Background
A relational database management system provides data that represents a two-dimensional table of columns and rows. For example, a database might have this table:
| RowId | EmpId | Lastname | Firstname | Salary |
|---|---|---|---|---|
| 001 | 10 | Smith | Joe | 60000 |
| 002 | 12 | Jones | Mary | 80000 |
| 003 | 11 | Johnson | Cathy | 94000 |
| 004 | 22 | Jones | Bob | 55000 |
This simple table includes an employee identifier (EmpId), name fields (Lastname and Firstname) and a salary (Salary). This two-dimensional format is an abstraction. In an actual implementation, storage hardware requires the data to be serialized into one form or another.
The most expensive operations involving hard disks are seeks. In order to improve overall performance, related data should be stored in a fashion to minimize the number of seeks. This is known as locality of reference, and the basic concept appears in a number of different contexts. Hard disks are organized into a series of blocks of a fixed size, typically enough to store several rows of the table. By organizing the table’s data so rows fit within these blocks, and grouping related rows onto sequential blocks, the number of blocks that need to be read or sought is minimized in many cases, along with the number of seeks.
A survey by Pinnecke et al.[1] covers techniques for column-/row hybridization as of 2017.
Row-oriented systems
A common method of storing a table is to serialize each row of data, like this:
001:10,Smith,Joe,60000;
002:12,Jones,Mary,80000;
003:11,Johnson,Cathy,94000;
004:22,Jones,Bob,55000;
As data is inserted into the table, it is assigned an internal ID, the rowid that is used internally in the system to refer to data. In this case the records have sequential rowids independent of the user-assigned empid. In this example, the DBMS uses short integers to store rowids. In practice, larger numbers, 64-bit or 128-bit, are normally used.
Row-oriented systems are designed to efficiently return data for an entire row, or record, in as few operations as possible. This matches the common use-case where the system is attempting to retrieve information about a particular object, say the contact information for a user in a rolodex system, or product information for an online shopping system. By storing the record’s data in a single block on the disk, along with related records, the system can quickly retrieve records with a minimum of disk operations.
Row-oriented systems are not efficient at performing set-wide operations on the whole table, as opposed to a small number of specific records. For instance, in order to find all records in the example table with salaries between 40,000 and 50,000, the DBMS would have to fully scan through the entire table looking for matching records. While the example table shown above will likely fit in a single disk block, a table with even a few hundred rows would not, and multiple disk operations would be needed to retrieve the data and examine it.
To improve the performance of these sorts of operations (which are very common, and generally the point of using a DBMS), most DBMSs support the use of database indexes, which store all the values from a set of columns along with rowid pointers back into the original table. An index on the salary column would look something like this:
55000:004;
60000:001;
80000:002;
94000:003;
As they store only single pieces of data, rather than entire rows, indexes are generally much smaller than the main table stores. Scanning this smaller set of data reduces the number of disk operations. If the index is heavily used, it can dramatically reduce the time for common operations. However, maintaining indexes adds overhead to the system, especially when new data is written to the database. Records not only need to be stored in the main table, but any attached indexes have to be updated as well.
The main reason why indexes dramatically improve performance on large datasets is that database indexes on one or more columns are typically sorted by value, which makes range queries operations (like the above “find all records with salaries between 40,000 and 50,000” example) very fast (lower time-complexity).
A number of row-oriented databases are designed to fit entirely in RAM, an in-memory database. These systems do not depend on disk operations, and have equal-time access to the entire dataset. This reduces the need for indexes, as it requires the same amount of operations to fully scan the original data as a complete index for typical aggregation purposes. Such systems may be therefore simpler and smaller, but can only manage databases that will fit in memory.
Column-oriented systems
A column-oriented database serializes all of the values of a column together, then the values of the next column, and so on. For our example table, the data would be stored in this fashion:
10:001,12:002,11:003,22:004;
Smith:001,Jones:002,Johnson:003,Jones:004;
Joe:001,Mary:002,Cathy:003,Bob:004;
60000:001,80000:002,94000:003,55000:004;
In this layout, any one of the columns more closely matches the structure of an index in a row-oriented system. This may cause confusion that can lead to the mistaken belief a column-oriented store “is really just” a row-store with an index on every column. However, it is the mapping of the data that differs dramatically. In a row-oriented system, indices map column values to rowids, whereas in a column-oriented system, columns map rowids to column values. This may seem subtle, but the difference can be seen in this common modification to the same store wherein the two “Jones” items, above, are compressed into a single item with two rowids:
…;Smith:001;Jones:002,004;Johnson:003;…
Whether or not a column-oriented system will be more efficient in operation depends heavily on the workload being automated. Operations that retrieve all the data for a given object (the entire row) are slower. A row-oriented system can retrieve the row in a single disk read, whereas numerous disk operations to collect data from multiple columns are required from a columnar database. However, these whole-row operations are generally rare. In the majority of cases, only a limited subset of data is retrieved. In a rolodex application, for instance, collecting the first and last names from many rows to build a list of contacts is far more common than reading all data for any single address. This is even more true for writing data into the database, especially if the data tends to be “sparse” with many optional columns. For this reason, column stores have demonstrated excellent real-world performance in spite of many theoretical disadvantages.
Partitioning, indexing, caching, views, OLAP cubes, and transactional systems such as write-ahead logging or multiversion concurrency control all dramatically affect the physical organization of either system. That said, online transaction processing (OLTP)-focused RDBMS systems are more row-oriented, while online analytical processing (OLAP)-focused systems are a balance of row-oriented and column-oriented.
Column-oriented DBMS
Column-oriented databases save their data grouped by columns. Subsequent column values are stored contiguously on disk. This differs from the usual row-oriented approach of traditional databases, which store entire rows contiguously—see the Figure below for a visualization of the different physical layouts.
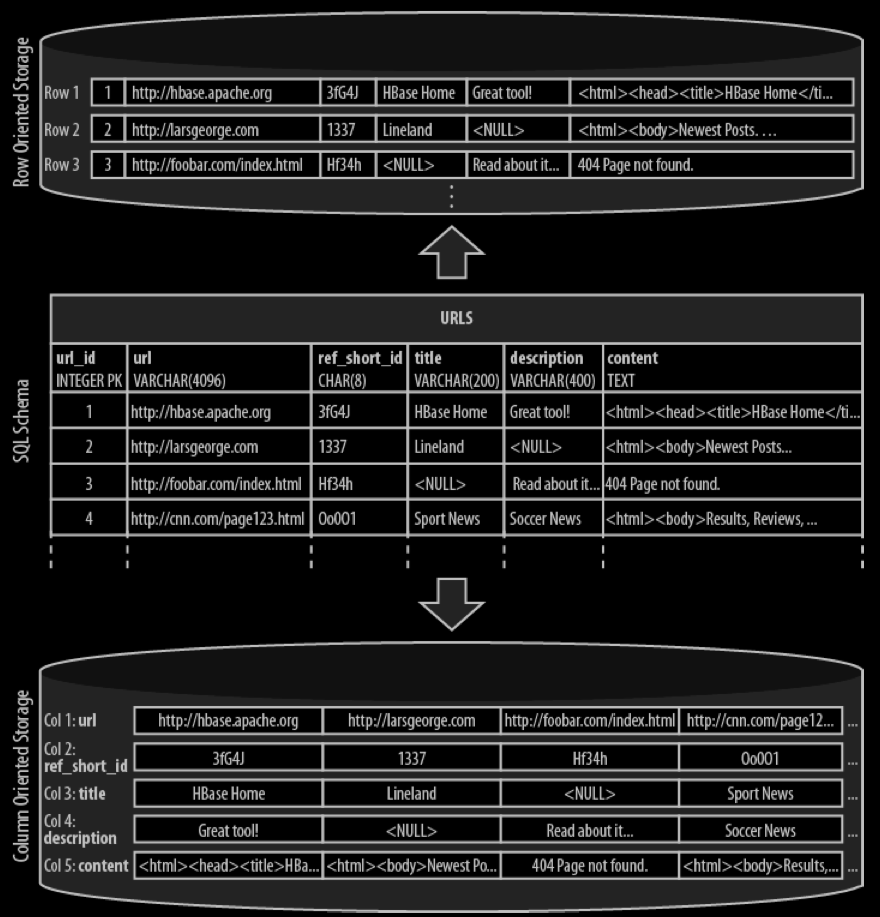
The reason to store values on a per-column basis instead is based on the assumption that, for specific queries, not all of the values are needed. This is often the case in analytical databases in particular, and therefore they are good candidates for this different storage schema.
Reduced I/O is one of the primary reasons for this new layout, but it offers additional advantages playing into the same category: since the values of one column are often very similar in nature or even vary only slightly between logical rows, they are often much better suited for compression than the heterogeneous values of a row-oriented record structure; most compression algorithms only look at a finite window.
Specialized algorithms—for example, delta and/or prefix compression—selected based on the type of the column (i.e., on the data stored) can yield huge improvements in compression ratios. Better ratios result in more efficient bandwidth usage.
Reference
- https://en.wikipedia.org/wiki/Column-oriented_DBMS
- HBase:The Definitive Guide
- https://dataschool.com/data-modeling-101/row-vs-column-oriented-databases/