Why is concurrency control needed?
If transactions are executed serially, i.e., sequentially with no overlap in time, no transaction concurrency exists.
However, if concurrent transactions with interleaving operations are allowed in an uncontrolled manner, some unexpected, undesirable results may occur, such as:
- The lost update problem
- The dirty read problem
- The incorrect summary problem
Most high-performance transactional systems need to run transactions concurrently to meet their performance requirements. Thus, without concurrency control such systems can neither provide correct results nor maintain their databases consistently.
Basic Idea
In information technology and computer science, especially in the fields of computer programming, operating systems, multiprocessors, and databases, concurrency control ensures that correct results for concurrent operations are generated, while getting those results as quickly as possible.
Introducing concurrency control into a system means applying operation constraints which typically result in some performance reduction.
Operation consistency and correctness should be achieved with as good as possible efficiency, without reducing performance below reasonable levels. Concurrency control can require significant additional complexity and overhead in a concurrent algorithm compared to the simpler sequential algorithm.
Concurrency Control Protocols
- Lock-based protocols - You can avoid them, by employing a pessimistic locking mechanism (e.g. Read/Write locks, Two-Phase Locking)
- Timestamp-based protocols - You can allow conflicts to occur, but you need to detect them using an optimistic locking mechanism (e.g. logical clock, MVCC)
Lock-based Protocols
Database systems equipped with lock-based protocols use a mechanism by which any transaction cannot read or write data until it acquires an appropriate lock on it. Data items can be locked in two modes:
-
Exclusive (X) mode: Data item can be both read as well as written. X-lock is requested using lock-X instruction.
-
Shared (S) mode: Data item can only be read. S-lock is requested using lock-S instruction.
Lock requests are made to the concurrency-control manager by the programmer. Transaction can proceed only after request is granted.
Timestamp-based Protocols
Lock-based protocols manage the order between the conflicting pairs among transactions at the time of execution, whereas timestamp-based protocols start working as soon as a transaction is created.
Every transaction has a timestamp associated with it, and the ordering is determined by the age of the transaction. A transaction created at 0002 clock time would be older than all other transactions that come after it. For example, any transaction ‘y’ entering the system at 0004 is two seconds younger and the priority would be given to the older one.
In addition, every data item is given the latest read and write-timestamp. This lets the system know when the last ‘read and write’ operation was performed on the data item.
Concurrency Control Mechanisms
Two-phase Locking (2PL)
Refer to https://swsmile.info/post/db-two-phase-locking/
Multiversion Concurrency Control (MVCC)
Locks incur contention, and contention impacts scalability. Researchers have studied complementary concurrency control mechanism to provide better performance and throughput while still preventing data integrity issues.
However, everything has a price, and MVCC is no different. MVCC is built on the assumption that Readers should not block Writers, and Writers should not block Readers. For this reason, shared locks are no longer employed, and transactions are allowed to modify entries that other concurrent transaction might have read in the meanwhile. So, MVCC takes an optimistic approach to resolving data integrity issues since conflicts can occur, but they need to be discovered prior to committing a given transaction.
Even if MVCC uses less locking than 2PL, exclusive locks are still acquired every time we modify a record since otherwise, dirty writes might happen, and atomicity would be compromised.
Going back to the example, when user A’s transaction requests data that user B is modifying, the database provides A with the version of that data that existed when user B started his transaction. User A gets a consistent view of the database even if other users are changing data. One implementation, namely snapshot isolation, relaxes the isolation property.
MVCC is a great concurrency control mechanism, but, because it does not use pessimistic Predicate or Range locks, it must detect anomalies by inspecting the currently running transaction schedule. This is a very complex task, and there might be edge cases when a database engine might not detect some anomaly that would otherwise be prevented by a 2PL-based concurrency control mechanism.
2PL vs MVCC
Comparison
When the ACID transaction properties were first defined, Serializability was assumed. And to provide a Strict Serializable transaction outcome, the 2PL (Two-Phase Locking) mechanism was employed. When using 2PL, every read requires a shared lock acquisition, while a write operation requires taking an exclusive lock.
