数组既可以存储不可再分的数据元素(如数字 5、字符 ‘a’),也可以继续存储数组(即 n 维数组)。
但需要注意的是,以上两种数据存储形式绝不会出现在同一个数组中。例如,我们可以创建一个整形数组去存储 {1,2,3},我们也可以创建一个二维整形数组去存储
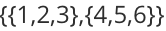
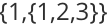
有人可能会说,创建一个二维s数组来存储
。在存储上确实可以实现,但无疑会造成存储空间的浪费。
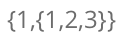
对于存储
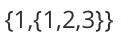
什么是广义表
广义表,又称列表,也是一种线性存储结构。
同数组类似,广义表中既可以存储不可再分的元素,也可以存储广义表,记作:
LS = (a1,a2,…,an)
其中,LS 代表广义表的名称,an 表示广义表存储的数据。广义表中每个 ai 既可以代表单个元素,也可以代表另一个广义表。
原子和子表
通常,广义表中存储的单个元素称为 “原子",而存储的广义表称为 “子表"。
例如创建一个广义表 LS =
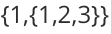
以下是广义表存储数据的一些常用形式:
- A = ():A 表示一个广义表,只不过表是空的。
- B = (e):广义表 B 中只有一个原子 e。
- C = (a,(b,c,d)) :广义表 C 中有两个元素,原子 a 和子表 (b,c,d)。
- D = (A,B,C):广义表 D 中存有 3 个子表,分别是A、B和C。这种表示方式等同于 D = ((),(e),(b,c,d)) 。
- E = (a,E):广义表 E 中有两个元素,原子 a 和它本身。这是一个递归广义表,等同于:E = (a,(a,(a,…)))。
注意,A = () 和 A = (()) 是不一样的。前者是空表,而后者是包含一个子表的广义表,只不过这个子表是空表。
广义表的表头和表尾
当广义表不是空表时,称第一个数据(原子或子表)为”表头",剩下的数据构成的新广义表为”表尾"。
强调一下,除非广义表为空表,否则广义表一定具有表头和表尾,且广义表的表尾一定是一个广义表。
例如在广义表中 LS=
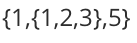
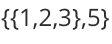
再比如,在广义表 LS = {1} 中,表头为原子 1 ,但由于广义表中无表尾元素,因此该表的表尾是一个空表,用 {} 表示。
广义表的存储结构
使用链表存储广义表
由于广义表中既可存储原子(不可再分的数据元素),也可以存储子表,因此很难使用顺序存储结构表示,通常情况下广义表结构采用链表实现。
使用顺序表实现广义表结构,不仅需要操作 n 维数组(例如
就需要使用三维数组存储),还会造成存储空间的浪费。
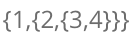
使用链表存储广义表,首先需要确定链表中节点的结构。由于广义表中可同时存储原子和子表两种形式的数据,因此链表节点的结构也有两种,如下图所示:
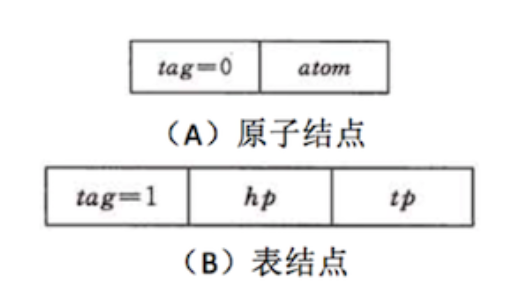
如上图所示,表示原子的节点由两部分构成,分别是 tag 标记位和原子的值,表示子表的节点由三部分构成,分别是 tag 标记位、hp 指针和 tp 指针。
tag 标记位用于区分此节点是原子还是子表,通常原子的 tag 值为 0,子表的 tag 值为 1。子表节点中的 hp 指针用于连接本子表中存储的原子或子表,tp 指针用于连接广义表中下一个原子或子表。
因此,广义表中两种节点的 C 语言表示代码为:
typedef struct GLNode{
int tag;//标志域
union{
char atom;//原子结点的值域
struct{
struct GLNode * hp,tp;
}ptr;//子表结点的指针域,hp指向表头;tp指向表尾
};
}Glist;
这里用到了 union 共用体,因为同一时间此节点不是原子节点就是子表节点,当表示原子节点时,就使用 atom 变量;反之则使用 ptr 结构体。
例如,广义表
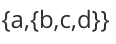
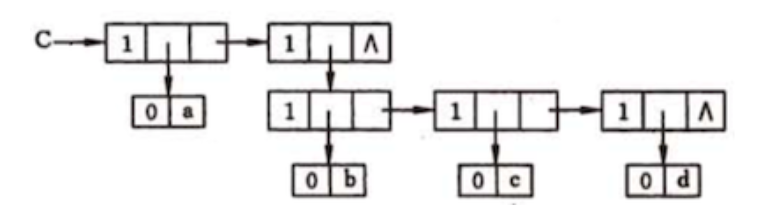
上图可以看到,存储原子 a、b、c、d 时都是用子表包裹着表示的,因为原子 a 和子表 {b,c,d} 在广义表中同属一级,而原子 b、c、d 也同属一级。
Reference
- 数据结构概述 - http://data.biancheng.net/intro/