串(String)
**串的基本概念:**串是由零个或多个任意字符组成的字符序列。
一般记作:s=‘a1 a2 an’。
- 其中s是串名,用单引号作为串的定界符,引号引起来的字符序列为串值,引号本身不属于串的内容;
- ai(1<=i<=n)是一个任意字符,可以是字母、数字或其它字符,它称为串的元素,是构成串的基本单位,i 是它在整个串中的序号; n为串的长度,表示串中所包含的字符个数,当n=0 时,称为空串,通常记为Ф 。
注意:空串和空白串是有区别的,我们将仅由一个或多个空格 组成的串称为空白串(Blank String)。
子串(Substring)
串中任意个连续字符组成的子序列称为该串的子串;包含子串的串相应地称为主串; 通常将子串在主串中首次出现时的该子串的首字符对应 的主串中的序号,定义为子串在主串中的位置。
例如,设A和B分别为 A=‘This is a string’ B=‘is’ 则B是A的子串,A为主串。B在A中出现了两次,其中首次出现所对应的主串位置是3。因此,称B在A中的位置为3。 特别地,空串是任意串的子串,任意串是其自身的子串。
串的抽象数据类型
ADT 串(string)
Data
串中元素仅由一个字符组成,相邻元素具有前驱和后继关系。
Operation
StrAssign(T, *chars): 生成一个其值等于字符串常量chars的串T。
StrCopy(T, S): 串S存在,由串S复制得串T。
ClearString(S): 串S存在,将串清空。
StringEmpty(S): 若串S为空,返回true,否则返回false。
StrLength(S): 返回串S的元素个数,即串的长度。
StrCompare(S, T): 若S>T,返回值>0,若S=T,返回0,若S<T,返回值<0。
Concat(T, S1, S2): 用T返回由S1和S2联接而成的新串。
SubString(Sub, S, pos, len): 串S存在,1≤pos≤StrLength(S),
且0≤len≤StrLength(S)-pos+1,用Sub返
回串S的第pos个字符起长度为len的子串。
Index(S, T, pos): 串S和T存在,T是非空串,1≤pos≤StrLength(S)。
若主串S中存在和串T值相同的子串,则返回它在主串S中
第pos个字符之后第一次出现的位置,否则返回0。
Replace(S, T, V): 串S、T和V存在,T是非空串。用V替换主串S中出现的所有
与T相等的不重叠的子串。
StrInsert(S, pos, T): 串S和T存在,1≤pos≤StrLength(S)+1。
在串S的第pos个字符之前插入串T。
StrDelete(S, pos, len): 串S存在,1≤pos≤StrLength(S)-len+1。
从串S中删除第pos个字符起长度为len的子串。
endADT
串的存储结构
串的定长顺序存储表示
我们知道,顺序存储结构(顺序表)的底层实现用的是数组,根据创建方式的不同,数组又可分为静态数组和动态数组,因此顺序存储结构的具体实现其实有两种方式。
通常所说的数组都指的是静态数组,如 str[10],静态数组的长度是固定的。与静态数组相对应的,还有动态数组,它使用 malloc 和 free 函数动态申请和释放空间,因此动态数组的长度是可变的。
这种存储结构又称为串的顺序存储结构,是用一组连续的存储单元来存放串中的字符序列。所谓定长顺序存储结构,是直接使用定长的字符数组来定义,数组的上界预先确定。
使用定长顺序存储结构存储字符串时,需结合目标字符串的长度,预先申请足够大的内存空间。
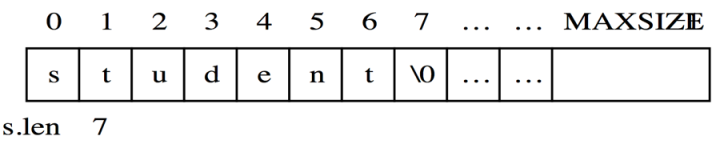
例如,采用定长顺序存储结构存储 “data.biancheng.net”,通过目测得知此字符串长度为 18(不包含结束符 ‘\0’),因此我们申请的数组空间长度至少为 18。
//定长顺序存储结构定义为:
#define MAX_STRLEN 256
typedef struct
{
char str[MAX_STRLEN] ;
int length;
}
定长数组存在一个预定义的最大串长度,一般可以将实际的串长度值保存在数组的0下标位置,也可以是在存储数组的最后一个下标位置。“\0”来表示串值的终结。
串的堆分配存储表示
但是,这样定长数组存储串是有问题的,串的两串的连接Concat、新串的插入StrInsert,以及字符串的替换Replace,都有可能使得串序列的长度超过了数组的长度Max-Size。
