CPU Cache
A CPU cache is a hardware cache used by the central processing unit (CPU) of a computer to reduce the average cost (time or energy) to access data from the main memory.[1] A cache is a smaller, faster memory, located closer to a processor core, which stores copies of the data from frequently used main memory locations. Most CPUs have a hierarchy of multiple cache levels (L1, L2, often L3, and rarely even L4), with separate instruction-specific and data-specific caches at level 1.
CPU的缓存一致性的问题
如果有一个数据 x 在 CPU 第0核的缓存上被更新了,那么其它CPU核上对于这个数据 x 的值也要被更新,这就是缓存一致性的问题。(当然,对于我们上层的程序我们不用关心CPU多个核的缓存是怎么同步的,这对上层的代码来说都是透明的)
一般来说,在CPU硬件上,会有两种方法来解决这个问题。
- Directory 协议。这种方法的典型实现是要设计一个集中式控制器,它是主存储器控制器的一部分。其中有一个目录存储在主存储器中,其中包含有关各种本地缓存内容的全局状态信息。当单个CPU Cache 发出读写请求时,这个集中式控制器会检查并发出必要的命令,以在主存和CPU Cache之间或在CPU Cache自身之间进行数据同步和传输。
- Snoopy 协议。这种协议更像是一种数据通知的总线型的技术。CPU Cache通过这个协议可以识别其它Cache上的数据状态。如果有数据共享的话,可以通过广播机制将共享数据的状态通知给其它CPU Cache。这个协议要求每个CPU Cache 都可以***“*窥探*”***数据事件的通知并做出相应的反应。如下图所示,有一个Snoopy Bus的总线。
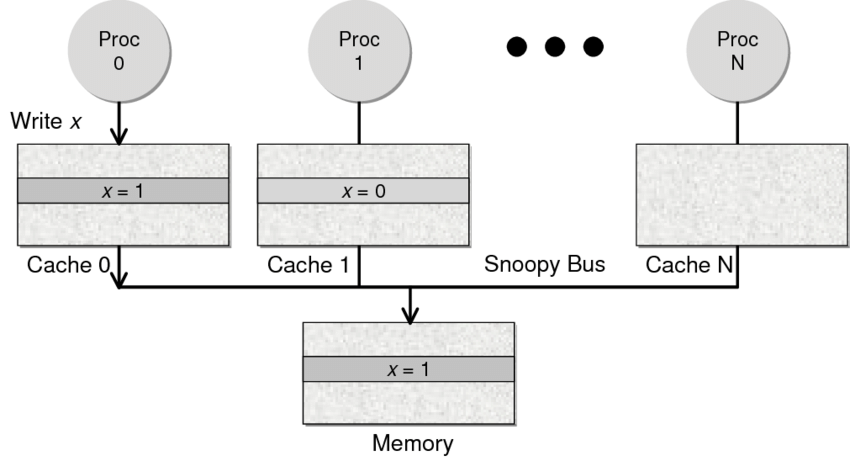
因为Directory协议是一个中心式的,会有性能瓶颈,而且会增加整体设计的复杂度。而Snoopy协议更像是微服务+消息通讯,所以,现在基本都是使用Snoopy的总线的设计。
这里,我想多写一些细节,因为这种微观的东西,让人不自然地就会跟分布式系统关联起来,在分布式系统中我们一般用Paxos/Raft这样的分布式一致性的算法。而在CPU的微观世界里,则不必使用这样的算法,原因是因为CPU的多个核的硬件不必考虑网络会断会延迟的问题。所以,CPU的多核心缓存间的同步的核心就是要管理好数据的状态就好了。
这里介绍几个状态协议,先从最简单的开始,MESI协议,这个协议跟那个著名的足球运动员梅西没什么关系,其主要表示缓存数据有四个状态:Modified(已修改), Exclusive(独占的),Shared(共享的),Invalid(无效的)。
这些状态的状态机如下所示(有点复杂,你可以先不看,这个图就是想告诉你状态控制有多复杂):
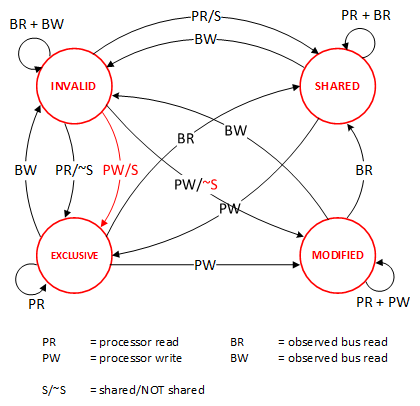
下面是个示例(如果你想看一下动画演示的话,这里有一个网页(MESI Interactive Animations),你可以进行交互操作,这个动画演示中使用的Write Through算法):
| 当前操作 | CPU0 | CPU1 | Memory | 说明 |
|---|---|---|---|---|
| 1) CPU0 read(x) | x=1 (E) | x=1 | 只有一个CPU有 x 变量, 所以,状态是 Exclusive | |
| 2) CPU1 read(x) | x=1 (S) | x=1(S) | x=1 | 有两个CPU都读取 x 变量, 所以状态变成 Shared |
| 3) CPU0 write(x,9) | x=9 (M) | x=1(I) | x=1 | 变量改变,在CPU0中状态 变成 Modified,在CPU1中 状态变成 Invalid |
| 4) 变量 x 写回内存 | x=9 (M) | X=1(I) | x=9 | 目前的状态不变 |
| 5) CPU1 read(x) | x=9 (S) | x=9(S) | x=9 | 变量同步到所有的Cache中, 状态回到Shared |
Store Buffer
当写入到一行 invalidate 状态的 cache line 时便会使用到 store buffer。写如果要继续执行,CPU 需要先发出一条 read-invalid 消息(因为需要确保所有其它缓存了当前内存地址的 CPU 的 cache line 都被 invalidate 掉),然后将写推入到 store buffer 中,当最终 cache line 达到当前 CPU 时再执行这个写操作。
