Hash Tables
Refer to https://swsmile.info/post/data-structure-hash-table/
哈希索引(Hash Indexes)
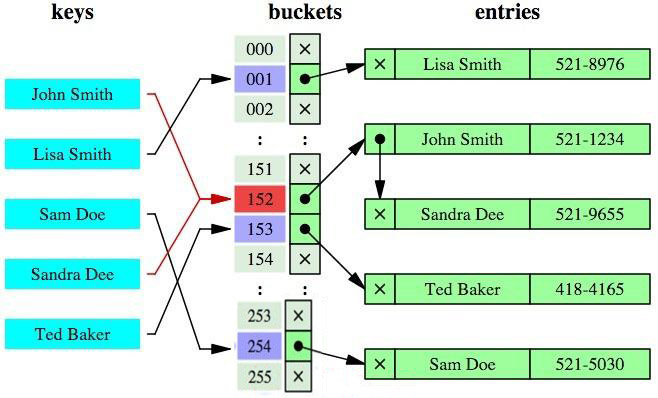
除了B+树之外,还有一种常见的是哈希索引。
哈希索引就是采用一定的哈希算法,以计算出键值的哈希值。因此,Hash 索引结构的检索效率非常高,因为索引的检索可以一次定位,不像B+树索引需要从根节点到枝节点,最后才能访问到页节点(这样会进行多次I/O访问),所以 Hash 索引的查询效率要远高于 B+树索引。
When to use hash indexes
Hash indexes are particularly useful when the key of the record being queried is known exactly. Its time complexity depends on the exact implementation and chosen hashing schemes that we already discussed, but it can be thought of as O(1) on average for inserts, lookups, and deletes. It may become O(n) in rare cases too. Its performance becomes really bad in case we have high collision rates. That’s why you need to be careful when deciding to build a hash index.
Examples of when it is useful:
- If you have a large database of cities and you want to quickly find the city with a given postal code, you can use a hash index on the postal code field to quickly look up the city.
- If you have a database of user accounts and you want to quickly find the password associated with a given email address, you can use a hash index on the email field to quickly look up the password.
- If you have a database of products and you want to quickly find the product with a given product code, you can use a hash index on the product code field to quickly look up the product.
Limitation
The hash table index also has limitations:
- The hash table must fit in memory, so if you have a very large number of keys, you’re out of luck. In principle, you could maintain a hash map on disk, but unfortunately it is difficult to make an on-disk hash map perform well. It requires a lot of random access I/O, it is expensive to grow when it becomes full, and hash collisions require fiddly logic.
- Range queries are not efficient. For example, you cannot easily scan over all keys between kitty00000 and kitty99999—you’d have to look up each key individually in the hash maps.
Hash Index Characteristics in MySQL
Hash indexes have somewhat different characteristics from those just discussed:
- They are used only for equality comparisons that use the
=or<=>operators (but are very fast). They are not used for comparison operators such as<that find a range of values. Systems that rely on this type of single-value lookup are known as “key-value stores”; to use MySQL for such applications, use hash indexes wherever possible. - The optimizer cannot use a hash index to speed up
ORDER BYoperations. (This type of index cannot be used to search for the next entry in order.) - MySQL cannot determine approximately how many rows there are between two values (this is used by the range optimizer to decide which index to use). This may affect some queries if you change a
MyISAMorInnoDBtable to a hash-indexedMEMORYtable. - Only whole keys can be used to search for a row. (With a B-tree index, any leftmost prefix of the key can be used to find rows.)
Reference
- https://en.wikipedia.org/wiki/Hash_table
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
- https://dev.mysql.com/doc/refman/8.0/en/index-btree-hash.html#hash-index-characteristics
- https://dev.mysql.com/doc/refman/8.0/en/index-btree-hash.html
- CMU15-445/645 Database Systems lecture notes. Retrieved from: 15445.courses.cs.cmu.edu/fall2022