Background
Over the last several years we’ve seen a whole range of ideas regarding the architecture of systems. These include:
- Hexagonal Architecture (a.k.a. Ports and Adapters) by Alistair Cockburn and adopted by Steve Freeman, and Nat Pryce in their wonderful book Growing Object Oriented Software
- Onion Architecture by Jeffrey Palermo
- Screaming Architecture from a blog of mine last year
- DCI from James Coplien, and Trygve Reenskaug.
- BCE by Ivar Jacobson from his book Object Oriented Software Engineering: A Use-Case Driven Approach
Though these architectures all vary somewhat in their details, they are very similar. They all have the same objective, which is the separation of concerns. They all achieve this separation by dividing the software into layers. Each has at least one layer for business rules, and another for interfaces.
Each of these architectures produce systems that are:
- Independent of Frameworks. The architecture does not depend on the existence of some library of feature laden software. This allows you to use such frameworks as tools, rather than having to cram your system into their limited constraints.
- Testable. The business rules can be tested without the UI, Database, Web Server, or any other external element.
- Independent of UI. The UI can change easily, without changing the rest of the system. A Web UI could be replaced with a console UI, for example, without changing the business rules.
- Independent of Database. You can swap out Oracle or SQL Server, for Mongo, BigTable, CouchDB, or something else. Your business rules are not bound to the database.
- Independent of any external agency. In fact your business rules simply don’t know anything at all about the outside world.
Clean Architecture
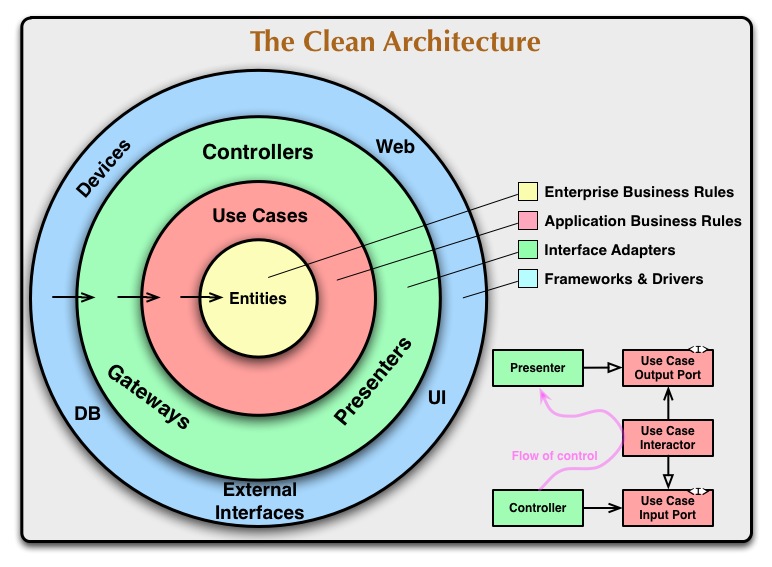
The foundation layers of The Clean Architecture are:
- Entities (Enterprise Business Rules)
- Use cases (Application Business Rules)
- Interface Adapters
- Frameworks and Drivers.