CPU 存在 store buffer 的直接影响是,当 CPU 提交一个写操作时,这个写操作不会立即写入到 cache 中。因而,无论什么时候 CPU 需要从 cache line 中读取,都需要先扫描它自己的 store buffer 来确认是否存在相同的 line,因为有可能当前 CPU 在这次操作之前曾经写入过 cache,但该数据还没有被刷入过 cache(之前的写操作还在 store buffer 中等待)。需要注意的是,虽然 CPU 可以读取其之前写入到 store buffer 中的值,但其它 CPU 并不能在该 CPU 将 store buffer 中的内容 flush 到 cache 之前看到这些值。即 store buffer 是不能跨核心访问的,CPU 核心看不到其它核心的 store buffer。
False/True Sharing
程序性能
Demo 1
我们再来看一个与缓存命中率有关的代码,我们以一定的步长increment 来访问一个连续的数组。
for (int i = 0; i < 10000000; i++) {
for (int j = 0; j < size; j += increment) {
memory[j] += j;
}
}
我们测试一下,在下表中, 表头是步长,也就是每次跳多少个整数,而纵向是这个数组可以跳几次(你可以理解为要几条Cache Line),于是表中的任何一项代表了这个数组有多少,而且步长是多少。比如:横轴是 512,纵轴是4,意思是,这个数组有 4*512 = 2048 个长度,访问时按512步长访问,也就是访问其中的这几项:[0, 512, 1024, 1536] 这四项。
表中同的项是,是循环1000万次的时间,单位是“微秒”(除以1000后是毫秒)
| count | 1 | 16 | 512 | 1024 |
------------------------------------------
| 1 | 17539 | 16726 | 15143 | 14477 |
| 2 | 15420 | 14648 | 13552 | 13343 |
| 3 | 14716 | 14463 | 15086 | 17509 |
| 4 | 18976 | 18829 | 18961 | 21645 |
| 5 | 23693 | 23436 | 74349 | 29796 |
| 6 | 23264 | 23707 | 27005 | 44103 |
| 7 | 28574 | 28979 | 33169 | 58759 |
| 8 | 33155 | 34405 | 39339 | 65182 |
| 9 | 37088 | 37788 | 49863 |156745 |
| 10 | 41543 | 42103 | 58533 |215278 |
| 11 | 47638 | 50329 | 66620 |335603 |
| 12 | 49759 | 51228 | 75087 |305075 |
| 13 | 53938 | 53924 | 77790 |366879 |
| 14 | 58422 | 59565 | 90501 |466368 |
| 15 | 62161 | 64129 | 90814 |525780 |
| 16 | 67061 | 66663 | 98734 |440558 |
| 17 | 71132 | 69753 |171203 |506631 |
| 18 | 74102 | 73130 |293947 |550920 |
我们可以看到,从 [9,1024] 以后,时间显著上升。包括 [17,512] 和 [18,512] 也显著上升。这是因为,我机器的 L1 Cache 是 32KB, 8 Way 的,前面说过,8 Way的有64组,每组8个Cache Line,当for-loop步长超过1024个整型,也就是正好 4096 Bytes时,也就是导致内存地址的变化是变化在高位的24bits上,而低位的12bits变化不大,尤其是中间6bits没有变化,导致全部命中同一组set,导致大量的cache 冲突,导致性能下降,时间上升。而 [16, 512]也是一样的,其中的几步开始导致L1 Cache开始冲突失效。
Reference
- https://en.wikipedia.org/wiki/CPU_cache
- https://coolshell.cn/articles/20793.html
- https://zhuanlan.zhihu.com/p/340534296
- https://github.com/cch123/golang-notes/blob/master/memory_barrier.md
- https://www.cs.utexas.edu/~bornholt/post/memory-models.html