缓存穿透(Cache Penetration)问题
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层(不一定是DB,可以是任何数据源,比如API)都不会命中,但是出于容错的考虑,如果从存储层查不到数据则不写入缓存层,如下图所示整个过程分为如下 3 步:
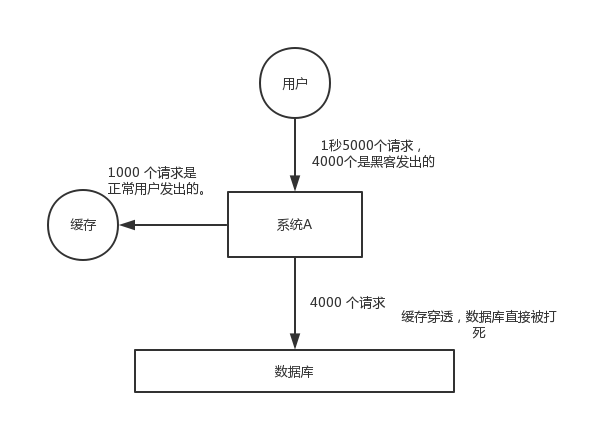
- 缓存层不命中
- 存储层不命中,所以不将空结果写回缓存
- 返回空结果
比如,查询一个用户的白名单,当这个白名单是一个 empty list 时,且不将 empty list 写回缓存,就会发生缓存穿透。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。
Solution
Approach 1 - 缓存空对象
如下图所示,当第 2 步存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,保护了后端数据源。
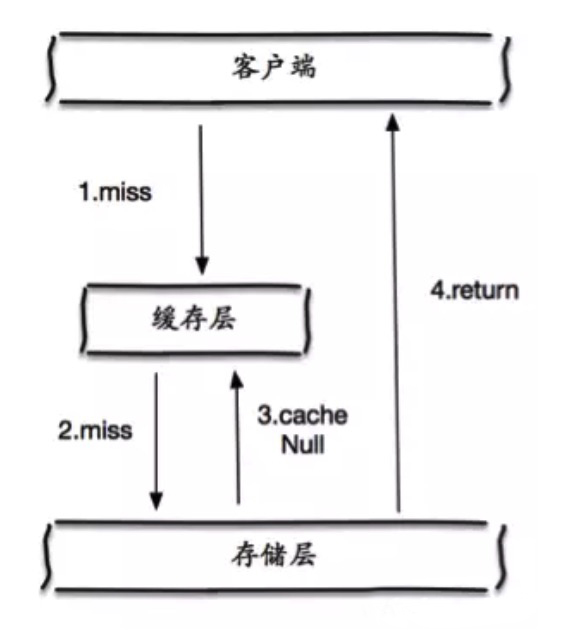
缓存空对象会有两个问题:
- 空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间 ( 如果是攻击,问题更严重 ),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
- 缓存层和存储层的数据会有一段时间窗口的 inconsistency,可能会对业务有一定影响。例如过期时间设置为 5 分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以通过 cache invalidation mechanism (比如通过消息系统实现)清除掉缓存层中的空对象。
Approach 2 - 布隆过滤器(bloom filter)拦截
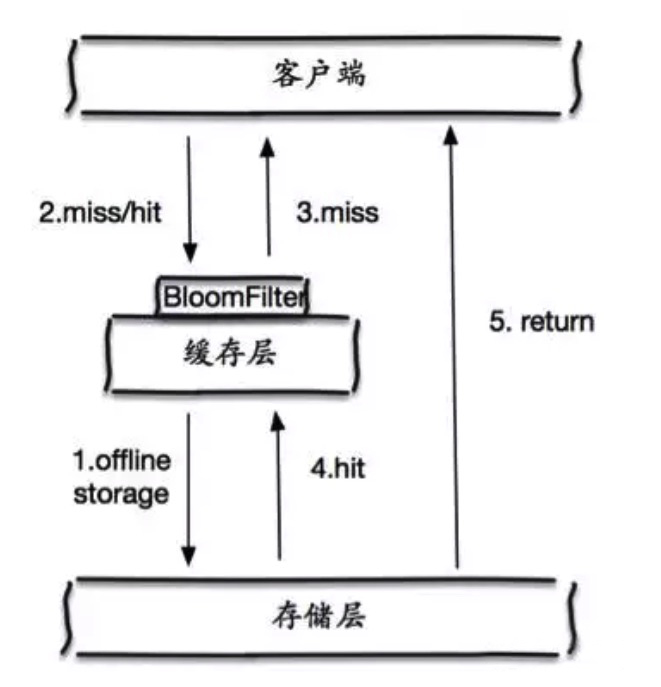
如上图所示,在访问缓存层和存储层之前,将存在的 key 用布隆过滤器提前保存起来,做第一层拦截。
例如: 一个个性化推荐系统有 4 亿个用户 ID,每个小时算法工程师会根据每个用户之前历史行为做出来的个性化放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为。
为此可以将所有有个性化推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户 ID 不存在,那么就不会访问存储层,在一定程度保护了存储层。
缓存雪崩(Cache Avalanche)问题
Cache avalanche is a scenario where lots of cached data expire at the same time or the cache service is down and all of a sudden all searches of these data will hit DB and cause high load to the DB layer and impact the performance, even leads to totally service unavailability(因为雪崩)。
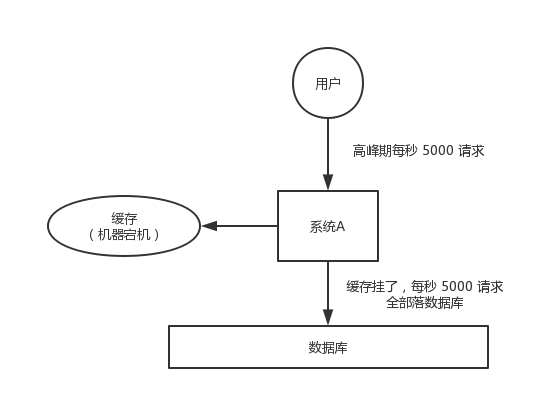
Solution
预防和解决缓存雪崩问题,可以从以下三个方面进行着手。
Approach 1 - 保证缓存层服务高可用性
和飞机都有多个引擎一样,如果缓存层设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提供服务,例如 Redis Sentinel 和 Redis Cluster 都实现了高可用。
Approach 2 - 为时效时间增加随机值
一个简单且有效的方案就是将缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
Approach 3 - 依赖 circuit breaker 组件为后端限流并降级
无论是缓存层还是存储层都会有出错的概率,可以将它们视同为资源。作为并发量较大的系统,假如有一个资源不可用,可能会造成线程全部 hang 在这个资源上,造成整个系统不可用。降级在高并发系统中是非常正常的:比如推荐服务中,如果个性化推荐服务不可用,可以降级补充热点数据,不至于造成前端页面是开天窗。
在实际项目中,我们需要对重要的资源 ( 例如 Redis、 MySQL、 Hbase、外部接口 ) 都进行隔离,让每种资源都单独运行在自己的线程池中,即使个别资源出现了问题,对其他服务没有影响。
缓存击穿(Cache Breakdown)问题
Cache breakdown is similar to cache avalanche, but it is not a massive cache failure.
Cache breakdown means that a key value in the cache continuously receives a large number of requests, and at the moment when the key value fails, a large number of requests fall on the database, which may lead to excessive pressure on the database.
Hotspot data set is invalid
What is the hotspot data set failure?
We usually set an expiration time for the cache. After the expiration time, the database will be deleted directly by the cache, thus ensuring the real-time performance of the data to a certain extent.
However, for some hot data with very high requests, once the valid time has passed, there will be a large number of requests falling on the database at this moment, which may cause the database to crash. The process is as follows:
