编译原理(Fundamentals of Compiling)

词法分析(Lexical Analysis)- Lexer/Lexical Analyser
词法分析器(Lexical Analyzer, Lexer),也称为扫描器(Scanner),是编译器或解释器的组成部分之一。它的主要功能是读取源代码,将字符序列分解为标记(Tokens),以便语法分析器(Parser)进行进一步的处理。词法分析是编译过程中的第一步,负责处理源代码的字符流并生成标记流。
词法分析器的主要功能
- 读取输入字符流:从源代码中读取字符流。
- 识别标记:识别出语言中的基本构造,如关键字、标识符、常量、运算符、分隔符等。
- 跳过空白和注释:忽略空白字符(如空格、制表符、换行符)和注释。
- 生成标记流:将识别出的标记传递给语法分析器进行进一步处理。
词法分析器的工作流程
- 输入处理:读取输入字符流。
- 字符匹配:根据预定义的词法规则(正则表达式)匹配字符序列。
- 标记生成:将匹配到的字符序列转换为标记。
- 错误处理:检测并处理词法错误,如非法字符或未关闭的字符串常量等。
理解一下,词法分析就是处理原始的文本代码,得到编译程序内所定义的词法结构的序列,以供后续流程使用。假如我们使用 Golang 编写这个编译程序,我们为 tokens 定义如下结构:
const (
// TOKEN TYPE
RiskEngineLexerUSER = 1
RiskEngineLexerCONTAINS = 2
RiskEngineLexerAND = 3
RiskEngineLexerOR = 4
RiskEngineLexerDOUBLE_QUOTE = 5
RiskEngineLexerCOMMA = 6
RiskEngineLexerDOT = 7
RiskEngineLexerLT = 8
RiskEngineLexerLE = 9
RiskEngineLexerGT = 10
RiskEngineLexerGE = 11
RiskEngineLexerEQ = 12
RiskEngineLexerNE = 13
RiskEngineLexerDOLLAR = 14
RiskEngineLexerL_PAREN = 15
RiskEngineLexerR_PAREN = 16
RiskEngineLexerL_CURLY = 17
RiskEngineLexerR_CURLY = 18
RiskEngineLexerL_BRACKET = 19
RiskEngineLexerR_BRACKET = 20
RiskEngineLexerID = 21
RiskEngineLexerNUM_LIT = 22
RiskEngineLexerSTR_LIT = 23
RiskEngineLexerWS = 24
)
var (
LiteralNames = []string{
"", "'user'", "'contains'", "'and'", "'or'", "'\"'", "','", "'.'", "'<'",
"'<='", "'>'", "'>='", "'=='", "'!='", "'$'", "'('", "')'", "'{'", "'}'",
"'['", "']'",
}
)
type Token interface {
GetTokenType() int
GetText() string
GetLine() int
GetColumn() int
}
对于
user.riskLabels contains "单笔大额"
and user.totGame <= 5
and user.UID != ${targetUID}
and user.cpUID != ${targetUID}
and user.totSend(${targetUID}) >= 9999
在经过词法分析后,期望得到的 token 列表如下:(格式为 <text type line:col>)
<user 1 1:0> <. 7 1:4> <riskLabels 21 1:5> <contains 2 1:16> <"单笔大额" 23 1:25>
<and 3 2:0> <user 1 2:4> <. 7 2:8> <totGame 21 2:9> <<= 9 2:17> <5 22 2:20>
