Basic Idea
A transaction is an executing program that forms a logical unit of database processing.
A transaction includes one or more database access operations—these can include insertion, deletion, modification (update), or retrieval operations.
The database operations that form a transaction can either be embedded within an application program or they can be specified interactively via a high-level query language such as SQL.
If the database operations in a transaction do not update the database but only retrieve data, the transaction is called a read-only transaction; otherwise it is known as a read-write transaction.
Read and write Operation
Using this simplified database model, the basic database access operations that a transaction can include are as follows:
read_item(X). Reads a database item named X into a program variable. To simplify our notation, we assume that the program variable is also named X.write_item(X). Writes the value of program variable X into the database item named X.
As we know, the basic unit of data transfer from disk to main memory is one disk page (disk block).
Executing a read_item(X) command includes the following steps:
-
Find the address of the disk block that contains item X.
-
Copy that disk block into a buffer in main memory (if that disk block is not already in some main memory buffer). The size of the buffer is the same as the disk block size.
-
Copy item X from the buffer to the program variable named X.
Executing a write_item(X) command includes the following steps:
-
Find the address of the disk block that contains item X.
-
Copy that disk block into a buffer in main memory (if that disk block is not already in some main memory buffer).
-
Copy item X from the program variable named X into its correct location in the buffer.
-
Store the updated disk block from the buffer back to disk (either immediately or at some later point in time).
States of Transactions
A transaction in a database can be in one of the following states:
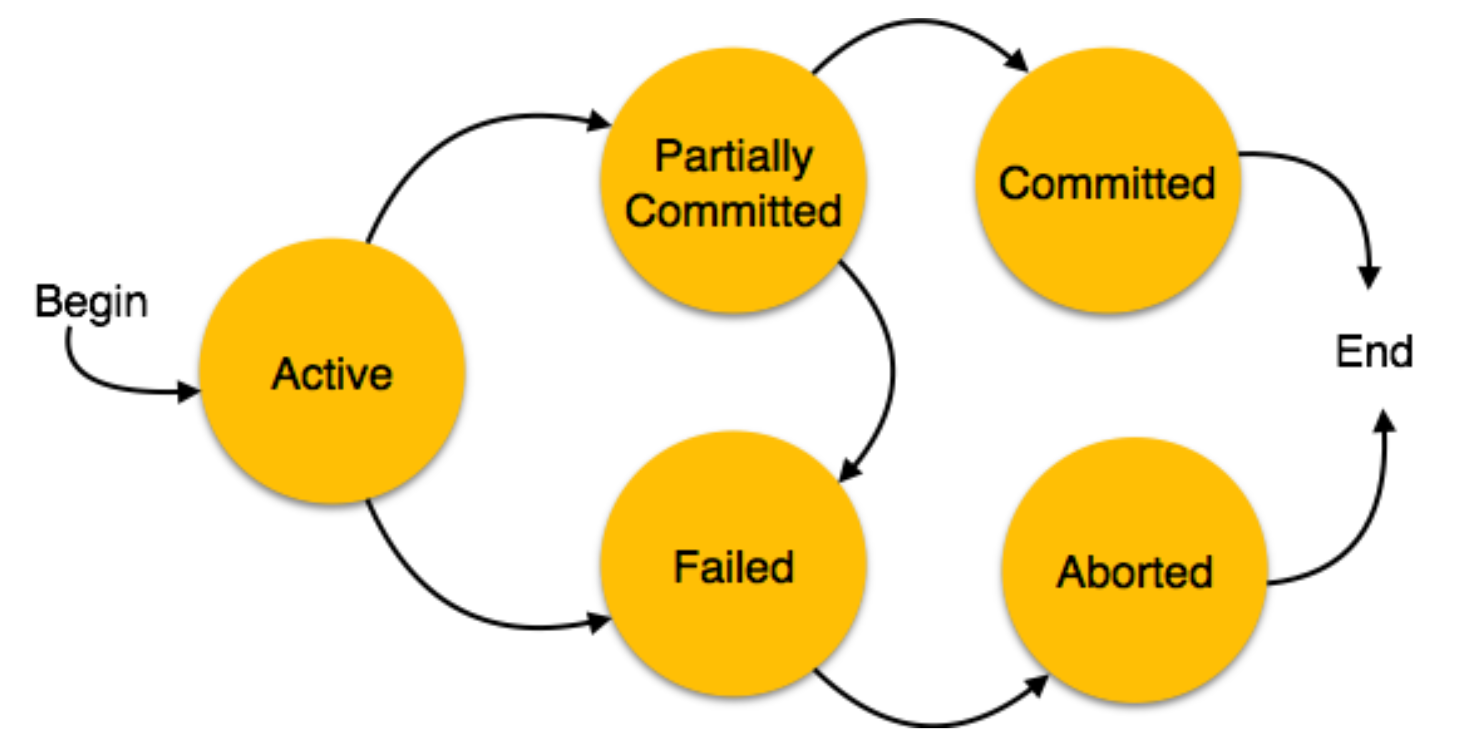
- Active − In this state, the transaction is being executed. This is the initial state of every transaction.
- Partially Committed − When a transaction executes its final operation, it is said to be in a partially committed state.
- Failed − A transaction is said to be in a failed state if any of the checks made by the database recovery system fails. A failed transaction can no longer proceed further.
- Aborted − If any of the checks fails and the transaction has reached a failed state, then the recovery manager rolls back all its write operations on the database to bring the database back to its original state where it was prior to the execution of the transaction. Transactions in this state are called aborted. The database recovery module can select one of the two operations after a transaction aborts