-
Enterprise business rules = Entities/ domains
-
Entities 层封装了企业业务规则,准确地讲,它应该是一个面向业务的领域模型。
-
领域模型就是业务逻辑的模型,它应该是完全纯粹的,无论你选择什么框架,什么数据库,或者什么通信技术,按照整洁架构的思想都不应该去污染领域模型
-
如果以 Java 语言来实现,遵循整洁架构的设计思想,则所有领域模型对象都应该是 POJO(Plain Ordinary Java Object)。整洁架构的 Entities 层对应于领域驱动设计的领域层。
-
-
Application business rules / Use cases = business logic
- Gateways、Controllers 与 Presenters 其本质都是适配器(Adapter),用于打通应用业务逻辑与外层的框架和驱动器,实现逻辑的适配以访问外部资源。
-
Interfaces/Adapters = Controllers/Gateways/Presenters
- There are ways to interact with the application, and typically involve a delivery mechanism (for example, REST APIs, scheduled jobs, GUI, other systems)
- Trigger a use case and convert the result to the appropriate format for the delivery mechanism
- the controller for a MVC
- 我更倾向于将这些组件都视为是网关(Gateway)。对下,例如,针对数据库、消息队列或硬件设备,可以认为是一个南向网关,对于当前限界上下文是一种输出的依赖;对上,例如,针对 Web 和 UI,可以认为是一个北向网关,对于当前限界上下文是一种输入的依赖。
- 例如,作为 RESTful 服务的 OrderController,就是北向网关中的一个类,它通过调用 Use Cases 层的 OrderAppService 服务来实现一个提交订单的业务用例。OrderAppService 并不需要知道作为调用者的 OrderController,如果存在将 Entities 层的领域模型对象转换为 RESTful 服务的 Resource 对象,也是 OrderController 或者说北向网关的职责。
-
Frameworks and Drivers = Devices/Web/DB/External Interfaces/UI
- 南向网关作为底层资源的访问者,往往成为 Use Cases 层甚至 Entities 层的被调用者。
- 由于整洁架构思想并不允许内层获知外层的存在,这就导致了我们必须在内层定义与外层交互的接口,然后通过依赖注入的方式将外层的实现注入到内层中,这也是“控制反转(Inversion of Control)”的含义,即将调用的控制权转移到了外层。由是我们可以得出一个结论,即南向网关封装了与外部资源(DB、Devices、MQ)交互的实现细节,但其公开暴露的接口却需要被定义在内层的 Use Cases 或 Entities 中,这实际上阐释了为什么领域驱动设计要求将 Repository 的接口定义在领域层的技术原因。
The Dependency Rule
The concentric circles represent different areas of software. In general, the further in you go, the higher level the software becomes. The outer circles are mechanisms. The inner circles are policies.
The overriding rule that makes this architecture work is The Dependency Rule. This rule says that source code dependencies can only point inwards. Nothing in an inner circle can know anything at all about something in an outer circle. In particular, the name of something declared in an outer circle must not be mentioned by the code in the an inner circle. That includes, functions, classes. variables, or any other named software entity.
By the same token, data formats used in an outer circle should not be used by an inner circle, especially if those formats are generate by a framework in an outer circle. We don’t want anything in an outer circle to impact the inner circles.
Entities
- Represent your domain object
- Apply only logic that is applicable in general to the whole entity (e.g., validating the format of a hostname)
- Plain objects: no frameworks, no annotations
- Entities 层封装了企业业务规则,准确地讲,它应该是一个面向业务的领域模型。
- 领域模型就是业务逻辑的模型,它应该是完全纯粹的,无论你选择什么框架,什么数据库,或者什么通信技术,按照整洁架构的思想都不应该去污染领域模型
- 如果以 Java 语言来实现,遵循整洁架构的设计思想,则所有领域模型对象都应该是 POJO(Plain Ordinary Java Objects),这暗示了这里的实现是。整洁架构的 Entities 层对应于领域驱动设计的领域层。
Entities encapsulate Enterprise wide business rules. An entity can be an object with methods, or it can be a set of data structures and functions. It doesn’t matter so long as the entities could be used by many different applications in the enterprise.
If you don’t have an enterprise, and are just writing a single application, then these entities are the business objects of the application. They encapsulate the most general and high-level rules. They are the least likely to change when something external changes. For example, you would not expect these objects to be affected by a change to page navigation, or security. No operational change to any particular application should affect the entity layer.
Use Cases / business logic
- Represent your business actions: it’s what you can do with the application. Expect one use case for each business action
- Pure business logic, plain code (except maybe some utils libraries)
- The use case doesn’t know who triggered it and how the results are going to be presented (for example, could be on a web page, or — returned as JSON, or simply logged, and so on.)
