背景
在海量大数据场景下,一张表中的部分业务数据随着时间的推移仅作为归档数据或者访问频率很低,同时这部分历史数据体量非常大,比如订单数据或者监控数据,降低这部分数据的存储成本将会极大的节省企业的成本。如何以极简的运维配置成本就能为企业极大降低存储成本。
How to define
一般而言,在判断一个数据到底是冷数据还是热数据时,我们主要采用主表里的 1 个或多个字段组合的方式作为区分标识。其中,这个字段可以是时间维度,比如“下单时间”这个字段,我们可以把 3 个月前的订单数据当作冷数据,3 个月内的当作热数据。
当然,这个字段也可以是状态维度,比如根据“订单状态”字段来区分,已完结的订单当作冷数据,未完结的订单当作热数据。
我们还可以采用组合字段的方式来区分,比如我们把下单时间 > 3 个月且状态为“已完结”的订单标识为冷数据,其他的当作热数据。
而在实际工作中,最终究竟使用哪种字段来判断,还是需要根据你的实际业务来定。
关于判断冷热数据的逻辑,这里还有 2 个注意要点必须说明:
- 如果一个数据被标识为冷数据,业务代码不会再对它进行写操作;
- 不会同时存在读冷/热数据的需求。
为表设置冷热分界线
比如,用户在使用过程中可以随时调整COLD_BOUNDARY来划分冷热的边界。COLD_BOUNDARY的单位为秒,如COLD_BOUNDARY => 86400 代表86400秒(一天)前写入的数据会被自动归档到冷存储介质上。
