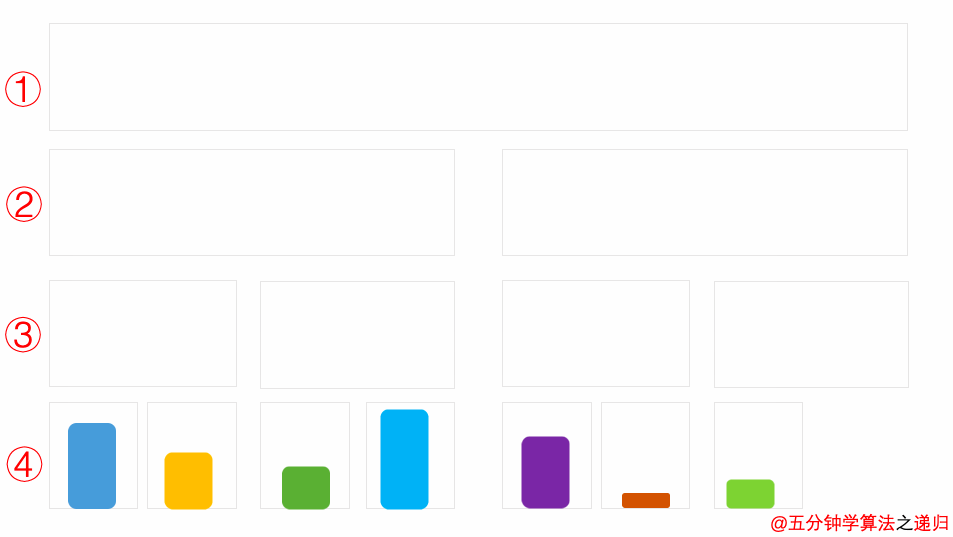
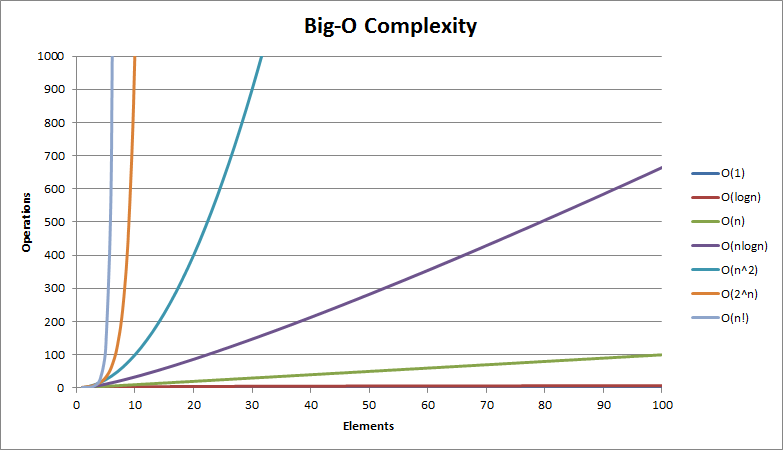
Background
这里来说明一下满二叉树(full binary tree)的概念与完全二叉树(complete binary tree)的概念。
满二叉树(Full Binary Tree)
A full binary tree is a binary tree in which all of the nodes have either 0 or 2 offspring. In other terms, a full binary tree is a binary tree in which all nodes, except the leaf nodes, have two offspring.
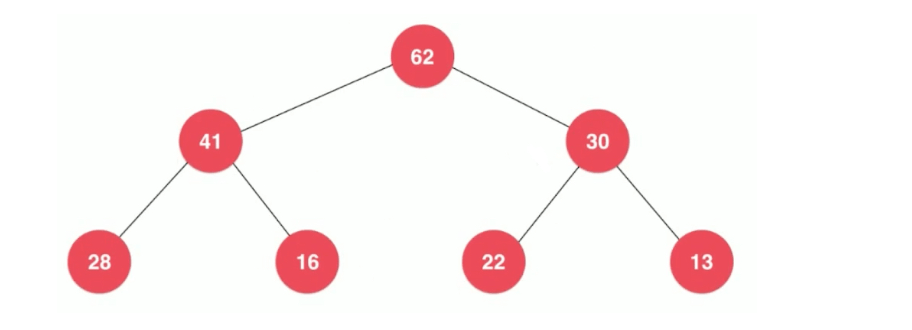
可以看出:满二叉树所有的节点都拥有左孩子,又拥有右孩子。
...