Background
文法定义(Grammar Definition)
风控策略表达式的语法到底是什么样的?也就是说 风控策略表达式这种DSL的语法结构是什么?
在学习形式语言或编译原理课程时,想必大家肯定接触过BNF(Backus-Naur Form),即巴科斯范式。巴科斯范式是以美国人巴科斯(Backus)和丹麦人诺尔(Naur)的名字命名的一种形式化的语法表示方法,是用来描述语法的一种形式体系,是一种典型的元语言。自从编程语言Algol 60(Naur,1960)使用BNF符号定义语法以来,这种符号规则体系被证明适合作为形式化编程语言的语法,之后人们也开始习惯于使用此类元语言去定义语言语法。
BNF元语言的典型表达形式如下:
<symbol> ::= expression
<symbol> ::= expression1 | expression2
- 这个式子左侧放在尖括号中的symbol是一个非终结符号,而expression这个表达式由一个或多个终结符号或非终结符号的序列组成,这个式子也被称为产生式(production)。
- 产生式中的“::=”这个符号含义是“被定义为”,左边的非终结符号可以被推导为右边的表达式,右边的表达式也可以归约为左边的非终结符号。
- 如果右侧有多种表达式形式可作为symbol的归约选择,可以使用”|”符号分隔。
- 从未出现在左边的符号是终结符号。另一方面,出现在左侧的符号为非终结符号,并且总是被包围在一对<>之间。
随着BNF的广泛应用,一些以简化BNF或特定应用为目的的扩展BNF元语言被创建出来,其中典型的包括EBNF、ABNF等。
我们来定义一下能描述背景的例子的文法:
/* 关键字 */
USER: 'user';
CONTAINS: 'contains';
AND: 'and';
OR: 'or';
/* 符号和运算符 */
DOUBLE_QUOTE: '"';
COMMA: ',';
DOT: '.';
LT: '<';
LE: '<=';
GT: '>';
GE: '>=';
EQ: '==';
NE: '!=';
DOLLAR: '$';
L_PAREN: '(';
R_PAREN: ')';
L_CURLY: '{';
R_CURLY: '}';
L_BRACKET: '[';
R_BRACKET: ']';
/* 标识符 */
ID: [a-zA-Z][a-zA-Z0-9]+;
/* 无符号整数和字符串的字面量 */
NUM_LIT: ('0' | [1-9] ('_'? [0-9])*);
STR_LIT: DOUBLE_QUOTE ~["\\]* DOUBLE_QUOTE;
以上为词法规则,全部使用大写表示,定义了所有的终结符。
/* 规定一个文件/一段文本只能有一个表达式 */
fullExpression: expression EOF;
/* 表达式 */
expression:
L_PAREN expression R_PAREN # ParenExpression
| expression op = (EQ | NE | LT | GT | LE | GE) expression # CompareExpression
| expression CONTAINS expression # SetExpression
| expression op = (AND | OR) expression # LogicExpression
| (constant | variable) # AtomExpression;
/* 用户属性 */
userProp: ID (L_PAREN expression (COMMA expression)* R_PAREN)?;
/* 表达式中的常量 */
constant: STR_LIT | NUM_LIT;
/* 表达式中的变量 */
variable:
DOLLAR L_CURLY ID R_CURLY
| USER DOT userProp;
以上为语法规则,用小驼峰表示,定义了非终结符
这样一段文法即可准确地描述风控策略表达式的语法规则。然而,这么描述有什么用呢?对于人来说,还是用自然语言描述语法规则更容易理解也更易用;所以,这段描述是给机器看的,接下来,就到 ANTLR4 上场了。
ANTLR (ANother Tool for Language Recognition)
ANTLR is a powerful parser generator that you can use to read, process, execute, or translate structured text or binary files.
ANTLR is really two things: a tool written in Java that translates your grammar to a parser/lexer in Java (or other target language) and the runtime library needed by the generated parsers/lexers.
能做什么
已目前对 ANTLR 的了解,它能做的事情真的很多,稍微梳理一些我的思路。
-
代码翻译器: 开发一个把 Java 代码翻译成 Python 的工具
-
格式转换工具:如JSON、YAML、XML等互相转换
-
做代码分析的工具: 写一个工具来进行代码规范的检查,快速检查项目不符合编码规范的代码
-
快速重构项目代码: ANTLR 可以重写输入流,在项目中需要做一些重构时,写一个快速自动重构的工具
我相信 ANTLR 能做的事情还很多,发挥一下脑洞, 是不是可以基于 JAVA 开发一种自己的程序语言,把自己定义的语法翻译成 JAVA 最终在 JVM 中执行。
Usages
Software built using ANTLR includes:
- Groovy.
