Definition
In computing, a cache is a hardware or software component that stores data so that future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation or a copy of data stored elsewhere.
A cache hit occurs when the requested data can be found in a cache, while a cache miss occurs when it cannot. Cache hits are served by reading data from the cache, which is faster than recomputing a result or reading from a slower data store; thus, the more requests that can be served from the cache, the faster the system performs.
To be cost-effective and to enable efficient use of data, caches must be relatively small. Nevertheless, caches have proven themselves in many areas of computing, because typical computer applications access data with a high degree of locality of reference. Such access patterns exhibit temporal locality, where data is requested that has been recently requested already, and spatial locality, where data is requested that is stored physically close to data that has already been requested.
Terminology
When the cache client (a CPU, web browser, operating system) needs to access data presumed to exist in the backing store, it first checks the cache. If an entry can be found with a tag matching that of the desired data, the data in the entry is used instead. This situation is known as a cache hit. For example, a web browser program might check its local cache on disk to see if it has a local copy of the contents of a web page at a particular URL. In this example, the URL is the tag, and the content of the web page is the data. The percentage of accesses that result in cache hits is known as the hit rate or hit ratio of the cache.
The alternative situation, when the cache is checked and found not to contain any entry with the desired tag, is known as a cache miss. This requires a more expensive access of data from the backing store. Once the requested data is retrieved, it is typically copied into the cache, ready for the next access.
Factors When Design Cache
- is the system write heavy and reads less frequently? (e.g. time based logs)
- If yes, may lead to low cache hit rate
- is data written once and read multiple times? (e.g. User Profile)
- If yes, may be good to have a cache layer
- is data returned always unique? (e.g. search queries)
- If yes, may lead to low cache hit rate
General Cache Use Cases
Let’s see some popular use case for caching probably your use case might overlap with one of them:
In-memory data lookup: If you have a mobile / web app front end you might want to cache some information like user profile, some historical / static data, or some api response according to your use cases. Caching will help in storing such data. Also when you create a dynamic programming solution for some problem, 2-dimensional array or hash maps work as a caching.
RDBMS Speedup: Relational databases are slow when it comes to working with millions of rows. Unnecessary data or old data, high volume data can make their index slower, irrespective of whether you do sharding or partitioning, a single node can always experience delay & latency in query response when the database is full in its capacity. In such scenarios, probably many ‘SELECT’ queries or read queries can be cached externally at least for some small time window. Relational databases use their own caching as well, but for better performance external caching can have much more capacity than internal caching. It’s one of the most popular use cases of caching.
Manage Spike in web/mobile apps: Often popular web/mobile apps experience heavy spike when it attracts a lot of user traction. Many of such calls may end up being read queries in database, external web service calls, some can be computed data like on the fly computation of previous payments, some can be non-critical dynamic data like no of followers for a user, no of re-tweets, viewers counts etc. Caching can be used to serve such data.
Session Store: Active web sessions are very frequently accessed data — whether you want to do api authentication or you want to store recent cart information in an e-commerce app, the cache can serve session well.
Token Caching: API Tokens can be cached in memory to deliver high-performance user authentication and validation.
Gaming: Player profile & leader board are 2 very frequent screens viewed by gamers specially in online multiplayer games. So with millions of gamers, it becomes extremely important to update & fetch such data very fast. Caching fits for this use case as well.
Web Page Caching: In order make mobile/web app lightweight & flexible UI, you can create dynamic web pages in the server & serve it through api along with appropriate data. So if you have millions of users, you can serve such on the fly created full/fragmented web pages from the cache for a certain time period.
Global Id or Counter generation: When you have variable number of say relational database instances across nodes & you want to generate an auto incrementing primary key for them, or when you want to assign unique id to your users, you can use caching to fetch & update such data at scale.
Fast Access To Any Suitable Data: Many times we think cache is only used to store frequently accessed data for read purpose. Although this is mostly correct, this behaviour can vary according to use cases. Cache can be used to store less frequent data also if you really need fast access to that data. We use cache to access the data very fast, so storing most frequent / least frequent data is just a matter of use case.
