Background
In a shared memory multiprocessor system with a separate cache memory for each processor, it is possible to have many copies of shared data: one copy in the main memory and one in the local cache of each processor that requested it.
When one of the copies of data is changed, the other copies must reflect that change. Cache coherence is the discipline which ensures that the changes in the values of shared operands (data) are propagated throughout the system in a timely fashion.
Cache Coherence
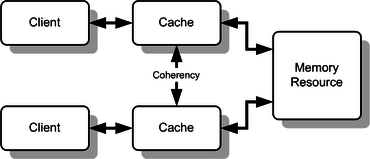
In computer architecture, cache coherence is the uniformity of shared resource data that ends up stored in multiple local caches. When clients in a system maintain caches of a common memory resource, problems may arise with incoherent data, which is particularly the case with CPUs in a multiprocessing system.
In the illustration, consider both the clients have a cached copy of a particular memory block from a previous read. Suppose the client on the bottom updates/changes that memory block, the client on the top could be left with an invalid cache of memory without any notification of the change. Cache coherence is intended to manage such conflicts by maintaining a coherent view of the data values in multiple caches.
The following are the requirements for cache coherence:
-
Write Propagation
Changes to the data in any cache must be propagated to other copies (of that cache line) in the peer caches.
-
Transaction Serialization
Reads/Writes to a single memory location must be seen by all processors in the same order.
Theoretically, coherence can be performed at the load/store granularity. However, in practice it is generally performed at the granularity of cache blocks
Explanation
Coherence defines the behavior of reads and writes to a single address location.
One type of data occurring simultaneously in different cache memory is called cache coherence, or in some systems, global memory.
In a multiprocessor system, consider that more than one processor has cached a copy of the memory location X. The following conditions are necessary to achieve cache coherence:
- In a read made by a processor P to a location X that follows a write by the same processor P to X, with no writes to X by another processor occurring between the write and the read instructions made by P, X must always return the value written by P.
- In a read made by a processor P1 to location X that follows a write by another processor P2 to X, with no other writes to X made by any processor occurring between the two accesses and with the read and write being sufficiently separated, X must always return the value written by P2. This condition defines the concept of coherent view of memory. Propagating the writes to the shared memory location ensures that all the caches have a coherent view of the memory. If processor P1 reads the old value of X, even after the write by P2, we can say that the memory is incoherent.
The above conditions satisfy the Write Propagation criteria required for cache coherence. However, they are not sufficient as they do not satisfy the Transaction Serialization condition. To illustrate this better, consider the following example:
A multi-processor system consists of four processors - P1, P2, P3 and P4, all containing cached copies of a shared variable S whose initial value is 0. Processor P1 changes the value of S (in its cached copy) to 10 following which processor P2 changes the value of S in its own cached copy to 20. If we ensure only write propagation, then P3 and P4 will certainly see the changes made to S by P1 and P2. However, P3 may see the change made by P1 after seeing the change made by P2 and hence return 10 on a read to S. P4 on the other hand may see changes made by P1 and P2 in the order in which they are made and hence return 20 on a read to S. The processors P3 and P4 now have an incoherent view of the memory.
Therefore, in order to satisfy Transaction Serialization, and hence achieve Cache Coherence, the following condition along with the previous two mentioned in this section must be met:
- Writes to the same location must be sequenced. In other words, if location X received two different values A and B, in this order, from any two processors, the processors can never read location X as B and then read it as A. The location X must be seen with values A and B in that order.
The alternative definition of a coherent system is via the definition of sequential consistency memory model: “the cache coherent system must appear to execute all threads’ loads and stores to a single memory location in a total order that respects the program order of each thread”. Thus, the only difference between the cache coherent system and sequentially consistent system is in the number of address locations the definition talks about (single memory location for a cache coherent system, and all memory locations for a sequentially consistent system).
Coherence Mechanisms
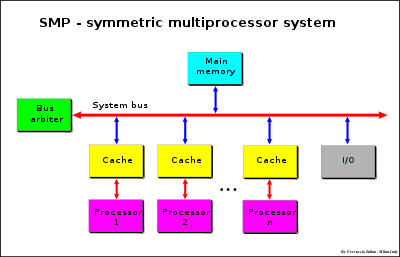
Bus watching or Snooping
Each processor has its own cache that acts as a bridge between processor and Main Memory. The connection is made using a System Bus or a Crossbar (“xbar”) or a mix of two previously approach, bus for address and crossbar for Data (Data crossbar).
The bottleneck of these systems is the traffic and the Memory bandwidth.
Types of snooping protocols
There are two kinds of snooping protocols depending on the way to manage a local copy of a write operation:
Write-invalidate
When a processor writes on a shared cache block, all the shared copies in the other caches are invalidated through bus snooping. This method ensures that only one copy of a datum can be exclusively read and written by a processor. All the other copies in other caches are invalidated. This is the most commonly used snooping protocol. MSI, MESI, MOSI, MOESI, and MESIF protocols belong to this category.
Write-update
When a processor writes on a shared cache block, all the shared copies of the other caches are updated through bus snooping. This method broadcasts a write data to all caches throughout a bus. It incurs larger bus traffic than write-invalidate protocol. That is why this method is uncommon. Dragon and firefly protocols belong to this category
Directory-based – Message-passing
Coherence Protocols
Coherence protocols apply cache coherence in multiprocessor systems. The intention is that two clients must never see different values for the same shared data.
Write-invalidate
When a write operation is observed to a location that a cache has a copy of, the cache controller invalidates its own copy of the snooped memory location, which forces a read from main memory of the new value on its next access.
Write-update
When a write operation is observed to a location that a cache has a copy of, the cache controller updates its own copy of the snooped memory location with the new data.
If the protocol design states that whenever any copy of the shared data is changed, all the other copies must be “updated” to reflect the change, then it is a write-update protocol. If the design states that a write to a cached copy by any processor requires other processors to discard or invalidate their cached copies, then it is a write-invalidate protocol.
However, scalability is one shortcoming of broadcast protocols.
Reference
- https://en.wikipedia.org/wiki/Cache_(computing)
- https://en.wikipedia.org/wiki/Cache_replacement_policies
- https://en.wikipedia.org/wiki/Cache_coherence
- https://en.wikipedia.org/wiki/Cache_coherency_protocols_(examples)
- https://en.wikipedia.org/wiki/Bus_snooping
- https://en.wikipedia.org/wiki/Directory-based_cache_coherence