Background
We try to use cache invalidation to solve cache coherence, i.e., try to let the updated data to be reflected as soon as possible, but there may be cache inconsistency occuring.
In this post, I would like to point out them and see how we are going to solve them with some trade-off.
Wrong Cache in Small Period of Time
Async by Cache Aside
Due to the nature of async, small period of time where data is stale.
DB: (x=1) => (x=2)
- App writes to database (x=2)
- App reads old data from cache (x=1)
- inconsistency occurs here
- Cache gets invalidated (x=nil)
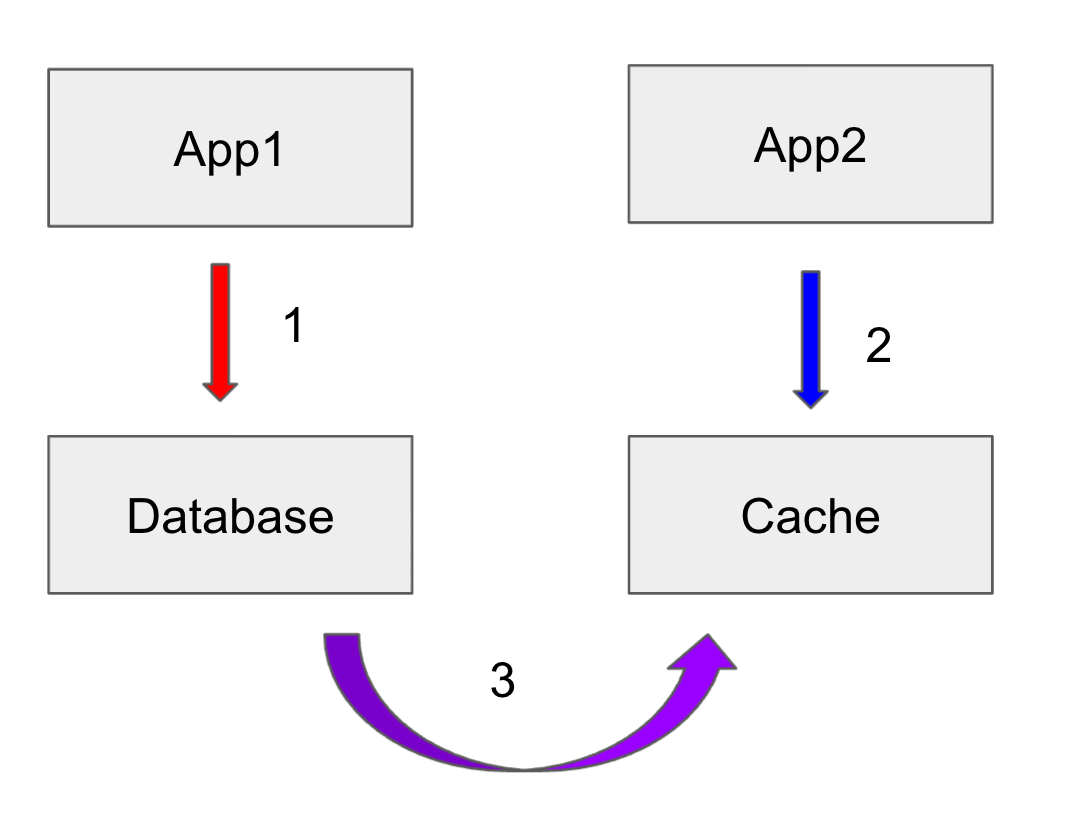
As a result, stale data is obtained, since App reads old data from cache (x=1)
Wrong Cache
Sync by App
DB: (x=1) => (x=2)
-