- Jython.
- Hibernate
- OpenJDK Compiler Grammar project experimental version of the javac compiler based upon a grammar written in ANTLR.
- Apex, Salesforce.com’s programming language.
- The expression evaluator in Numbers, Apple’s spreadsheet.
- Twitter’s search query language.
- Weblogic server.
- Apache Cassandra.
- Processing.[citation needed]
- JabRef.[citation needed]
- Trino (SQL query engine)
- Presto (SQL query engine)
- MySQL Workbench
实现
本节使用 ANTLR4 实现背景的例子的语法解析执行。ANTLR4 类似 YACC,是一种解析器生成器,于构建语言识别工具,如编译器、解释器和数据格式转换器。ANTLR4 可以处理复杂的语法,生成能够解析特定语言或格式的代码。
ANTLR4 可以帮我们完成词法分析和语法分析,因此我们只需要完成文法定义和语义分析即可。
环境准备
使用 pip3 安装 antlr4-tools
python3 -m venv .
source bin/activate
pip3 install antlr4-tools # 运行 antlr4 以验证是否安装成功
在 Go 项目中添加依赖
go get github.com/ANTLR4-go/antlr/v4
一般把这两个文件放在项目的 parser 目录,lexer 表示词法规则,parser 表示语法规则(放到一个文件中也可以)。
在项目根目录使用刚刚安装的 antlr4 生成词法分析器和语法分析器代码:
antlr -Dlanguage=Go parser/*.g4 -visitor
-Dlanguage=Go 是生成 Go 的目标源码,-visitor 是生成访问者模式的代码(语法树有两种访问模式,监听和访问,这个场景适合使用访问者)。生成的代码主要有:
_lexer.go词法分析器_parser.go语法分析器_listener.go默认的监听者实现,其各个方法为空,不做任何事_visitor.go默认的访问者实现,其各个方法为空,不做任何事
Demo
Let’s play with a simple grammar:
grammar Expr;
prog: expr EOF ;
expr: expr ('*'|'/') expr // means that * and / will have a higher priority than + and -
| expr ('+'|'-') expr
| INT
| '(' expr ')'
;
NEWLINE : [\r\n]+ -> skip;
INT : [0-9]+ ;
To parse and get the parse tree in text form, use:
$ antlr4-parse Expr.g4 prog -tree
10+20*30
^D
(prog:1 (expr:2 (expr:3 10) + (expr:1 (expr:3 20) * (expr:3 30))) <EOF>)
Here’s how to get the tokens and trace through the parse:
$ antlr4-parse Expr.g4 prog -tokens -trace
10+20*30
^D
[@0,0:1='10',<INT>,1:0]
[@1,2:2='+',<'+'>,1:2]
[@2,3:4='20',<INT>,1:3]
[@3,5:5='*',<'*'>,1:5]
[@4,6:7='30',<INT>,1:6]
[@5,9:8='<EOF>',<EOF>,2:0]
enter prog, LT(1)=10
enter expr, LT(1)=10
consume [@0,0:1='10',<8>,1:0] rule expr
enter expr, LT(1)=+
consume [@1,2:2='+',<3>,1:2] rule expr
enter expr, LT(1)=20
consume [@2,3:4='20',<8>,1:3] rule expr
enter expr, LT(1)=*
consume [@3,5:5='*',<1>,1:5] rule expr
enter expr, LT(1)=30
consume [@4,6:7='30',<8>,1:6] rule expr
exit expr, LT(1)=<EOF>
exit expr, LT(1)=<EOF>
exit expr, LT(1)=<EOF>
consume [@5,9:8='<EOF>',<-1>,2:0] rule prog
exit prog, LT(1)=<EOF>
Here’s how to get a visual tree view:
$ antlr4-parse Expr.g4 prog -gui
10+20*30
^D
The following will pop up in a Java-based GUI window:

Generating parser code
The previous section used a built-in ANTLR interpreter but typically you will ask ANTLR to generate code in the language used by your project (there are about 10 languages to choose from as of 4.11). Here’s how to generate Java code from a grammar:
$ antlr4 Expr.g4
$ ls Expr*.java
ExprBaseListener.java ExprLexer.java ExprListener.java ExprParser.java