<and 3 3:0> <user 1 3:4> <. 7 3:8> <UID 21 3:9> <!= 13 3:13> <$ 14 3:16> <{ 17 3:17>
<targetUID 21 3:18> <} 18 3:27> <and 3 4:0> <user 1 4:4> <. 7 4:8> <cpUID 21 4:9>
<!= 13 4:15> <$ 14 4:18> <{ 17 4:19> <targetUID 21 4:20> <} 18 4:29> <and 3 5:0>
<user 1 5:4> <. 7 5:8> <totSend 21 5:9> <( 15 5:16> <$ 14 5:17> <{ 17 5:18>
<targetUID 21 5:19> <} 18 5:28> <) 16 5:29> <>= 11 5:31> <9999 22 5:34>
词法分析器的实现
词法分析器通常可以通过以下几种方式实现:
- 手工编写:直接使用编程语言手工编写词法分析器。这种方法适用于简单的词法分析需求,但对于复杂语言来说,编写和维护会变得困难。
- 词法分析生成器:使用自动化工具生成词法分析器,如 Lex(及其现代变种 Flex)、ANTLR 等。通过定义词法规则,工具可以自动生成相应的词法分析器代码。
词法分析生成器工具
Lex 和 Flex
Lex 是一种早期的词法分析生成器,常用于 Unix 系统上。Flex 是 Lex 的现代变种,提供了更高效和灵活的词法分析生成功能。
ANTLR
ANTLR(Another Tool for Language Recognition)是一个功能强大的解析器生成器,支持词法分析和语法分析的生成。它使用 .g4 文件来定义词法规则和语法规则。
语法分析(Syntax Analysis)- Parser
语法分析(Syntax Analysis),也称为解析(Parsing),是编译器和解释器中的一个重要步骤,其主要任务是根据语言的语法规则,将词法分析器生成的标记流(Token Stream)转换为语法树(Parse Tree)或抽象语法树(Abstract Syntax Tree, AST)。语法分析器负责检查标记流的结构是否符合语言的语法规则,并为后续的语义分析和代码生成打下基础。
语法分析的主要任务
- 验证语法结构:根据预定义的语法规则,验证标记流的结构是否正确。如果不正确,语法分析器会报告错误。
- 构建语法树:将标记流转换为语法树或抽象语法树,表示程序的结构和层次。
- 提供上下文信息:为后续的语义分析和代码生成提供必要的上下文信息。
语法分析的工作流程
- 接收标记流:从词法分析器接收标记流。
- 应用语法规则:根据语言的语法规则,逐个处理标记,并构建语法树。
- 报告错误:如果标记流的结构不符合语法规则,报告语法错误。
- 生成语法树:构建并输出语法树或抽象语法树。
语法解析器通常作为 编译器(Compiler)或解释器(Interpreter)出现。
抽象语法树是源代码结构的一种抽象表示,它以树的形状表示语言的语法结构。抽象语法树一般可以用来进行代码语法的检查,代码风格的检查,代码的格式化,代码的高亮,代码的错误提示以及代码的自动补全等等。

上图是样例的完整语法树,有些复杂,我们简化一下,看片段:user.totSend(${targetUID}) >= 9999
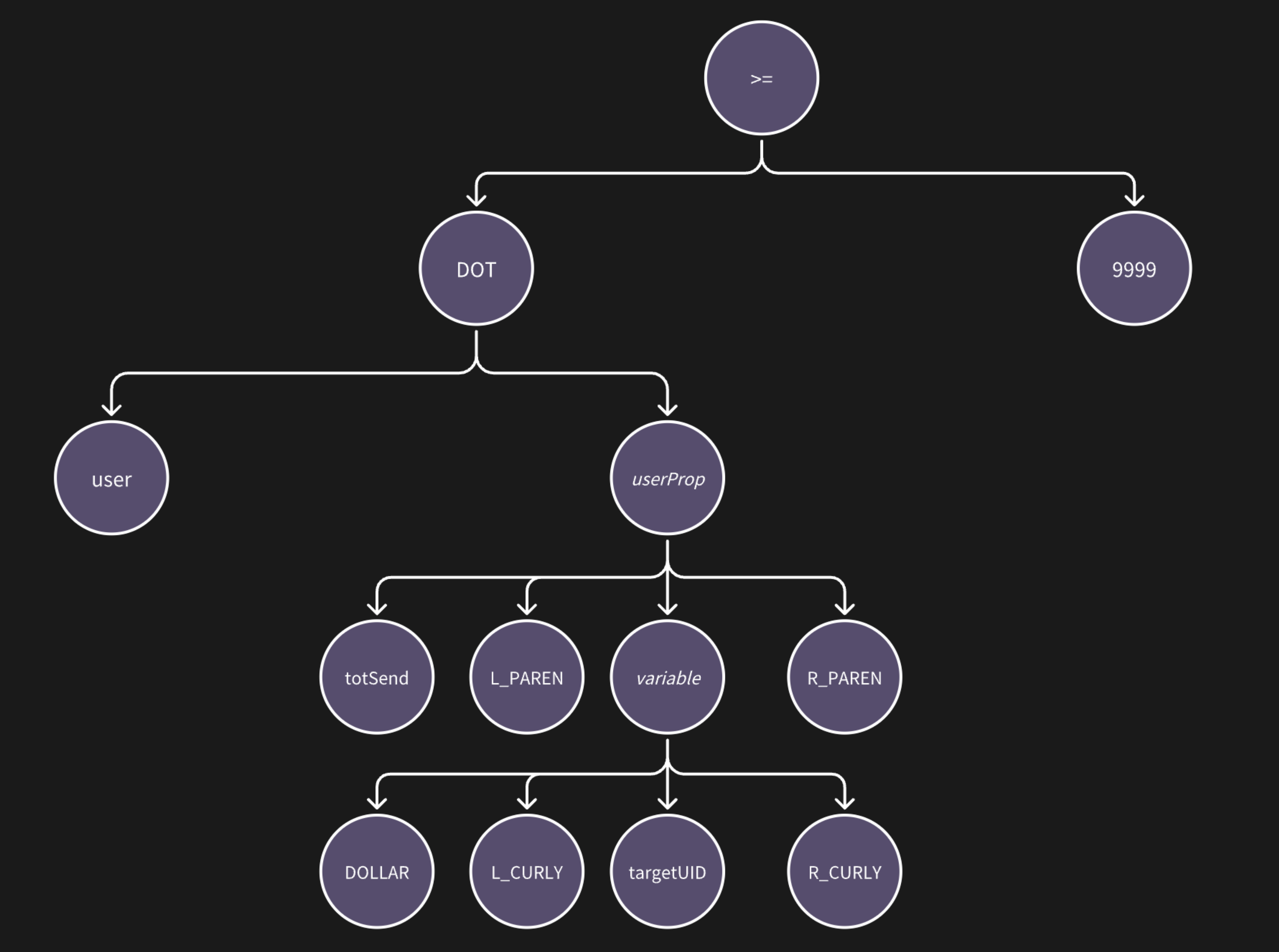
语法分析器的分类
语法分析器主要分为两类:自上而下(Top-Down Parsing)和自下而上(Bottom-Up Parsing)。
自上而下分析(Top-Down Parsing)
自上而下分析从语法规则的开始符号开始,试图将输入标记流解析为语法树。常见的自上而下分析方法有递归下降分析和预测分析。
- 递归下降分析:每个语法规则由一个递归函数实现,通过递归调用函数解析输入标记流。
- 预测分析(LL 分析):使用一个前瞻指针(Lookahead Pointer)在输入标记流中向前查看,选择适当的语法规则。
自下而上分析(Bottom-Up Parsing)
自下而上分析从输入标记流开始,逐步归约(Reduce)为语法规则的开始符号。常见的自下而上分析方法有 LR 分析和 LALR 分析。
• LR 分析:使用状态机和归约操作,通过移入(Shift)和归约操作解析输入标记流。
• LALR 分析:LALR(Look-Ahead LR)是 LR 分析的一种简化形式,具有更少的状态,适用于生成更小的解析表。
使用工具生成语法分析器
与手工编写词法分析器类似,语法分析器也可以使用工具自动生成。常见的语法分析器生成工具有 ANTLR、Bison、Yacc 等。
语义分析(Semantic Analysis)
语义分析(Semantic Analysis)是编译器或解释器的一个重要阶段,负责检查源代码的语义是否正确。语义分析在语法分析之后进行,它通过遍历抽象语法树(AST),进行类型检查、作用域检查和其他语义规则的验证,确保程序的逻辑和语义符合语言的规范和规则。
满足语法规则的语法树不一定满足语义规则,举个简单的例子:大多数编程语言中,赋值语句的语法规则是相同的,可以简化描述为 lhs = rhs,a = 1; a = "123" 是满足语法规则的,但它满足 Python 的语义规则,而不满足 C 的语义规则。
对于我们的样例来说,可以检查 totSend 的右值类型是否数字,contains 的左值类型是否列表且列表元素和右值类型相同 —— 当然,这些也可以完全跳过,推迟到运行时再检查。事实上,在风控策略引擎的场景中,我们编写的是解释器而非编译器,语义分析和解释执行一般是同时进行的,可以在一次对语法树的 DFS 过程完成。
语义分析的主要任务
- 类型检查:确保每个操作数和操作符的类型匹配,防止类型错误。例如,不能将整数赋值给字符串变量,或者对字符串进行算术运算。
- 作用域检查:验证变量和函数的声明和使用是否在正确的作用域范围内,防止使用未声明的变量或函数。
- 常量检查:确保常量的值在编译时是已知的,并且在正确的上下文中使用。
- 控制流检查:验证控制流语句(如循环、条件语句等)的正确性,确保没有不可能到达的代码或不正确的跳转。
- 名称解析:确保标识符(变量名、函数名等)在使用时能正确解析到它们的声明。
语义分析的实现
语义分析通过遍历抽象语法树(AST)来实现。通常会构建符号表(Symbol Table)来记录变量、函数和其他标识符的相关信息,并在分析过程中更新和查询符号表。
符号表(Symbol Table)
符号表是一个数据结构,用于存储标识符的名称、类型、作用域、值等信息。语义分析器在处理变量和函数声明时会将它们的信息添加到符号表中,在处理变量和函数使用时会查询符号表以验证其合法性。
以下是一个简单的语义分析器示例,展示了如何进行类型检查和作用域检查:
package main
import (
"errors"
"fmt"
)
// AST 节点类型
type NodeType int
const (
NodeTypeProgram NodeType = iota
NodeTypeVarDecl
NodeTypeAssignment
NodeTypePrint
NodeTypeIdentifier
NodeTypeInteger
)
// AST 节点
type ASTNode struct {
Type NodeType
Name string
Value int
Left *ASTNode
Right *ASTNode
}
// 符号表条目
type SymbolTableEntry struct {
Name string
Type string
Value int
}
// 符号表
type SymbolTable struct {
Entries map[string]*SymbolTableEntry
}
// 创建新的符号表
func NewSymbolTable() *SymbolTable {
return &SymbolTable{Entries: make(map[string]*SymbolTableEntry)}
}
// 添加符号表条目
func (st *SymbolTable) Add(entry *SymbolTableEntry) error {
if _, exists := st.Entries[entry.Name]; exists {
return errors.New("symbol already declared: " + entry.Name)