- Throws business exceptions
- Gateways、Controllers 与 Presenters 其本质都是适配器(Adapter),用于打通应用业务逻辑与外层的框架和驱动器,实现逻辑的适配以访问外部资源。
The software in this layer contains application specific business rules. It encapsulates and implements all of the use cases of the system. These use cases orchestrate the flow of data to and from the entities, and direct those entities to use their enterprise wide business rules to achieve the goals of the use case.
We do not expect changes in this layer to affect the entities. We also do not expect this layer to be affected by changes to externalities such as the database, the UI, or any of the common frameworks. This layer is isolated from such concerns.
We do, however, expect that changes to the operation of the application will affect the use-cases and therefore the software in this layer. If the details of a use-case change, then some code in this layer will certainly be affected.
**Interfaces / Adapters / Repository
- Retrieve and store data from and to a number of sources (database, network devices, file system, 3rd parties, and so on.)
- Define interfaces for the data that they need in order to apply some logic. One or more data providers will implement the interface, but the use case doesn’t know where the data is coming from
- Implement the interfaces defined by the use case
- There are ways to interact with the application, and typically involve a delivery mechanism (for example, REST APIs, scheduled jobs, GUI, other systems)
- Trigger a use case and convert the result to the appropriate format for the delivery mechanism
- the controller for a MVC
The software in this layer is a set of adapters that convert data from the format most convenient for the use cases and entities, to the format most convenient for some external agency such as the Database or the Web. It is this layer, for example, that will wholly contain the MVC architecture of a GUI. The Presenters, Views, and Controllers all belong in here. The models are likely just data structures that are passed from the controllers to the use cases, and then back from the use cases to the presenters and views.
Similarly, data is converted, in this layer, from the form most convenient for entities and use cases, into the form most convenient for whatever persistence framework is being used. i.e. The Database. No code inward of this circle should know anything at all about the database. If the database is a SQL database, then all the SQL should be restricted to this layer, and in particular to the parts of this layer that have to do with the database.
Also in this layer is any other adapter necessary to convert data from some external form, such as an external service, to the internal form used by the use cases and entities.
Frameworks and Drivers (External Interfaces)
- Use whatever framework is most appropriate (they are going to be isolated here anyway)
The outermost layer is generally composed of frameworks and tools such as the Database, the Web Framework, etc. Generally you don’t write much code in this layer other than glue code that communicates to the next circle inwards.
This layer is where all the details go. The Web is a detail. The database is a detail. We keep these things on the outside where they can do little harm.
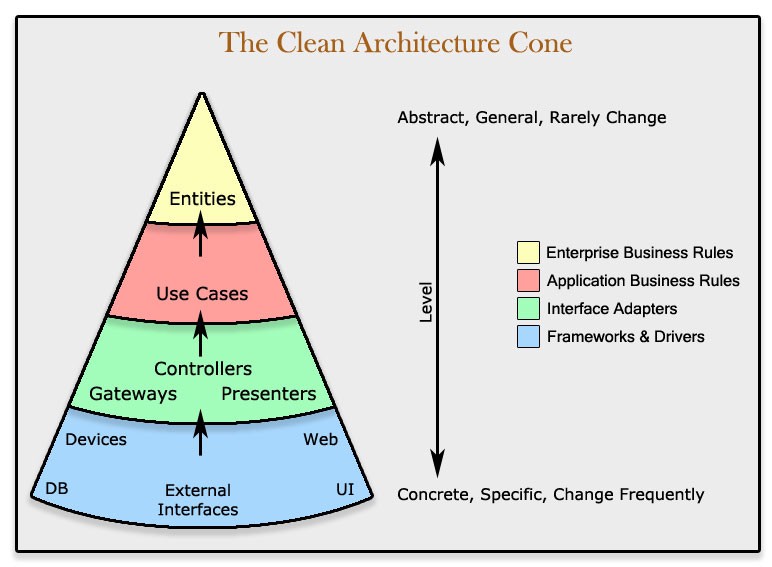
Only Four Circles?