And, here’s how to generate C++ code from the same grammar:
$ antlr4 -Dlanguage=Cpp Expr.g4
$ ls Expr*.cpp Expr*.h
ExprBaseListener.cpp ExprLexer.cpp ExprListener.cpp ExprParser.cpp
ExprBaseListener.h ExprLexer.h ExprListener.h ExprParser.h
Tools
- http://lab.antlr.org/
- there is a large collection of grammars for v4 at github: https://github.com/antlr/grammars-v4
Terms
= += -= // assignmentOperator
// Constant
// StringLiteral
+ - ! ~ & // unaryOperator(一元运算符)
// Multivariate operator(多元运算符)
int long float double char short // typeSpecifier
int i = 0; // declaration
// externalDeclaration
// functionDefinition
i // primaryExpression
i <= LAST// relationalExpression
"sum = %d\n", sum // argumentExpressionList
// logicalOrExpression
// logicalAndExpression
<< >> // shiftExpression(移位表达式)
== != // equalityExpression
.. & .. // andExpression
.. && .. // logicalAndExpression
.. || .. // logicalOrExpression
stat: expr '=' expr ';' // e.g., x=y; or x=f(x);
| expr ';' // e.g., f(x); or f(g(x));
;
expr: expr '*' expr
| expr '+' expr
| expr '(' expr ')' // f(x)
| id
;
ANTLR 语法
Grammar Lexicon(词汇语法)
Identifiers
Token names always start with a capital letter and so do lexer rules as defined by Java’s Character.isUpperCase method. Parser rule names always start with a lowercase letter (those that fail Character.isUpperCase). The initial character can be followed by uppercase and lowercase letters, digits, and underscores. Here are some sample names:
ID, LPAREN, RIGHT_CURLY // token names/lexer rules
expr, simpleDeclarator, d2, header_file // parser rule names
Keywords
Here’s a list of the reserved words in ANTLR grammars:
import, fragment, lexer, parser, grammar, returns,
locals, throws, catch, finally, mode, options, tokens
Also, although it is not a keyword, do not use the word rule as a rule name. Further, do not use any keyword of the target language as a token, label, or rule name. For example, rule if would result in a generated function called if. That would not compile obviously.
Grammar Structure
A grammar is essentially a grammar declaration followed by a list of rules, but has the general form:
/** Optional javadoc style comment */
grammar Name; ①
options {...}
import ... ;
tokens {...}
channels {...} // lexer only
@actionName {...}
rule1 // parser and lexer rules, possibly intermingled
...
ruleN
The file name containing grammar X must be called X.g4. You can specify options, imports, token specifications, and actions in any order. There can be at most one each of options, imports, and token specifications. All of those elements are optional except for the header ① and at least one rule. Rules take the basic form:
ruleName : alternative1 | ... | alternativeN ;
Parser rule names must start with a lowercase letter and lexer rules must start with a capital letter.
