通常对DB执行的增,删,改,查(CRUD)都是针对的系统的实体对象。如通过数据访问层获取数据,然后通过数据传输对象DTO传给表现层。或者,用户需要更新数据,通过DTO对象将数据传给Model,然后通过数据访问层写回数据库,系统中的所有交互都是和数据查询和存储有关,可以认为是数据驱动(Data-Driven)的,如下图:
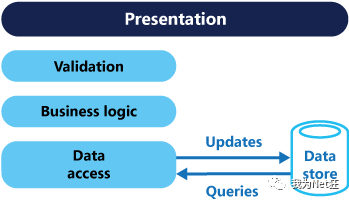
对于一些比较简单的系统,使用这种CRUD的设计方式能够满足要求。特别是通过一些代码生成工具及ORM等能够非常方便快速的实现功能。
但是传统的CRUD方法有一些问题:
- 使用同一个对象实体来进行数据库读写可能会太粗糙,大多数情况下,比如编辑的时候可能只需要更新个别字段,但是却需要将整个对象都穿进去,有些字段其实是不需要更新的。在查询的时候在表现层可能只需要个别字段,但是需要查询和返回整个实体对象。
- 使用同一实体对象对同一数据进行读写操作的时候,可能会遇到资源竞争的情况,经常要处理的锁的问题,在写入数据的时候,需要加锁。读取数据的时候需要判断是否允许脏读。这样使得系统的逻辑性和复杂性增加,并且会对系统吞吐量的增长会产生影响。
- 同步的,直接与数据库进行交互在大数据量同时访问的情况下可能会影响性能和响应性,并且可能会产生性能瓶颈。
- 由于同一实体对象都会在读写操作中用到,所以对于安全和权限的管理会变得比较复杂。
命令查询分离(Command Query Separation)
Bertrand Meyer 在 1988 年出版的《Object-Oriented Software Construction》一书中提出了“命令查询分离”的概念,这本书被认为是早期面向对象领域最具影响力的著作之一。
Meyer 说,The fundamental idea is that we should divide an object’s methods into two sharply separated categories:
- Queries: Return a result and do not change the observable state of the system (are free of side effects).
- Commands: Change the state of a system but do not return a value.
CQS is a simple concept: it is about methods within the same object being either queries or commands. Each method either returns state or mutates state, but not both. Even a single repository pattern object can comply with CQS.
CQS can be considered a foundational principle for CQRS.
CQS 其实也体现/遵循了单一职责原则(Single Resposibility Principle)。
不过,仍然会有一些特例逃逸于这个原则之外。比如,正如 Martin Fowler 所说的,从一个队列或栈弹出一个元素时,不仅改变了这个队列或栈,还返回了一个元素。
Meyer correctly says that you can avoid having this method, but it is a useful idiom. So I prefer to follow this principle when I can, but I’m prepared to break it to get my pop.
Command Query Responsibility Separation (CQRS)
CQS can be considered a foundational principle for CQRS.
Command and Query Responsibility Segregation (CQRS) was introduced by Greg Young and strongly promoted by Udi Dahan and others. It is based on the CQS principle, although it is more detailed. It can be considered a pattern based on commands and events plus optionally on asynchronous messages.
At its heart is the notion that you can use a different model to update information than the model you use to read information. For some situations, this separation can be valuable, but beware that for most systems CQRS adds risky complexity.
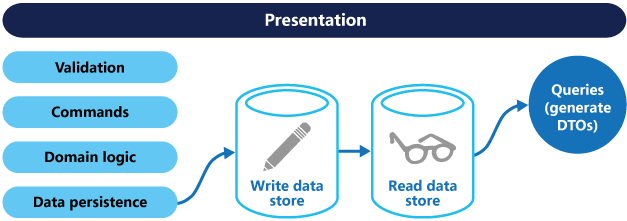
使用CQRS分离了读写职责之后,可以对数据进行读写分离操作来改进性能,可扩展性和安全。如下图:
主数据库处理CUD,从库处理R,从库的的结构可以和主库的结构完全一样,也可以不一样,从库主要用来进行只读的查询操作。在数量上从库的个数也可以根据查询的规模进行扩展,在业务逻辑上,也可以根据专题从主库中划分出不同的从库。从库也可以实现成ReportingDatabase,根据查询的业务需求,从主库中抽取一些必要的数据生成一系列查询报表来存储。
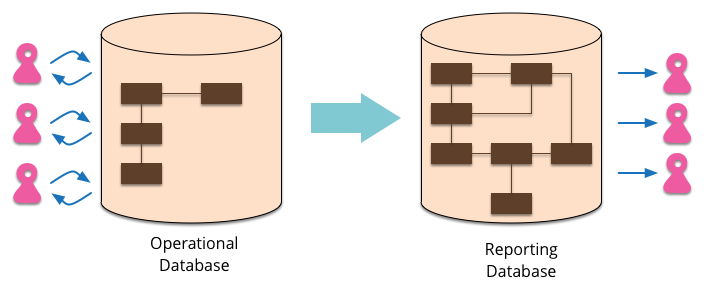
使用ReportingDatabase的一些优点通常可以使得查询变得更加简单高效:
- ReportingDatabase的结构和数据表会针对常用的查询请求进行设计。
- ReportingDatabase数据库通常会去正规化,存储一些冗余而减少必要的Join等联合查询操作,使得查询简化和高效,一些在主数据库中用不到的数据信息,在ReportingDatabase可以不用存储。
- 可以对ReportingDatabase重构优化,而不用去改变操作数据库。
- 对ReportingDatabase数据库的查询不会给操作数据库带来任何压力。
- 可以针对不同的查询请求建立不同的ReportingDatabase库。
Analysis
The mainstream approach people use for interacting with an information system is to treat it as a CRUD datastore. By this I mean that we have mental model of some record structure where we can create new records, read records, update existing records, and delete records when we’re done with them. In the simplest case, our interactions are all about storing and retrieving these records.
As our needs become more sophisticated we steadily move away from that model. We may want to look at the information in a different way to the record store, perhaps collapsing multiple records into one, or forming virtual records by combining information for different places. On the update side we may find validation rules that only allow certain combinations of data to be stored, or may even infer data to be stored that’s different from that we provide.
As this occurs we begin to see multiple representations of information. When users interact with the information they use various presentations of this information, each of which is a different representation. Developers typically build their own conceptual model which they use to manipulate the core elements of the model. If you’re using a Domain Model, then this is usually the conceptual representation of the domain. You typically also make the persistent storage as close to the conceptual model as you can.
This structure of multiple layers of representation can get quite complicated, but when people do this they still resolve it down to a single conceptual representation which acts as a conceptual integration point between all the presentations.
CQRS naturally fits with some other architectural patterns.
- As we move away from a single representation that we interact with via CRUD, we can easily move to a task-based UI.
- CQRS fits well with event-based programming models. It’s common to see CQRS system split into separate services communicating with Event Collaboration. This allows these services to easily take advantage of Event Sourcing.
- Having separate models raises questions about how hard to keep those models consistent, which raises the likelihood of using eventual consistency.
- For many domains, much of the logic is needed when you’re updating, so it may make sense to use EagerReadDerivation to simplify your query-side models.
- If the write model generates events for all updates, you can structure read models as EventPosters, allowing them to be MemoryImages and thus avoiding a lot of database interactions.
- CQRS is suited to complex domains, the kind that also benefit from Domain-Driven Design.
In many cases, CQRS is related to more advanced scenarios, like having a different physical database for reads (queries) than for writes (updates). Moreover, a more evolved CQRS system might implement Event-Sourcing (ES) for your updates database, so you would only store events in the domain model instead of storing the current-state data.
The separation aspect of CQRS is achieved by grouping query operations in one layer and commands in another layer. Each layer has its own data model (note that we say model, not necessarily a different database) and is built using its own combination of patterns and technologies. More importantly, the two layers can be within the same tier or microservice, as in the example (ordering microservice) used for this guide. Or they could be implemented on different microservices or processes so they can be optimized and scaled out separately without affecting one another.
The separation aspect of CQRS is achieved by grouping query operations in one layer and commands in another layer. Each layer has its own data model (note that we say model, not necessarily a different database) and is built using its own combination of patterns and technologies. More importantly, the two layers can be within the same tier or microservice, as in the example (ordering microservice) used for this guide. Or they could be implemented on different microservices or processes so they can be optimized and scaled out separately without affecting one another.
When to use it
Like any pattern, CQRS is useful in some places, but not in others. Many systems do fit a CRUD mental model, and so should be done in that style. CQRS is a significant mental leap for all concerned, so shouldn’t be tackled unless the benefit is worth the jump. While I have come across successful uses of CQRS, so far the majority of cases I’ve run into have not been so good, with CQRS seen as a significant force for getting a software system into serious difficulties.
In particular CQRS should only be used on specific portions of a system (a BoundedContext in DDD lingo) and not the system as a whole. In this way of thinking, each Bounded Context needs its own decisions on how it should be modeled.
So far I see benefits in two directions. Firstly is that a few complex domains may be easier to tackle by using CQRS. I must stress, however, that such suitability for CQRS is very much the minority case. Usually there’s enough overlap between the command and query sides that sharing a model is easier. Using CQRS on a domain that doesn’t match it will add complexity, thus reducing productivity and increasing risk.
The other main benefit is in handling high performance applications. CQRS allows you to separate the load from reads and writes allowing you to scale each independently. If your application sees a big disparity between reads and writes this is very handy. Even without that, you can apply different optimization strategies to the two sides. An example of this is using different database access techniques for read and update.
If your domain isn’t suited to CQRS, but you have demanding queries that add complexity or performance problems, remember that you can still use a ReportingDatabase. CQRS uses a separate model for all queries. With a reporting database you still use your main system for most queries, but offload the more demanding ones to the reporting database.
Despite these benefits, you should be very cautious about using CQRS. Many information systems fit well with the notion of an information base that is updated in the same way that it’s read, adding CQRS to such a system can add significant complexity. I’ve certainly seen cases where it’s made a significant drag on productivity, adding an unwarranted amount of risk to the project, even in the hands of a capable team. So while CQRS is a pattern that’s good to have in the toolbox, beware that it is difficult to use well and you can easily chop off important bits if you mishandle it.
CQRS and DDD patterns are not top-level architectures
It’s important to understand that CQRS and most DDD patterns (like DDD layers or a domain model with aggregates) are not architectural styles, but only architecture patterns. Microservices, SOA, and event-driven architecture (EDA) are examples of architectural styles. They describe a system of many components, such as many microservices. CQRS and DDD patterns describe something inside a single system or component; in this case, something inside a microservice.
Different Bounded Contexts (BCs) will employ different patterns. They have different responsibilities, and that leads to different solutions. It is worth emphasizing that forcing the same pattern everywhere leads to failure. Do not use CQRS and DDD patterns everywhere. Many subsystems, BCs, or microservices are simpler and can be implemented more easily using simple CRUD services or using another approach.
There is only one application architecture: the architecture of the system or end-to-end application you are designing (for example, the microservices architecture). However, the design of each Bounded Context or microservice within that application reflects its own tradeoffs and internal design decisions at an architecture patterns level. Do not try to apply the same architectural patterns as CQRS or DDD everywhere.