在冷热分离使用过程中,无需把列簇的属性设置为COLD,如果已经把列簇的属性设置为了COLD。
如何触发冷热数据分离
- 直接修改业务代码,每次修改数据时触发冷热分离(比如每次更新了订单的状态,就去触发这个逻辑);
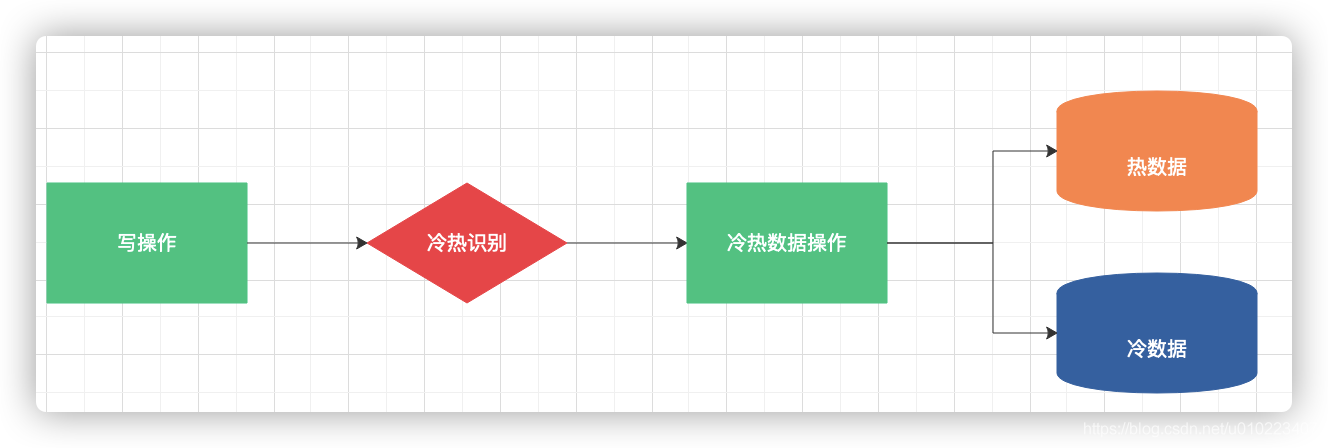
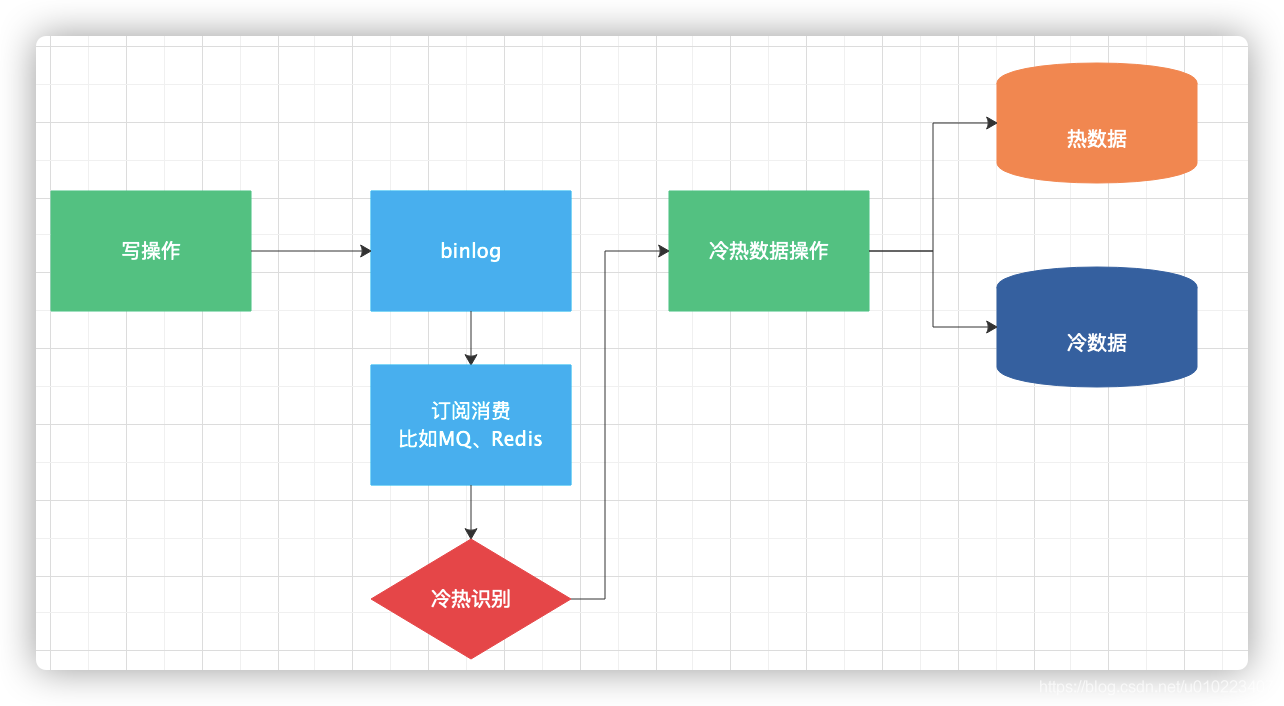
2、如果不想修改原来业务代码,可通过监听数据库变更日志 binlog 的方式来触发(数据库触发器也可);
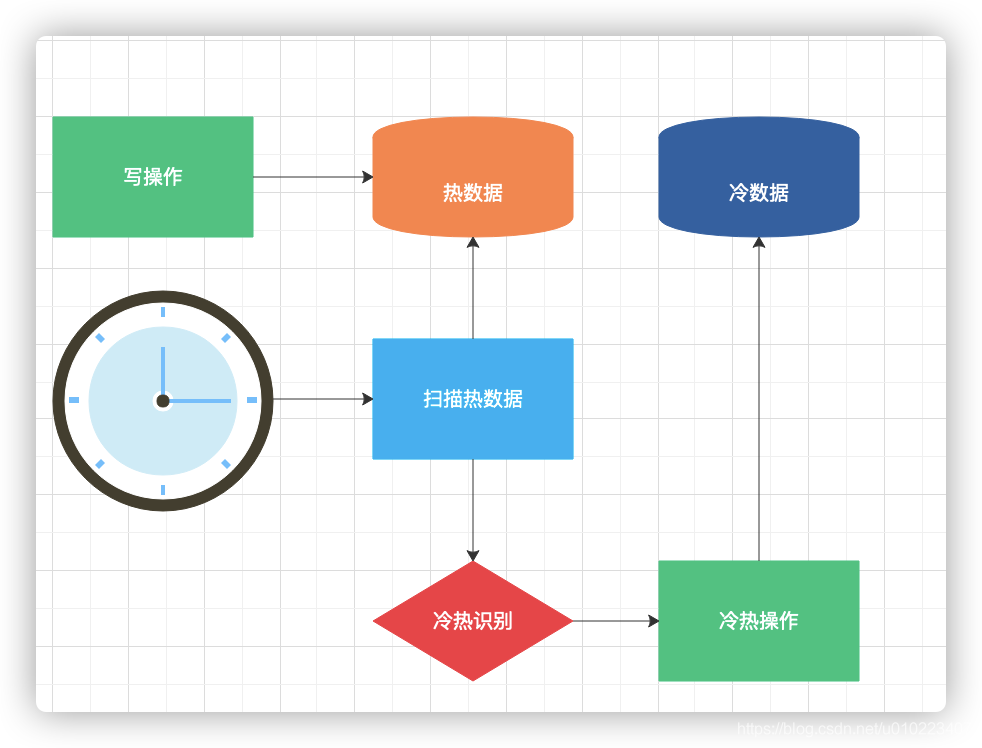
3、通过定时扫描数据的方式来触发(数据库定时任务或通过程序定时任务来触发);
针对以上三种触发逻辑,选择哪种比较好呢?看完以下表格的分析,你心里就有答案了。

根据表格内容对比,我们可以得出每种出发逻辑的建议场景。
- 修改写操作的业务代码:建议在业务代码比较简单,并且不按照时间区分冷热数据时使用。
- 监听数据库变更日志:建议在业务代码比较复杂,不能随意变更,并且不按照时间区分冷热数据时使用。
- 定时扫描数据库:建议在按照时间区分冷热数据时使用。
Reference
- https://help.aliyun.com/document_detail/135291.html
- https://xie.infoq.cn/article/abb660f7446fa8ddd99e7ae16