No, the circles are schematic. You may find that you need more than just these four. There’s no rule that says you must always have just these four. However, The Dependency Rule always applies. Source code dependencies always point inwards. As you move inwards the level of abstraction increases. The outermost circle is low level concrete detail. As you move inwards the software grows more abstract, and encapsulates higher level policies. The inner most circle is the most general.
Crossing boundaries
At the lower right of the diagram is an example of how we cross the circle boundaries. It shows the Controllers and Presenters communicating with the Use Cases in the next layer. Note the flow of control. It begins in the controller, moves through the use case, and then winds up executing in the presenter. Note also the source code dependencies. Each one of them points inwards towards the use cases.
We usually resolve this apparent contradiction by using the Dependency Inversion Principle. In a language like Java, for example, we would arrange interfaces and inheritance relationships such that the source code dependencies oppose the flow of control at just the right points across the boundary.
For example, consider that the use case needs to call the presenter. However, this call must not be direct because that would violate The Dependency Rule: No name in an outer circle can be mentioned by an inner circle. So we have the use case call an interface (Shown here as Use Case Output Port) in the inner circle, and have the presenter in the outer circle implement it.
The same technique is used to cross all the boundaries in the architectures. We take advantage of dynamic polymorphism to create source code dependencies that oppose the flow of control so that we can conform to The Dependency Rule no matter what direction the flow of control is going in.
六边形架构
整洁架构的目的在于识别整个架构不同视角以及不同抽象层次的关注点,并为这些关注点划分不同层次的边界,从而使得整个架构变得更加清晰,减少不必要的耦合。它采用了内外层的架构模型弥补了分层架构无法体现领域核心位置的缺陷。由 Alistair Cockburn 提出的六边形架构(Hexagonal Architecture)在满足整洁架构思想的同时,更关注于内层与外层以及与外部资源之间通信的本质:
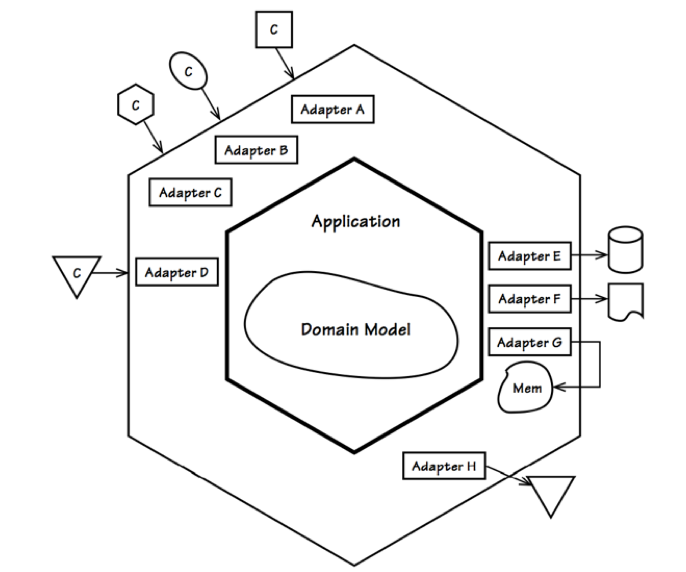
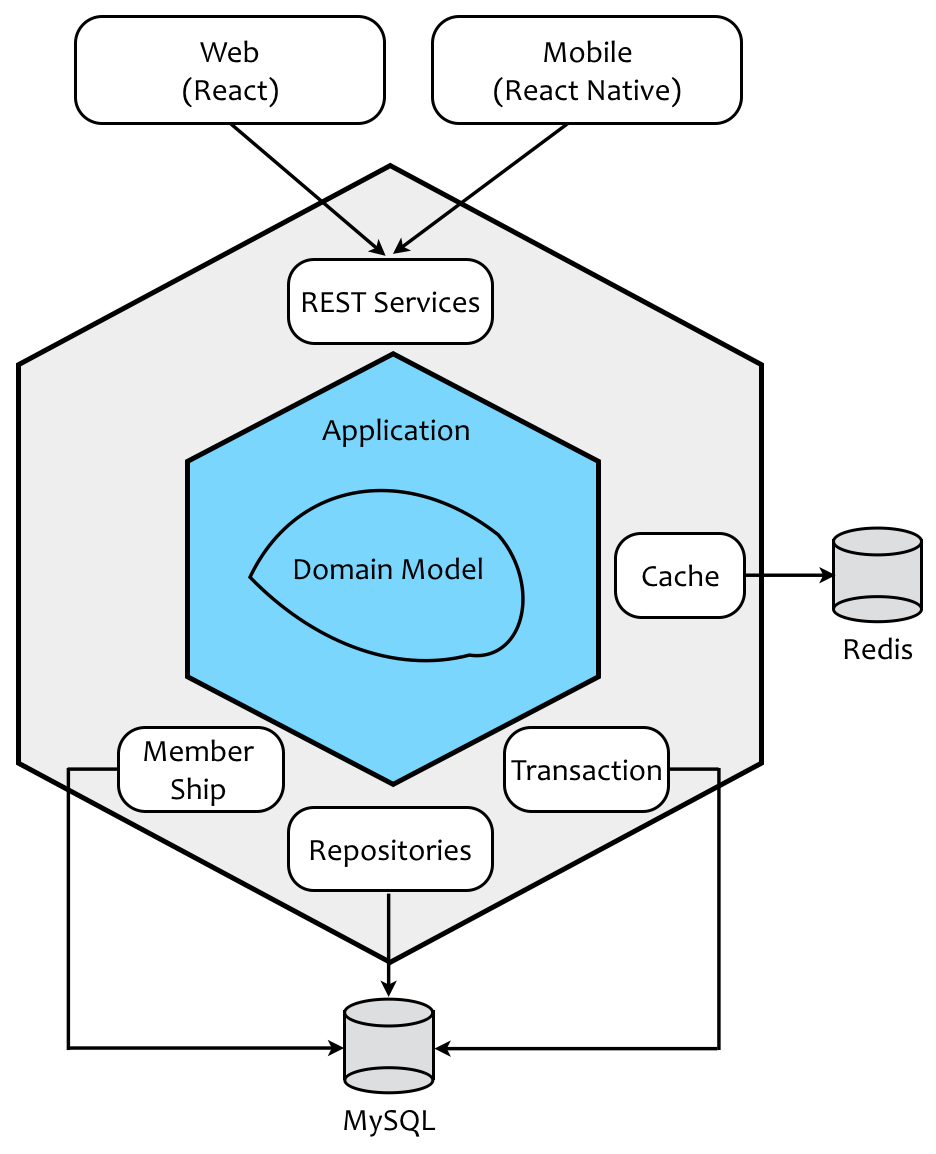
如上图所示,六边形架构通过内外两个六边形为系统建立了不同层次的边界。核心的内部六边形对应于领域驱动设计的应用层与领域层,外部六边形之外则为系统的外部资源,至于两个六边形之间的区域,均被 Cockburn 视为适配器(Adapter),并通过端口(Port)完成内外区域之间的通信与协作,故而六边形架构又被称为端口-适配器模式(port-adapter pattern)。下图更加清晰地表达了领域驱动设计分层架构与六边形架构的关系,同时也清晰地展现了业务复杂度与技术复杂度的边界:
Reference
- Robert C. Martin, Clean Architecture: A Craftsman’s Guide to Software Structure and Design
- Robert C. Martin, The Clean Coder: A Code of Conduct for Professional Programmers
- https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
- https://www.freecodecamp.org/news/a-quick-introduction-to-clean-architecture-990c014448d2/
- https://learn.lianglianglee.com/%E4%B8%93%E6%A0%8F/%E9%A2%86%E5%9F%9F%E9%A9%B1%E5%8A%A8%E8%AE%BE%E8%AE%A1%E5%AE%9E%E8%B7%B5%EF%BC%88%E5%AE%8C%EF%BC%89/023%20%E5%88%86%E5%B1%82%E6%9E%B6%E6%9E%84%E7%9A%84%E6%BC%94%E5%8C%96.md