CQRS 架构
CQRS 建议将应用程序层分为两个方面,即命令端(Command)和查询端(Query)。
查询端负责优化读取数据。从持久化层(通常是DB)获取数据,然后将它们映射到展现层表单,这些表单通常被标识为数据传输对象(DTO)。
命令端关注优化写入数据。命令执行各种用例,修改实体状态并将其持久化。
通过分离读写操作,我们提高了性能,并在系统中支持关注点分离原则。
本文介绍 3 种主要的 CQRS 架构实现。
单数据库 CQRS
单一数据库CQRS 模式没有正式名称,Mattew Renze 在他的课程Clean Architecture 中将其命名为单一数据库 CQRS,我也选择这个命名。
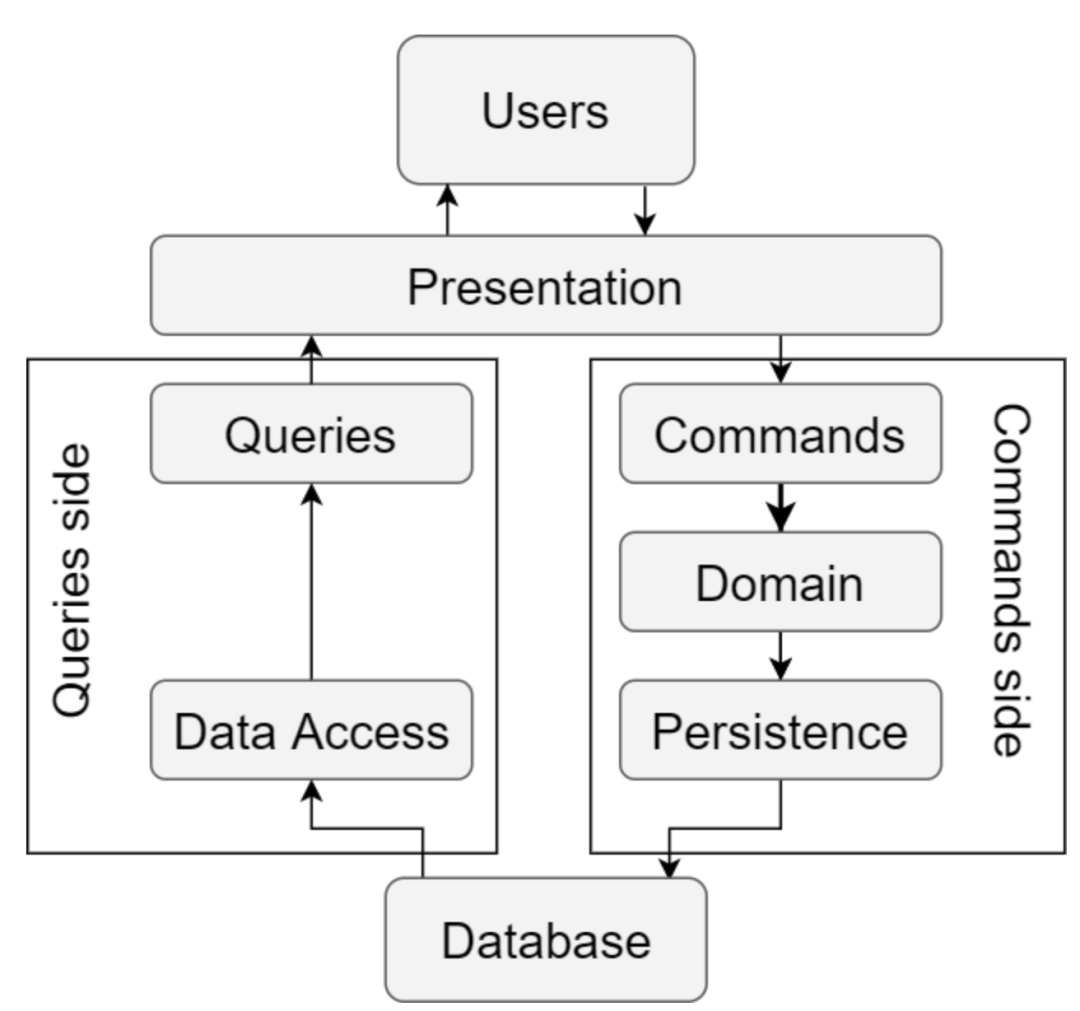
单数据库CQRS
顾名思义,双方都在和一个数据库对话。Command 在域中执行用例,从而修改实体的状态,然后通过 ORM 如 Entity Framework Core 或 Hibernate 将实体保存到数据库中。