于是对于串的顺序存储,有一些变化,串值的存储空间可在程序执行过程中动态分配而得。比如在计算机中存在一个自由存储区,叫做**“堆”**。这个堆可由C语言的动态分配函数malloc()和free()来管理。
特点是:仍然以一组地址连续的存储空间来存储字符串值,但其所需的存储空间是在程序执行过程中动态分配,故是动态的,变长的。
//串的堆式存储结构的类型定义
typedef struct
{
char *ch; /* 若非空,按长度分配,否则为NULL */
int length; /* 串的长度 */
}
串的链式存储表示
串的链式存储结构,与线性表的链式存储结构是相似的。但由于串结构的特殊性,结构中的每个元素数据是一个字符,如果也简单的应用链表存储串值,一个结点对应一个字符,就会存在很大的空间浪费。
因此,一个结点可以存放一个字符,也可以存放多个字符,最后一个结点若是未被占满时,可以用“#”或其他非串值字符补全。
//(1) 块结点的类型定义
#define BLOCK_SIZE 4
typedef struct Blstrtype
{
char data[BLOCK_SIZE] ;
struct Blstrtype *next;
}BNODE ;
//(2) 块链串的类型定义
typedef struct
{
BNODE head; /* 头指针 */
int Strlen ; /* 当前长度 */
}
例如,下图所示是用链表存储字符串 shujujiegou,该链表各个节点中可存储 1 个字符:

同样,下图设置的链表各节点可存储 4 个字符:

从上图可以看到,使用链表存储字符串,其最后一个节点的数据域不一定会被字符串全部占满,对于这种情况,通常会用 ‘#’ 或其他特殊字符(能与字符串区分开就行)将最后一个节点填满。
一个结点存多少个字符才合适就变得很重要,这会直接影响着串处理的效率,需要根据实际情况做出选择。
串的链式存储结构除了在连接串与串操作时有一定方便之外,总的来说不如顺序存储灵活,性能也不如顺序存储结构好。
模式匹配/ 字符串匹配算法
字符串匹配
字符串匹配问题的形式定义:
- **文本(Text)**是一个长度为 n 的数组 T[1..n];
- **模式(Pattern)**是一个长度为 m 且 m≤n 的数组 P[1..m];
- T 和 P 中的元素都属于有限的字母表 Σ 表;
- 如果 0≤s≤n-m,并且 T[s+1..s+m] = P[1..m],即对 1≤j≤m,有 T[s+j] = P[j],则说模式 P 在文本 T 中出现且位移为 s,且称 s 是一个有效位移(Valid Shift)。
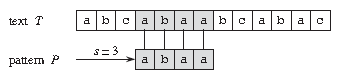
比如上图中,目标是找出所有在文本 T = abcabaabcabac 中模式 P = abaa 的所有出现。该模式在此文本中仅出现一次,即在位移 s = 3 处,位移 s = 3 是有效位移。
常见的字符串匹配算法
解决字符串匹配的算法包括:朴素算法(Naive Algorithm)、Rabin-Karp 算法、有限自动机算法(Finite Automation)、 Knuth-Morris-Pratt 算法(即 KMP Algorithm)、Boyer-Moore 算法、Simon 算法、Colussi 算法、Galil-Giancarlo 算法、Apostolico-Crochemore 算法、Horspool 算法和 Sunday 算法等。
字符串匹配算法的步骤
字符串匹配算法通常分为两个步骤:预处理(Preprocessing)和匹配(Matching)。所以算法的总运行时间为预处理和匹配的时间的总和。
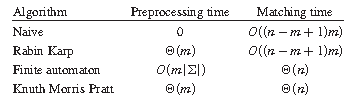
上图描述了常见字符串匹配算法的预处理和匹配时间。
Reference
- 数据结构-串 - https://zhuanlan.zhihu.com/p/29160321
- 数据结构之串 - https://www.zybuluo.com/guoxs/note/237408
- [数据结构]线性结构——串 - https://blog.csdn.net/shimazhuge/article/details/46808193
- 字符串匹配算法 - https://www.cnblogs.com/gaochundong/p/string_matching.html