MapReduce
MapReduce 是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。说白了,Mapreduce 的原理就是一个归并排序。
适用范围:数据量大,但是数据种类小可以放入内存。
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。
MapReduce 模式
MapReduce 模式的主要思想是将自动分割要执行的问题 (例如程序)拆解成 Map(映射)和 Reduce(化简)的方式,如下图所示:
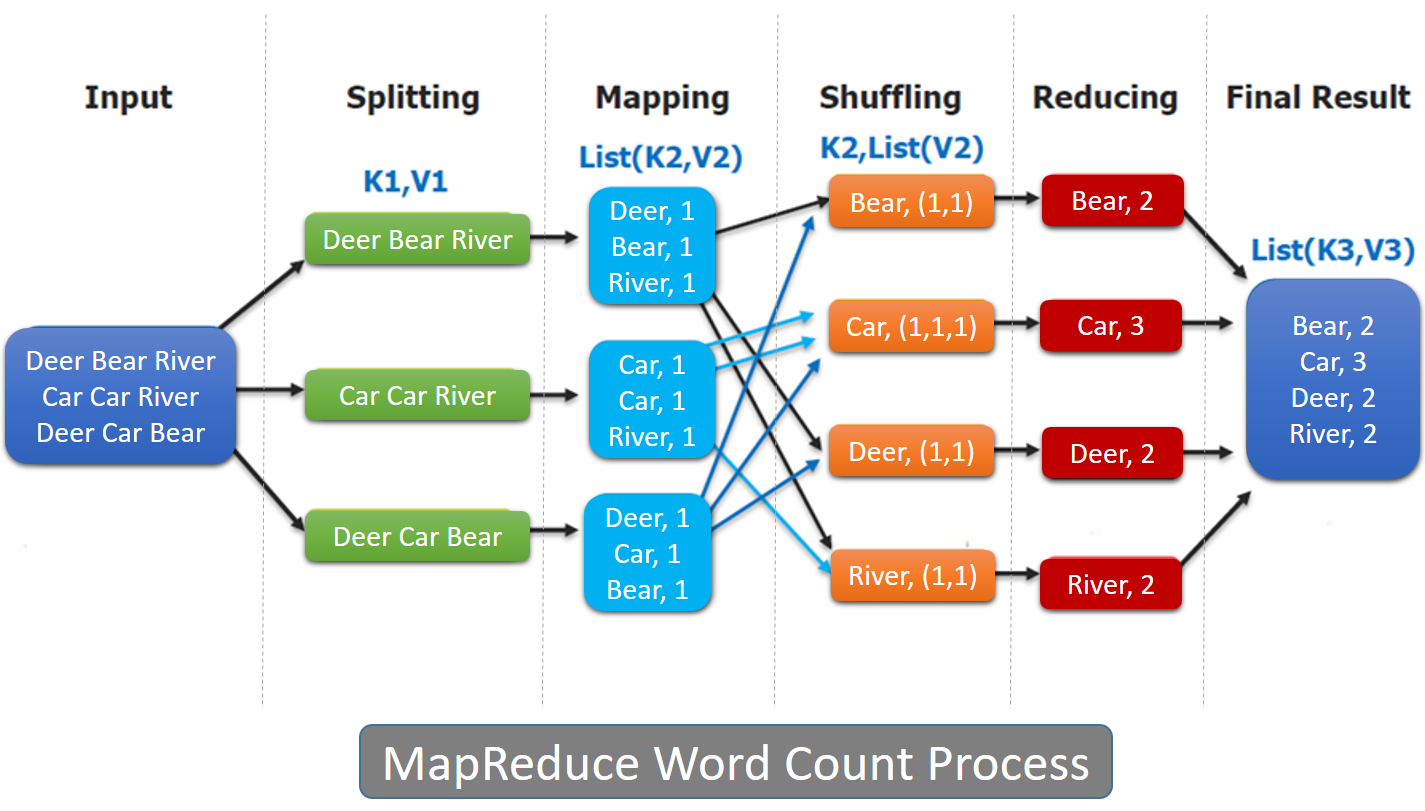
在数据被分割后通过 Map 函数的程序将数据映射成不同的区块,分配给计算机机群处理达到分 布式运算的效果,在通过 Reduce 函数的程序将结果汇整,从而输出开发者需要的结果。
MapReduce 借鉴了函数式程序设计语言的设计思想,其软件实现是指定一个 Map 函数,把键 值对(key/value)映射成新的键值对(key/value),形成一系列中间结果形式的 key/value 对,然后 把它们传给 Reduce(规约)函数,把具有相同中间形式 key 的 value 合并在一起。Map 和 Reduce函数具有一定的关联性。
MapReduce 致力于解决大规模数据处理的问题,因此在设计之初就考虑了数据的局部性原理, 利用局部性原理将整个问题分而治之。MapReduce 集群由普通 PC 机构成,为无共享式架构。 在处理之前,将数据集分布至各个节点。处理时,每个节点就近读取本地存储的数据处理(map), 将处理后的数据进行合并(combine)、排序(shuffle and sort)后再分发(至 reduce 节点), 避免了大量数据的传输,提高了处理效率。无共享式架构的另一个好处是配合复制(replication) 策略,集群可以具有良好的容错性,一部分节点的 down 机对集群的正常工作不会造成影响。
Reference
- 《Distributed Computing in Java 9》
- 《编程之法:面试和算法心得》