Query 直接通过数据访问层执行,数据访问层要么是使用各种 ORM,要么通过存储过程。
双数据库 CQRS
在“双数据库”方式中,我们需要两个数据库,一个用于写操作,一个用于读操作。命令端使用针对写操作优化的数据库。查询端使用针对读取操作优化的数据库。
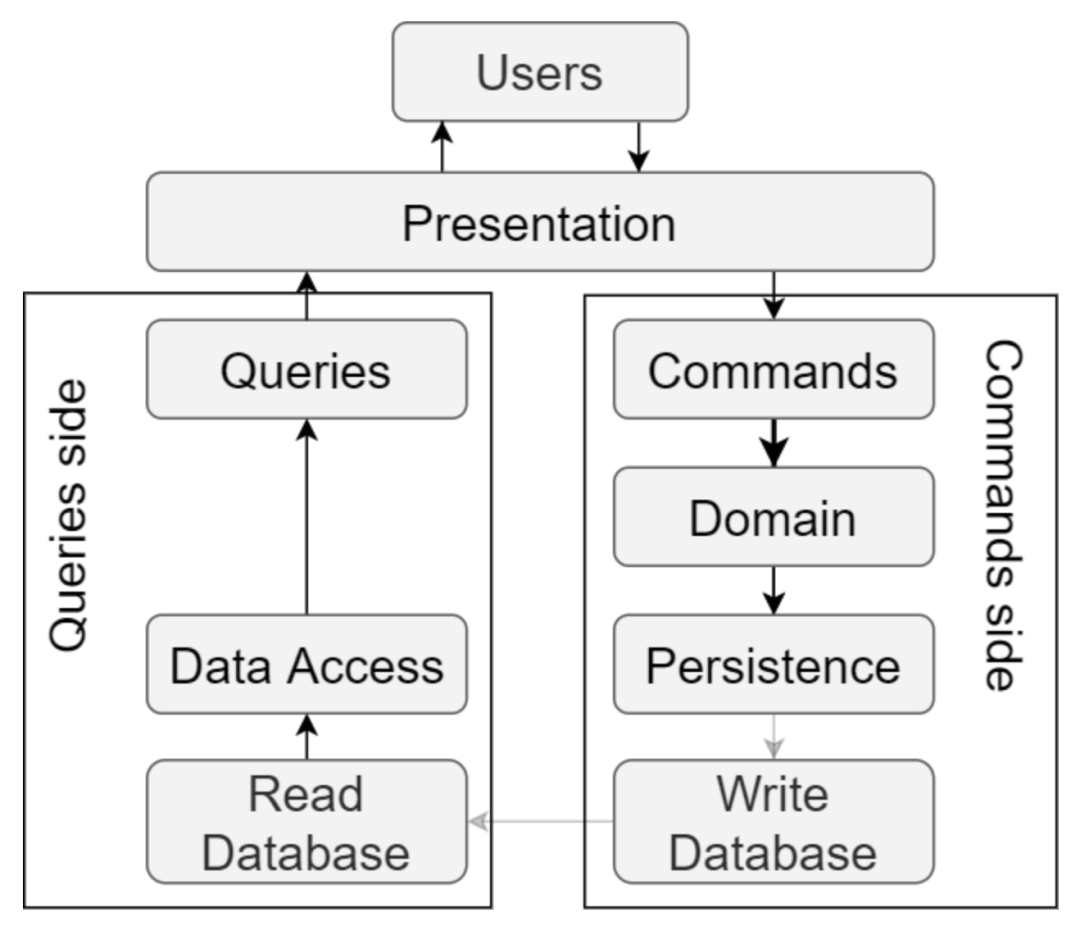
命令每改变一个状态,修改后的数据就必须从写数据库推送到读数据库中,或者作为一个跨两个数据库的分布式事务,或者使用最终一致性模型。
这种架构给软件的查询端带来了数量级的性能提升,这是有利的,因为一般系统在读数据上花费的时间一般比写数据要更多。
事件源 (Event source) CQRS
最后一种是最复杂的 CQRS 架构。与前面两种方式相比,事件源存储数据的思路完全不同。
