聚集索引(Clustered Index)与非聚集索引(Non-clustered Index)
聚集索引(Clustered Index) - storing all row data within the index)
Clustering alters the data block into a certain distinct order to match the index, resulting in the row data being stored in order. Therefore, only one clustered index can be created on a given database table. Clustered indices can greatly increase overall speed of retrieval, but usually only where the data is accessed sequentially in the same or reverse order of the clustered index, or when a range of items is selected.
Since the physical records are in this sort order on disk, the next row item in the sequence is immediately before or after the last one, and so fewer data block reads are required. The primary feature of a clustered index is therefore the ordering of the physical data rows in accordance with the index blocks that point to them. Some databases separate the data and index blocks into separate files, others put two completely different data blocks within the same physical file(s).
非聚集索引(Non-clustered Index)- storing only references to the data within the index
The data is present in arbitrary order, but the logical ordering is specified by the index. The data rows may be spread throughout the table regardless of the value of the indexed column or expression. The non-clustered index tree contains the index keys in sorted order, with the leaf level of the index containing the pointer to the record (page and the row number in the data page in page-organized engines; row offset in file-organized engines).
In a non-clustered index,
- The physical order of the rows is not the same as the index order.
- The indexed columns are typically non-primary key columns used in JOIN, WHERE, and ORDER BY clauses.
There can be more than one non-clustered index on a database table.
索引数据的存储方式 - 聚集索引(聚簇索引,Clustered Index)
聚集索引(clustered index),也称为聚簇索引。
聚簇索引并不是一种单独的索引类型,而是一种索引数据的存储方式。
当表有聚簇索引时,它的行数据实际上存储在索引的叶子页(leaf page)中。因为无法同时把数据行存放在两个不同的地方,所以一张表只能有一个聚簇索引。
对于采用聚簇索引的存储引擎(比如MySQL的InnoDB),表中行的物理存储顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存储在磁盘上的。
下图展示了聚簇索引的记录是如何存放的。注意到,节点页只包含了索引列,叶子页包含该行的全部数据,这是B+Tree的数据结构:
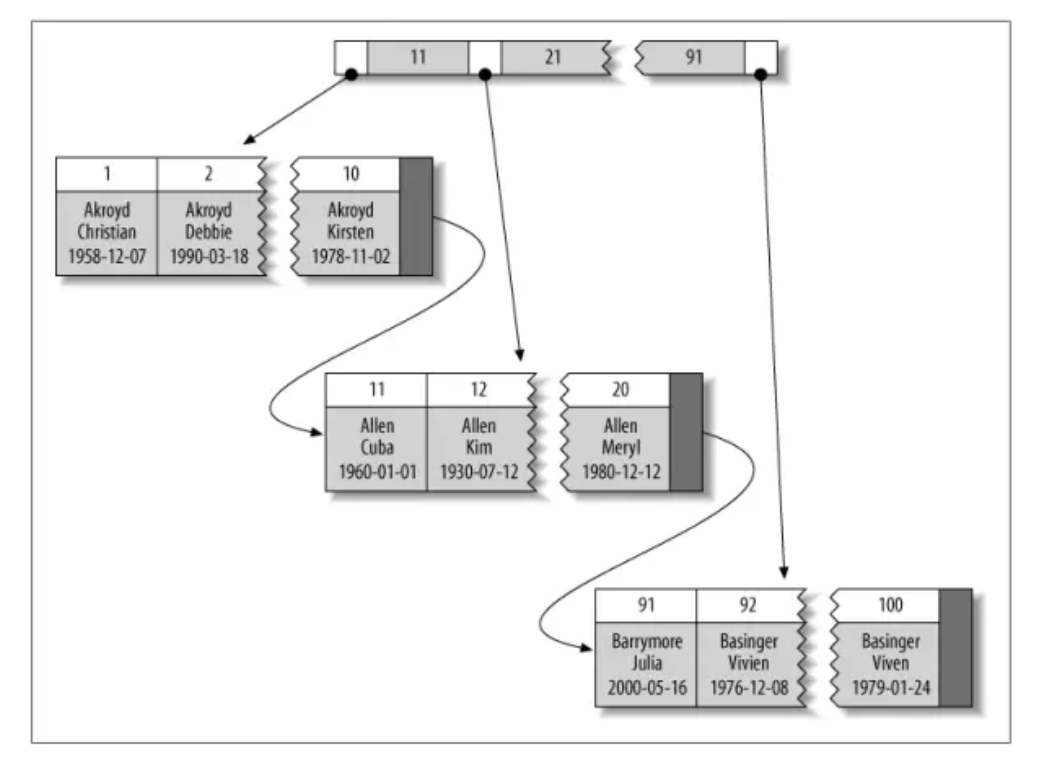
聚集索引通过主键聚集数据,上图中的“被索引的列”就是主键列。这意味着,聚集索引表同时也是数据表。
如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。
与非聚集索引相比,聚集索引通常提供更快的数据访问速度,且更适用于很少对基表进行增删改操作的场景。
优点
聚簇的数据有一些重要的优点:
- 可以把相关数据保存在一起。例如实现用户信息列表查询时,可以根据用户ID来聚集数据,这样只需要从磁盘读取少数的数据页就能获取多个用户的完整信息了(因为用户信息行数据的存储是基于用户 ID 连续存储的)。如果没有聚簇索引,则查询用户信息列表可能要进行多次磁盘 I/O(因为每个用户的用户信息数据在磁盘中存储的位置都是随机的)
- 数据访问更快。聚簇索引将索引和数据保存在同一个B+Tree中,因此从聚簇索引(或者说B+Tree)中获取数据通常比在非聚簇索引中查找要快(因为在非聚簇索引对应的索引表中,只存储了数据存储对应的地址,而不是存储数据本身)。
- 使用覆盖索引扫描的查询可以直接使用页节点中的主键值。
缺点
如果设计表和查询时能充分利用上面的优点,就能极大地提升性能。但是,聚簇索引也有一些缺点:
- 聚簇数据最大限度地提高了I/O密集型应用的性能,但如果数据全部放在内存中,则访问的顺序就没那么重要了,聚簇索引也就没什么优势了。
- 插入速度严重依赖于插入顺序。按照主要的顺序插入是加载数据到聚集索引表中速度最快的方式。但如果不是按照主键顺序加载数据,那么在加载完成后最好使用optimize table命令重新组织一下表。
- 更新聚簇索引列的代价很高,因为会强制聚集索引表将每个被更新的行移动到新的位置。
- 基于聚簇索引的表插入新行,或者主键被更新导致需要移动行的时候,可能面临”页分裂(page split)“的问题。当行的主键值要求必须将这一行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这就是一次分裂操作。页分裂会导致表占用更多的磁盘空间。
- 聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候。
- 聚簇索引中的二级索引(注意,聚簇索引中的二级索引是一个非聚簇索引)可能会比较大,因为在二级索引的叶子节点中包含了该行对应的主键。
- 聚簇索引中的二级索引的访问需要两次索引查找,而不是一次。因为,二级索引中的叶子节点保存的不是该行的物理存储地址(在非聚集索引中,二级索引中的叶子节点保存的是该行的物理存储地址),而是该行的主键值。这意味着,通过二级索引查找行时,存储引擎需要找到二级索引的叶子节点以获得对应的主键值,然后根据这个值去聚簇索引中查找到对应的行数据。
索引数据的存储方式 - 非聚集索引(非簇索引,Non-clustered Index)
非聚集索引(non-clustered index),也叫非簇索引。
对于采用非聚簇索引的存储引擎,表中数据行的物理存储顺序与索引顺序无关,叶子结点包含索引字段值及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。
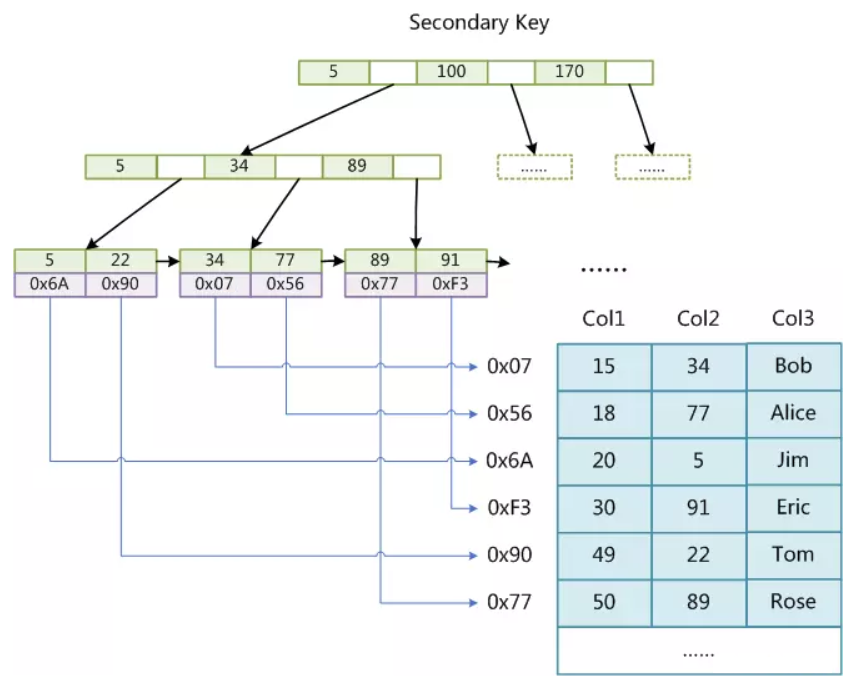
非聚集索引索引主键 - 主键索引(Primary Index)
在下图中,表一共有三列,假设以 col1 为主键,可以看出,该非聚集索引的叶子节点中保存的实际上是指向存放数据的物理块的指针。
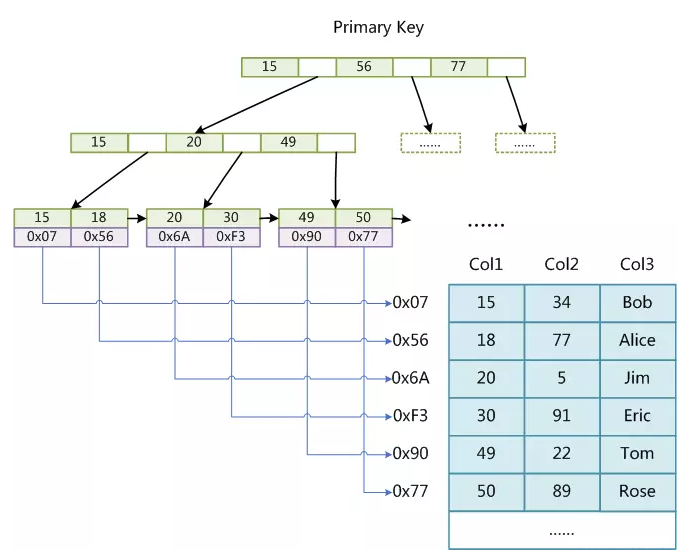
非聚集索引索引非主键 - 辅助索引(Secondary Index)
以对列 col2 (非主键列)进行索引为例。在这个非聚集索引(同时也是一个辅助索引(Secondary Index))中,每一个叶子节点中仅仅包含行号(row number),且叶子节点按照col2值的大小顺序进行存储。
注意到,数据表的数据存储顺序也与索引顺序无关。