Cache Storage
Single Node ( In-Process ) Caching
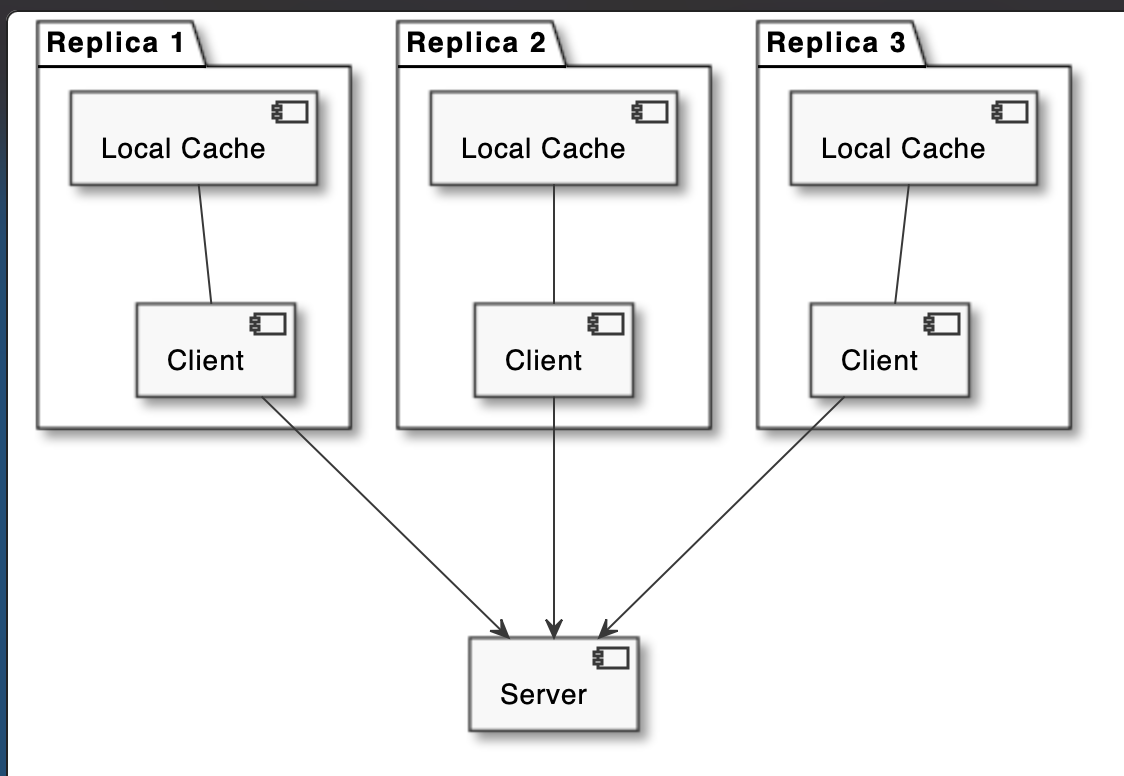
It’s a caching strategy for non distributed systems. Applications instantiate & manage their own or 3rd party cache objects. Both application & cache are in the same memory space.
This type of cache is used for caching database entities but can also be used as some kind of an object pool, for instance pooling most recently used network connections to be reused at a later point.
Advantages:
- Locally available data, so highest speed, easy to maintain.
Disadvantages:
- High memory consumption in a single node, cache shares memory with the application. If multiple application relies on same set of data, then there might be a problem of data duplication.
*Usecase:* Choose this strategy when you are making standalone applications like mobile apps, or web front end apps where you want to temporarily cache website data that you got from back end api or other stuffs like images, css, java script contents. This strategy is also useful when you want to share objects that probably you created from an api response across different methods in different classes in your backend application.
Distributed Caching
The client stores a copy of the responses returned by the server on a specialised remote server (e.g. Redis, Memcached).
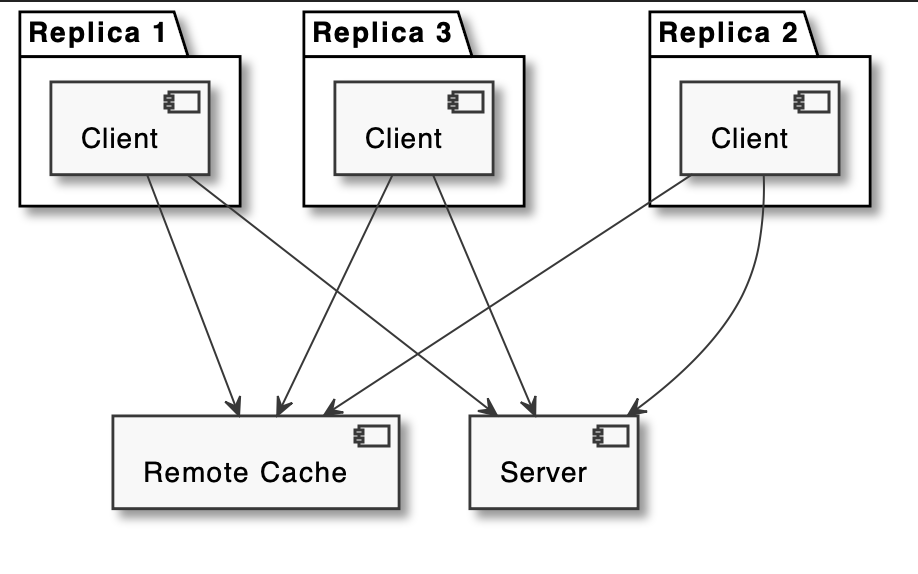
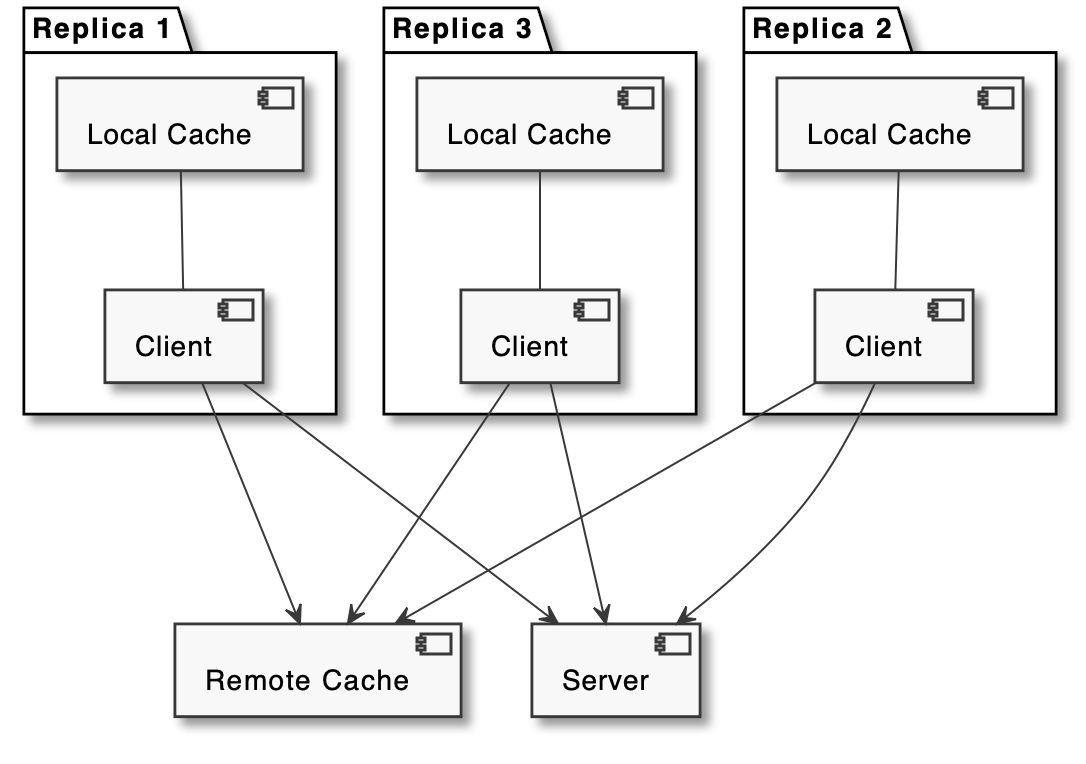
Hierarchical Cache
Cache Algorithm (Cache Replacement Algorithms, Cache Replacement Policies, Eviction Policy)
refer to https://swsmile.info/post/cache-replacement-algorithms/
Reference
- https://en.wikipedia.org/wiki/Cache_(computing)
- https://en.wikipedia.org/wiki/Cache_replacement_policies
- https://medium.datadriveninvestor.com/all-things-caching-use-cases-benefits-strategies-choosing-a-caching-technology-exploring-fa6c1f2e93aa
- https://www.lpalmieri.com/posts/caching-types-in-a-microservice-architecture/