在事件源方法中,我们并不只存储实体的当前状态,而且将实体发生的每一个状态作为快照来存储。实体并不是以标准化数据的形式保存,而是通过事件的时间戳来保存它们的变更。
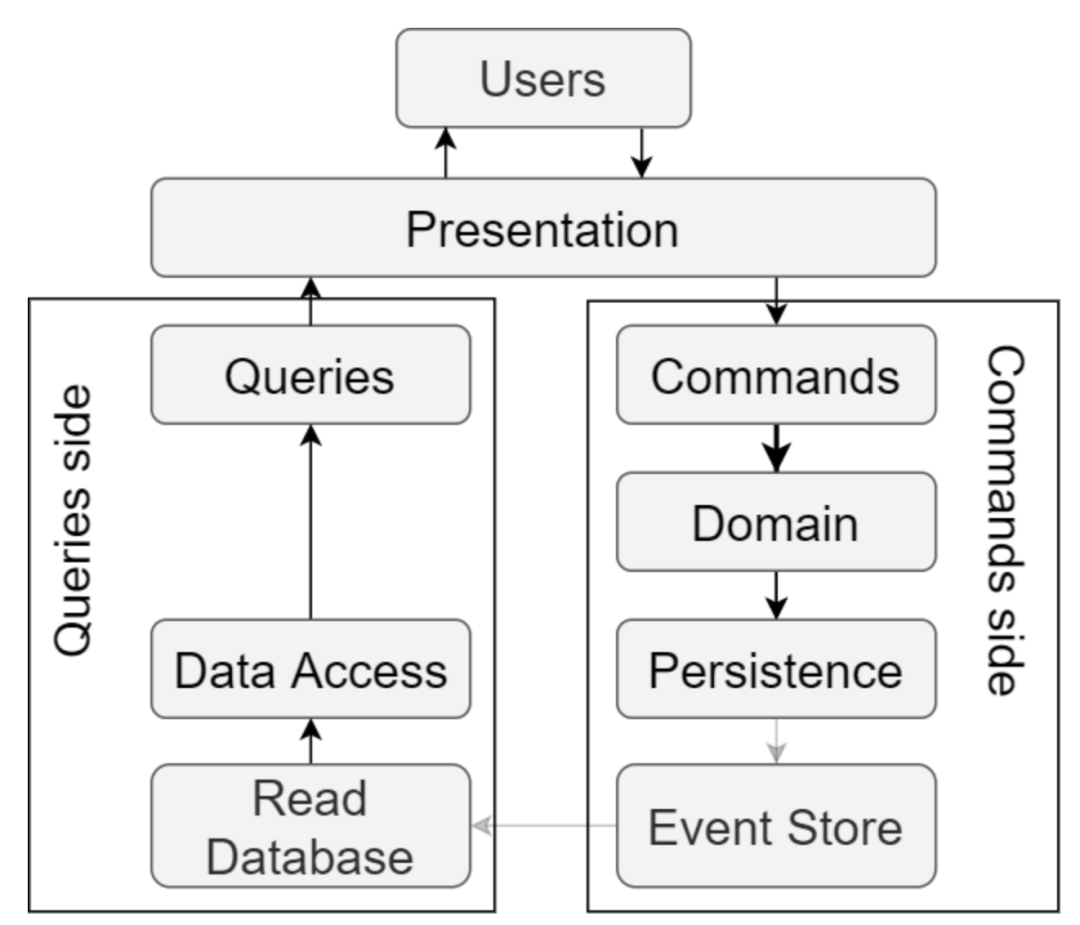
事件源带有以下好处:
- 事件存储包括完整的审计跟踪,可以在需要严格监管的场景中派上用场。
- 可以在任何时间点重建任何实体的任何状态,这对于调试非常有用。
- 可以重放事件,查看系统中任何时候到底发生了什么。这个功能对于压力测试和 bug 修复非常有用。
- 可以轻松地重建生产数据库。
- 有多个为读优化的数据存储。
但在另一方面,这种方式实现很复杂,如果你不能从其中受益,那么用这个模式可能适得其反。
小结
**CQRS 真正的威力在于可以对写和读操作进行不同的优化。**但在另一方面,系统会变得更加复杂,命令端和查询端代码不完全一致。并且由于存在多个数据库,管理更复杂,需要更繁琐的 ORM 映射。