- Re-start the transaction
- Kill the transaction
- Committed − If a transaction executes all its operations successfully, it is said to be committed. All its effects are now permanently established on the database system.
Concurrency Control and Recovery Mechanisms
Concurrency control and recovery mechanisms are mainly concerned with the database commands in a transaction.
If transactions are executed serially, i.e., sequentially with no overlap in time, no transaction concurrency exists.
However, if concurrent transactions with interleaving operations are allowed in an uncontrolled manner, some unexpected, undesirable results may occur, such as:
- Lost update problem
- The dirty read (temporary update) problem
- Non-repeatable read
- Phantom reads
- Read Skew
- Write Skew
Most high-performance transactional systems need to run transactions concurrently to meet their performance requirements. Thus, without concurrency control such systems can neither provide correct results nor maintain their databases consistently.
Isolation Levels
Although some database management systems offer MVCC, usually concurrency control is achieved through locking. But as we all know, locking increases the serializable portion of the executed code, affecting parallelization.
For many database applications, the majority of database transactions can be constructed to avoid requiring high isolation levels (e.g. SERIALIZABLE level), thus reducing the locking overhead for the system. The programmer must carefully analyze database access code to ensure that any relaxation of isolation does not cause software bugs that are difficult to find. Conversely, if higher isolation levels are used, the possibility of deadlock is increased, which also requires careful analysis and programming techniques to avoid.
The SQL standard defines four Isolation levels:
- READ_UNCOMMITTED
- READ_COMMITTED
- REPEATABLE_READ
- SERIALIZABLE
All but the SERIALIZABLE level are subject to data anomalies (phenomena) that might occur according to the following pattern:
| Isolation Level | Lost updates | Dirty read | Non-repeatable read | Phantom read |
|---|---|---|---|---|
| READ_UNCOMMITTED | prevented | allowed | allowed | allowed |
| READ_COMMITTED | prevented | prevented | allowed | allowed |
| REPEATABLE_READ | prevented | prevented | prevented | allowed |
| SERIALIZABLE | prevented | prevented | prevented | prevented |
Reference
- Wikipedia Isolation - https://en.wikipedia.org/wiki/Isolation_(database_systems)
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems