读写分离(Read/Write Splitting)+ 主从复制(Master-slave Replication)
**读写分离(Read/Write Splitting)**的基本思想:让集群中的主数据库负责增(insert)、删(delete)和改(update)事务操作,而集群中的从数据库负责查询操作(select);并且,数据库后台会自动将因在主数据库中进行的事务操作导致的数据变更,同步到集群中的各个从数据库中。
MySQL的主从复制和MySQL的读写分离两者有着紧密联系,首先部署主从复制,只有主从复制完了,才能在此基础上进行数据的读写分离。简单来说,读写分离就是只在主服务器上写,只在从服务器上读,基本的原理是让主数据库处理事务性查询,而从数据库处理select查询。当业务量非常大时,一台服务器的性能无法满足需求,就可以通过配置主从复制实现写分离来分摊负载,避免因负载太高而造成无法及时响应请求。
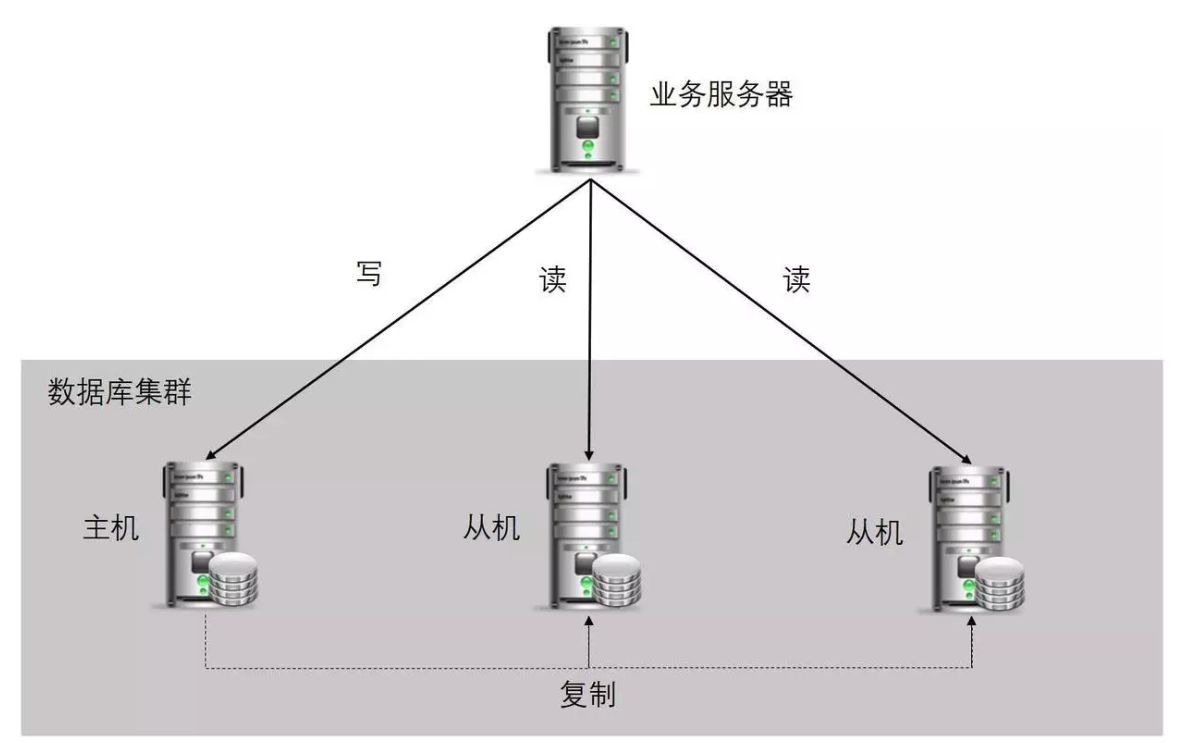
读写分离的方式,扩展了数据库对读数据的处理能力,但写能力并没有任何提升。
而且,数据库中单表的数据量是有限制的,当数据库中单表的数据量到达一定程度后,数据库的性能会显著下降。
使用原因
大部分互联网业务读多写少,数据库的读往往最先成为性能瓶颈,如果希望:
- 线性提升数据库读性能
- 通过消除读写锁冲突提升数据库写性能
此时可以使用分组架构。
一句话,分组主要解决“数据库读性能瓶颈”问题,在数据库扛不住读的时候,通常读写分离,通过增加从库线性提升系统读性能。
适用场景
读写分离适用与读远大于写的场景,如果只有一台服务器,当select很多时,update和delete会被这些select阻塞,因此并发性能不高。 对于写和读比例相近的应用,应该部署双主相互复制。
Reference
- 数据库读写分离架构,为什么我不喜欢 - http://www.10tiao.com/html/249/201801/2651960806/1.html
- MySQL读写分离最佳实践 - https://www.jianshu.com/p/1ac435a6510e
- 分库分表的几种常见形式以及可能遇到的难 - https://www.infoq.cn/article/key-steps-and-likely-problems-of-split-table
- 大众点评订单系统分库分表实践 - https://tech.meituan.com/2016/11/18/dianping-order-db-sharding.html
- MySQL 分库分表方案,总结的非常好! - https://juejin.im/entry/5b5eb7f2e51d4519700f7d3c
- 表的垂直拆分和水平拆分 - https://www.kancloud.cn/thinkphp/mysql-design-optimalize/39326
- 基于MySQL数据库下亿级数据的分库分表 - https://zhuanlan.zhihu.com/p/54594681?utm_source=wechat_session&utm_medium=social&utm_oi=559493336751333376&from=singlemessage&isappinstalled=0
FEATURED TAGS
algorithm
algorithmproblem
architecturalpattern
architecture
aws
blockchain
c#
cachesystem
codis
compile
concurrentcontrol
database
dataformat
datastructure
debug
design
designpattern
distributedsystem
django
docker
domain
engineering
freebsd
git
golang
grafana
hackintosh
hadoop
hardware
hexo
http
hugo
ios
iot
java
javaee
javascript
kafka
kubernetes
linux
linuxcommand
linuxio
lock
macos
markdown
microservices
mysql
nas
network
networkprogramming
nginx
node.js
npm
oop
openwrt
operatingsystem
padavan
performance
programming
prometheus
protobuf
python
redis
router
security
shell
software testing
spring
sql
systemdesign
truenas
ubuntu
vmware
vpn
windows
wmware
wordpress
xml
zookeeper