Misc
left recursion
- direct left recursion
- indirect left recursion
ref
Context-free grammar
ref
其他的词法+语法解析器
市面上可用于自动生成lexer和parser代码的工具有很多种
JavaCC
JavaCC,即Java Cmopiler Compiler,为了简化基于Java语言的词法分析器或者语法分析器的开发,Sun公司的开发人员开发了JavaCC(Java Compiler Compiler)。JavaCC是一个基于Java语言的分析器的自动生成器。用户只要按照JavaCC的语法规范编写JavaCC的源文件,然后使用JavaCC的编译器编译,就能够生成基于Java语言的某种特定语言的分析器。JavaCC已经成为最受欢迎的Java解析器创建工具。
YACC
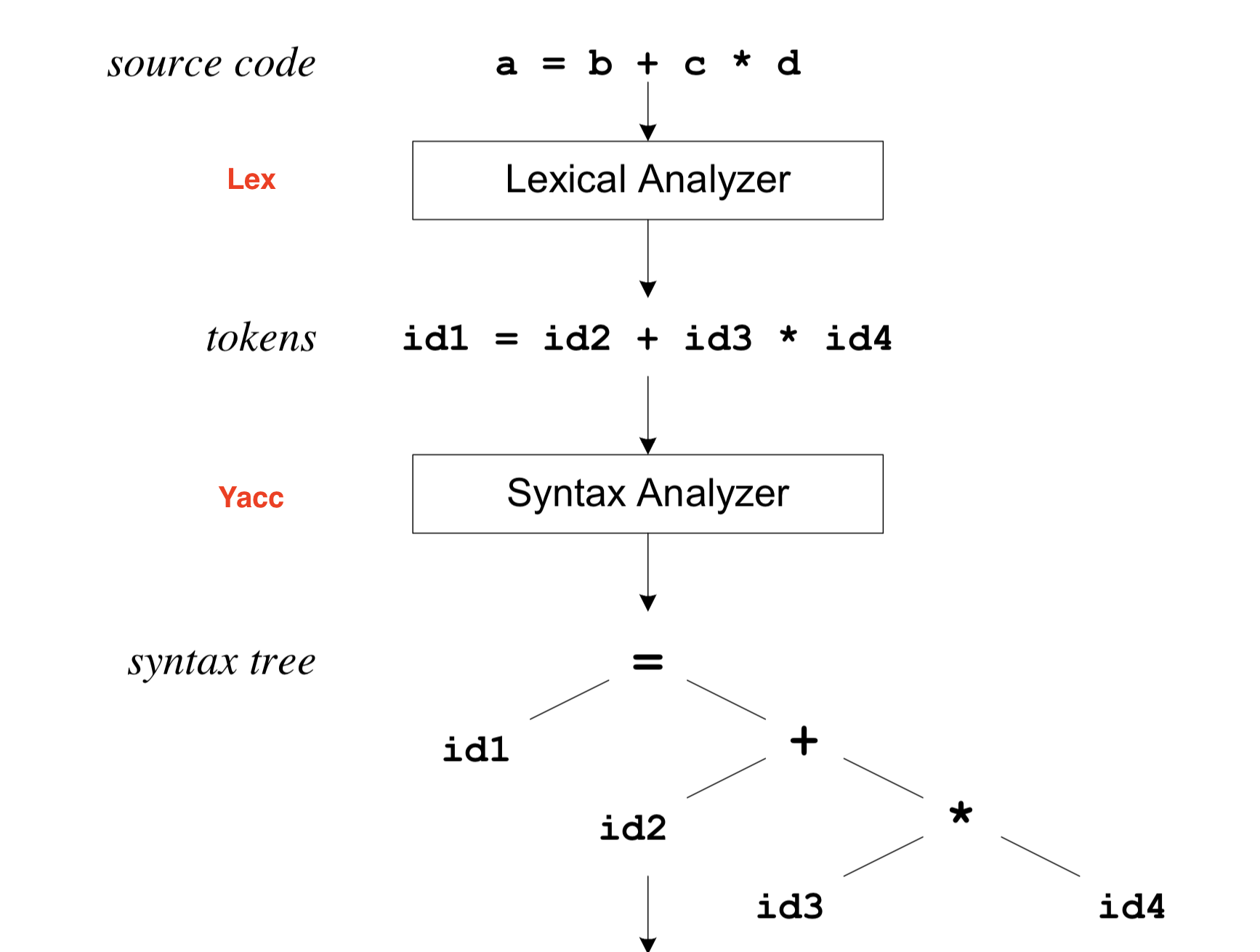
lex和yacc在20世纪70年代中旬诞生于著名的贝尔实验室,lex的原作者是Mike Lesk和Eric Schmidt(没错,就是Google前CEO),而yacc的原作者为Stephen C. Johnson。同样在贝尔实验室供职的C++之父Bjarne Stroustrup就是用yacc实现了第一个C++编译器cfront的前端的(C代码)。
lex是词法分析器,负责将源码(字符流)解析为一个个词法元素(token);而yacc则将这些token作为输入,构建出一个程序结构,通常是一个抽象语法树。
Reference
- https://www.antlr.org/about.html
- https://en.wikipedia.org/wiki/ANTLR
- https://github.com/antlr/antlr4/blob/master/doc/getting-started.md
- https://juejin.cn/post/7018521754125467661
- https://blog.gopheracademy.com/advent-2017/parsing-with-antlr4-and-go/