- a shared lock blocks Writers, but it allows other Readers to acquire the same shared lock
- an exclusive lock blocks both Readers and Writers concurring for the same lock
However, locking incurs contention, and contention affects scalability. For this reason, database researchers have come up with a different Concurrency Control model which tries to reduce locking to a bare minimum so that:
- Readers don’t block Writers
- Writers don’t block Readers
The only use case that can still generate contention is when two concurrent transactions try to modify the same record since, once modified, a row is always locked until the transaction that modified this record either commits or rolls back.
In order to specify the aforementioned Reader/Writer non-locking behavior, the Concurrency Control mechanism must operate on multiple versions of the same record, hence this mechanism is called Multi-Version Concurrency Control (MVCC).
While 2PL is pretty much standard, there’s no standard MVCC implementation, each database taking a slightly different approach.
MVCC is a great concurrency control mechanism, but, because it does not use pessimistic Predicate lock or Range locks, it must detect anomalies by inspecting the currently running transaction schedule. This is a very complex task, and there might be edge cases when a database engine might not detect some anomaly that would otherwise be prevented by a 2PL-based concurrency control mechanism.
Usaga In different DBMSs
Unlike SQL Server which, by default, relies on the 2PL (Two-Phase Locking) to implement the SQL standard isolation levels, Oracle, PostgreSQL, and MySQL InnoDB engine use MVCC (Multi-Version Concurrency Control).
However, providing a truly Serializable isolation level on top of MVCC is really difficult, and, in this post, I’ll demonstrate that it’s very difficult to prevent the Phantom Read anomaly without resorting to pessimistic locking.
Pessimistic concurrency control
A pessimistic locking strategy assumes that the probability is high that another user will try to modify the same row in a table that you are changing.
A lock is held between the time a row is selected and the time that a searched update or delete operation is attempted on that row (for example, by using the repeatable read isolation level or lock the table in exclusive mode).
The advantage of pessimistic locking is that it is guaranteed that changes are made consistently and safely. The major disadvantage is that this locking strategy might not be very scalable.
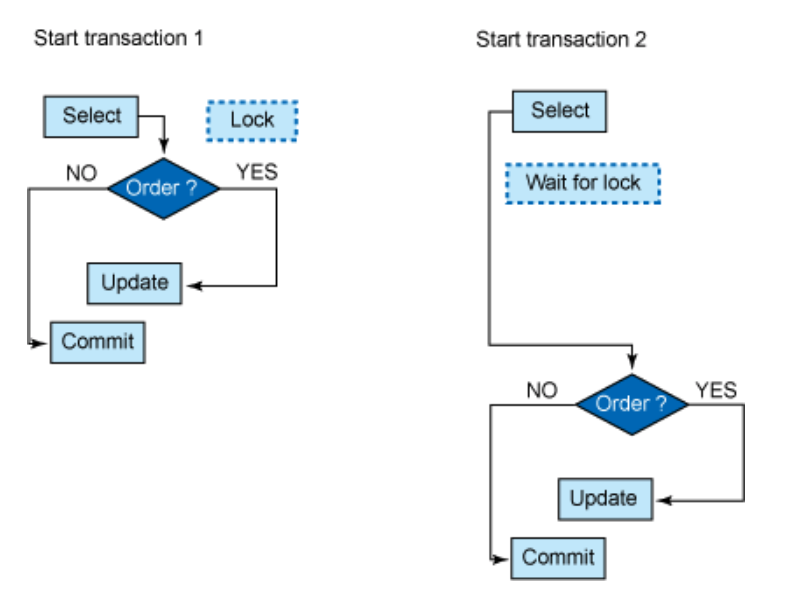
The figure above illustrates the functioning of pessimistic locking. Transaction 1 reads a specific record and places a lock on that row. It takes some time to decide whether the row will be updated. In the meantime, transaction 2 wants access to that same row, but it has to wait until the lock is released by Transaction 1. Until then, transaction 2 will receive results from its SELECT and can continue with its business logic.
- How does database pessimistic locking interact with INSERT, UPDATE, and DELETE SQL statements - https://vladmihalcea.com/how-does-database-pessimistic-locking-interact-with-insert-update-and-delete-sql-statements/
Optimistic Concurrency Control
One recommended method for preventing lost updates is to use optimistic concurrency control to perform what is called optimistic locking on the data.