App2 reads from database (x=1)
-
App1 writes database (x=2)
-
Cache gets invalidated (x=nil)
-
App2 updates old data to cache (x=1)
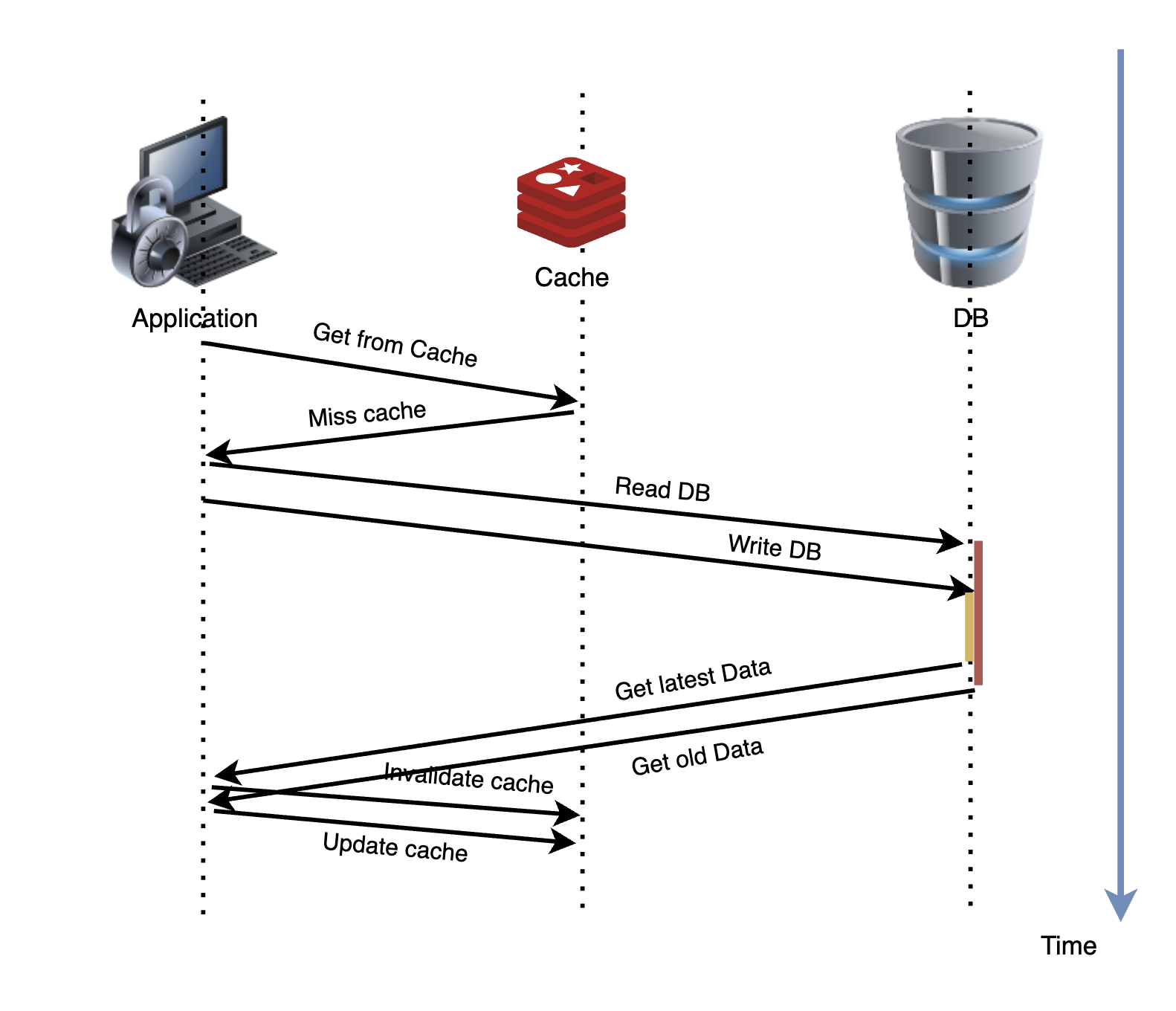
As a result, stale data is obtained. Because updating db and invalidating cache are not atomic.
Master-slave DB
In master-slave database setups, wrong data can be written to cache
x=1 => x=2
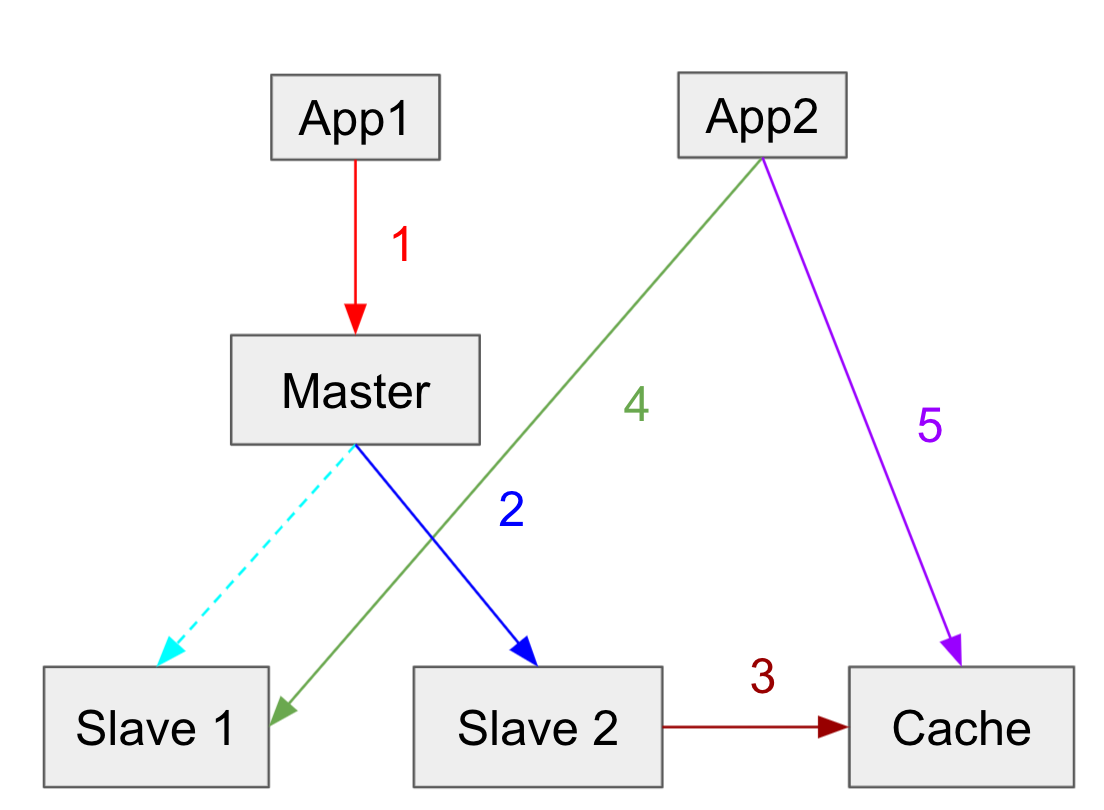
- App1 writes to master db (x=2)
- Replication completed on slave 2 (x=2)
- Cache gets invalidated (x=nil)
- App2 reads old data from slave 1 (Replication not completed yet) (x=1)
- App writes old data to cache (x=1)
DB: x=2, Cache: x=1
As a result, stale data occurs. And subsequent requests will read old data from cache until cache expires!
Summary
Basically, the problem here is reading stale data and setting it into cache.
Then, how about updating the cache directly, instead of invalidating it
Update Cache with Master DB
DB: x=1 => x=2
- App1 writes x=1 to db
- App2 writes x=2 to db
- App2 writes x=2 to cache
- App1 writes x=1 to cache
- Cache: x=1
Cache: x=1 -> Wrong Cache!
Possible Solution:
- Acquire a distributed lock before writing to cache, and release the lock after write to DB, so as to avoid race condition
Potential issue:
- What if write to cache fail (writing to DB succeeded)
Any Other Solutions?
Group Requests by Server
Make sure that read/write requests to the same entity falls on the same server/connection.
- Eg. GetUser Userid=123 will always go to server 123
- Ok, as long as your traffic is evenly distributed. Else,it might create hot spots
Synchronous Replication
- Use database tools that support synchronous replication
- Prevent slave database delay problems which cause wrong cache issues
- Mysql Cluster
- Mysql Group replication
- Performance might suffer
More Complex Solution - Mark Stale Data
Strategy used at Facebook
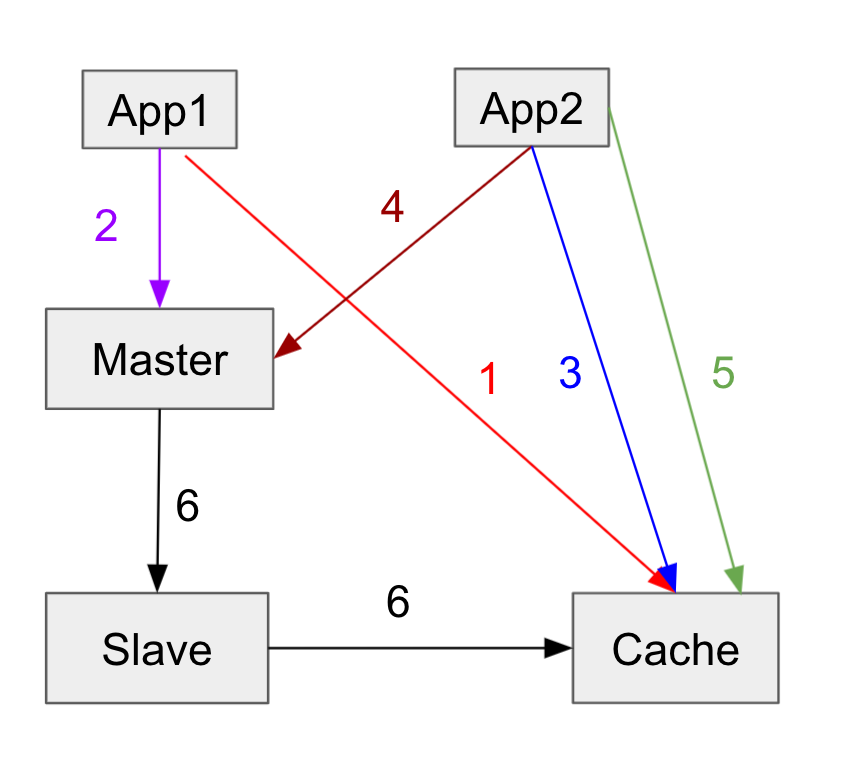
- App1 deletes x in cache and sets flag rx on cache to indicate stale data
- App1 writes to master
- App2 tries to read x from cache.
- If rx is present, indicate that x has just been updated and App2 reads from master instead.
- App2 writes the new value to cache
- Replication completes on slave and deletes x and flag rx in cache
Solves both cache and slave delay. Because it reads directly from master.
Thus, as a result, one bottleneck may be the master node.
Reference
- https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf
- https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=404087915&idx=1&sn=075664193f334874a3fc87fd4f712ebc&scene=21#wechat_redirect
- https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=404202261&idx=1&sn=1b8254ba5013952923bdc21e0579108e&scene=21