If a hotspot data fails, then when there is a query request [req-1] for the data again, it will go to the database query. However, from the time the request is sent to the database to the time the data is updated into the cache, since the data is still not in the cache, the query request arriving during this time will fall on the database, which will cause the database Enormous pressure. In addition, when these request queries are completed, the cache is updated repeatedly.
Solution
Approach 1 - Mutex - Distributed Lock
- Redis Lock
- Zookeeper
- etcd
We can use the lock mechanism that comes with the cache. When the first database query request is initiated, the data in the cache will be locked; at this time, other query requests that arrive at the cache will not be able to query the field, and thus will be blocked waiting;
After a request completes the database query and caches the data update value, the lock is released; at this time, other blocked query requests can be directly retrieved from the cache.
When a hotspot data fails, only the first database query request is sent to the database, and all other query requests are blocked, thus protecting the database. However, due to the use of a mutex, other requests will block waiting and the throughput of the system will drop. This needs to be combined with actual business considerations to allow this.
Approach 2 - Refresh Ahead Caching
Another feasible method is to asynchronously update the cached data through a worker thread so that the hot data will never expire.
In the Refresh-Ahead scenario, Coherence allows a developer to configure a cache to automatically and asynchronously reload (refresh) any recently accessed cache entry from the cache loader before its expiration. The result is that after a frequently accessed entry has entered the cache, the application will not feel the impact of a read against a potentially slow cache store when the entry is reloaded due to expiration. The asynchronous refresh is only triggered when an object that is sufficiently close to its expiration time is accessed—if the object is accessed after its expiration time, Coherence will perform a synchronous read from the cache store to refresh its value.
Reference
- 缓存穿透,缓存击穿,缓存雪崩解决方案分析 - https://blog.csdn.net/zeb_perfect/article/details/54135506
- https://www.pixelstech.net/article/1586522853-What-is-cache-penetration-cache-breakdown-and-cache-avalanche
- https://medium.com/@mena.meseha/3-major-problems-and-solutions-in-the-cache-world-155ecae41d4f
- https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-caching-avalanche-and-caching-penetration.md
- https://developpaper.com/redis-cache-avalanche-cache-breakdown-cache-penetration/
- https://www.pixelstech.net/article/1586522853-What-is-cache-penetration-cache-breakdown-and-cache-avalanche