}
st.Entries[entry.Name] = entry
return nil
}
// 获取符号表条目
func (st *SymbolTable) Get(name string) (*SymbolTableEntry, error) {
entry, exists := st.Entries[name]
if !exists {
return nil, errors.New("symbol not found: " + name)
}
return entry, nil
}
// 语义分析器
type SemanticAnalyzer struct {
SymbolTable *SymbolTable
}
// 创建新的语义分析器
func NewSemanticAnalyzer() *SemanticAnalyzer {
return &SemanticAnalyzer{SymbolTable: NewSymbolTable()}
}
// 分析 AST
func (analyzer *SemanticAnalyzer) Analyze(node *ASTNode) error {
switch node.Type {
case NodeTypeProgram:
if err := analyzer.Analyze(node.Left); err != nil {
return err
}
case NodeTypeVarDecl:
entry := &SymbolTableEntry{Name: node.Name, Type: "int"}
if err := analyzer.SymbolTable.Add(entry); err != nil {
return err
}
case NodeTypeAssignment:
if _, err := analyzer.SymbolTable.Get(node.Name); err != nil {
return err
}
if err := analyzer.Analyze(node.Right); err != nil {
return err
}
case NodeTypePrint:
if err := analyzer.Analyze(node.Left); err != nil {
return err
}
case NodeTypeIdentifier:
if _, err := analyzer.SymbolTable.Get(node.Name); err != nil {
return err
}
case NodeTypeInteger:
// Do nothing for integer literals
default:
return errors.New("unknown node type")
}
return nil
}
func main() {
// 构建简单的 AST
program := &ASTNode{
Type: NodeTypeProgram,
Left: &ASTNode{
Type: NodeTypeVarDecl,
Name: "x",
Right: &ASTNode{
Type: NodeTypeAssignment,
Name: "x",
Right: &ASTNode{
Type: NodeTypeInteger,
Value: 42,
},
},
},
}
// 创建语义分析器并进行分析
analyzer := NewSemanticAnalyzer()
if err := analyzer.Analyze(program); err != nil {
fmt.Println("Semantic error:", err)
} else {
fmt.Println("Semantic analysis passed")
}
}
语义分析的过程
- 初始化符号表:在遍历 AST 之前,初始化符号表。
- 遍历 AST:对 AST 进行遍历,根据不同的节点类型执行相应的语义检查。
- 更新符号表:在遇到变量或函数声明时,将其信息添加到符号表中;在遇到变量或函数使用时,查询符号表并进行验证。
- 报告错误:如果发现语义错误,记录或报告错误信息。