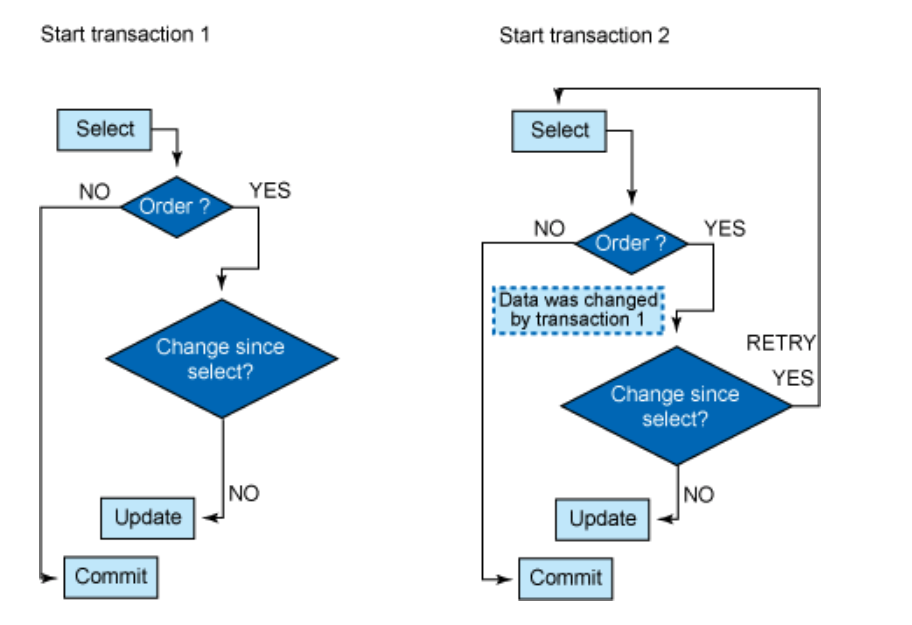
As shown in the figure above, transaction 1 reads a specific record but then releases its lock. Transaction 2 is now not prevented from retrieving that same row. Before committing the transaction, both transaction 1 and transaction 2 must check whether the row has changed after the previous SELECT. If a change has occurred, the transaction must restart with a new SELECT in order to retrieve the current data. However, if that row has not been changed after the previous SELECT, the data can be successfully updated.
In summary, Optimistic concurrency control typically uses four phases in order to help to ensure that data isn’t lost:
- Begin: A timestamp is recorded to pinpoint the beginning of the transaction.
- Modify: Read values and make writes tentatively.
- Validate: Make a check to ensure that other transactions have not modified any data that is used by the current transaction (including any transactions that have completed or are still active after the current transaction’s start time.
- Commit or rollback: If there are not conflicts, the transaction can be committed. Otherwise, the transaction can be aborted (or other resolution methods can be employed) to prevent a lost update from occurring.
Major goals of concurrency control mechanisms
Concurrency control mechanisms firstly need to operate correctly, i.e., to maintain each transaction’s integrity rules (as related to concurrency; application-specific integrity rule are out of the scope here) while transactions are running concurrently, and thus the integrity of the entire transactional system. Correctness needs to be achieved with as good performance as possible. In addition, increasingly a need exists to operate effectively while transactions are distributed over processes, computers, and computer networks. Other subjects that may affect concurrency control are recovery and replication.
- Correctness
- Serializability
- Recoverability
- Distribution
Reference
- Wikipedia Concurrency control - https://en.wikipedia.org/wiki/Concurrency_control
- Improve concurrency with DB2 9.5 optimistic locking - https://www.ibm.com/developerworks/data/library/techarticle/dm-0801schuetz/
- tutorialspoint DBMS - Concurrency Control - https://www.tutorialspoint.com/dbms/dbms_concurrency_control.htm
- A beginner’s guide to the Phantom Read anomaly, and how it differs between 2PL and MVCC - https://vladmihalcea.com/a-beginners-guide-to-the-phantom-read-anomaly-and-how-it-differs-between-2pl-and-mvcc/
- How does MVCC (Multi-Version Concurrency Control) work - https://vladmihalcea.com/how-does-mvcc-multi-version-concurrency-control-work/