What Is Database Sharding?
Sharding is a method for distributing a single dataset across multiple databases, which can then be stored on multiple machines. This allows for larger datasets to be split in smaller chunks and stored in multiple data nodes, increasing the total storage capacity of the system.
Sharding is known as partitioning, and each smaller subsets called prtitions
Similarly, by distributing the data across multiple machines, a sharded database can handle more requests than a single machine can.
Sharding is a form of scaling known as horizontal scaling or scale-out, as additional nodes are brought on to share the load. Horizontal scaling allows for near-limitless scalability to handle big data and intense workloads. In contrast, vertical scaling refers to increasing the power of a single machine or single server through a more powerful CPU, increased RAM, or increased storage capacity.
什么时候会考虑分库分表
单库/表太大
- 单个数据库的能力已经达到瓶颈或者存在潜在瓶颈,比如
- Table row count > 10,000,000.
- Table size > 10GB.
- Performance bottleneck (e.g. Querying Response Time < 99%, i.e., more than 1% queries take more than 10ms).
- 单库太大,以至于所在服务器上磁盘空间不足
- 单库上操作出现了I/O瓶颈
解决方法:切分成更多更小的库或者表
水平分库分表(Horizontal Partitioning)
水平分库
当数据库中单表的数据量很大时,采用水平分区的方式对数据进行拆分(将同一个表中不同的数据拆分到不同数据库或同一个数据库的不同表中)。比如,以对某个主键进行hash取模的方式(以保证对N个数据库的访问负载是均衡的),将数据分布表到N个数据库或表中。
值得一提的是,进行分库分表后,进行对跨库的表join、事务操作或者数据统计、排序时,又出现了新的性能问题。
使用原因
大部分互联网业务数据量很大,单库容量容易成为瓶颈,如果希望:
- 线性降低单库数据容量
- 线性提升数据库写性能
此时可以使用水平切分架构。
一句话总结,水平切分主要解决“数据库数据量大”问题,在数据库容量扛不住的时候,通常水平分库。
水平分表
水平分表也称为横向分表,比较容易理解,就是将表中不同的数据行按照一定规律分布到不同的表中(这些表保存在同一个数据库中),这样来降低单表数据量。最常见的方式就是通过主键或者时间等字段进行 Hash 和取模后拆分。
分库还是分表?
- 是否存在夸库事务
- 如果存在事务,需要考虑处于该事务中的表通常需要在同一个库中,因为如果不处于同一个库中时,需要处理分布式事务,为了解决这个问题,不得不在进行sharding时,引入了较大的系统复杂度。
- 单库的I/O瓶颈
- 如果仅仅分表,由于这些表仍然处于同一个库,因而该库所在的物理机可能存在I/O瓶颈,通常是写瓶颈(因为read可能通过增加缓存或者slave的方式来解决)
- 是否存在join
- 如果关联的表处于不同库中,则不能通过数据库本身提供的join来完成联合查询,且进行联合查询的效率可能会很低,因为需要把大量的跨库数据先读到应用层,然后再应用层进行join
Sharding Factor
通常,需要结合业务来粗略估计数据的增长量,比如如果sharding factor 是1000,假设一个节点最大存储100万条数据,假设每一天的订单量是22万,则能存1000*100万/22万=12年左右的数据(当然,这里并没有考虑订单量的增加,并为其留出额外buffer)。
Shard by?
需要考虑的问题:
- 假如用户购买了商品,需要将交易记录保存取来。
- 如果按照用户的纬度分表,则每个用户的交易记录都保存在同一表中,所以很快很方便的能够查找到某用户的购买情况(by user_id),但是某商品被购买的情况则很有可能分布在多张表中,因而查找起来比较麻烦。
- 反之,按照商品维度分表(比如by item_id),可以很方便的查找到此商品的购买情况,但要查找特定用户的交易记录,则比较麻烦
1 mod(hash(identifier)) 切分
我们一般都采用这种方式进行 shard。
一个商场系统,一般都是将用户,订单作为主表,然后将和它们相关的作为附表,这样不会造成跨库事务之类的问题。 取用户id,然后hash取模,分配到不同的数据库上。
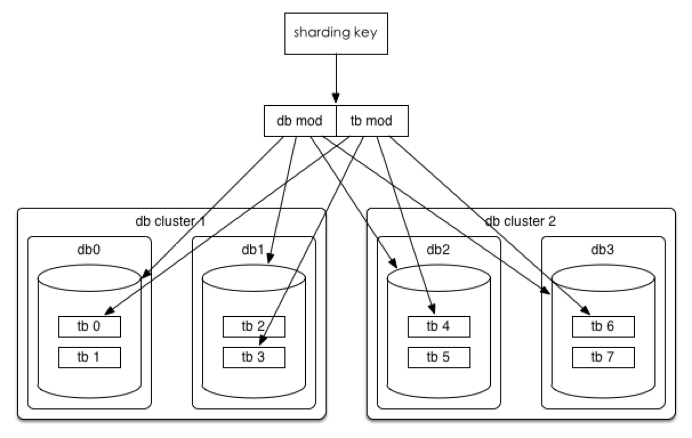
数据水平切分后我们希望是一劳永逸或者是易于水平扩展的,所以推荐采用 $mod 2^n$ 这种 consistent hashing。
以统一订单库为例,我们分库分表的方案是32 * 32 的,即通过 UserId后四位 mod 32 分到32个库中的其中一个库,同时再将 UserId后四位 Div 32 Mod 32将每个库分为32个表,共计分为1024张表。
当然,这里需要注意的是,如果按user_id来取模,可能出现data imbalance,即因为不同buyer购买下单的数量是不同的,而有的buyers下单的频率更高,因而出现不同 DB 节点的压力不同。
- sharding factor越大,相对来说data distribution 会越均匀
- If sharding based on string instead of auto-inc number, use e.g.
crc32(lower(\<string>)) % 32to ensure even distribution.
因而,同时也会考虑按checkout_id或者order_id来shard,这样每个DB节点的压力是几乎相同的。当然,如果这样做,查询一个特定user所下的订单时,就涉及了跨多库查询的问题。
采用这种方式,可以很大程度避免skew and hot spots,当然,这个问题仍然是存在的,比如如果shard by shop_id,因为热门店铺的订单的数量会大大多于一个普通店铺,因而如果sharding factor较小,还是可能出现skew and hot spots的情况。
2 查询 mapping table
将ID和库的Mapping关系记录在一个单独的库中。
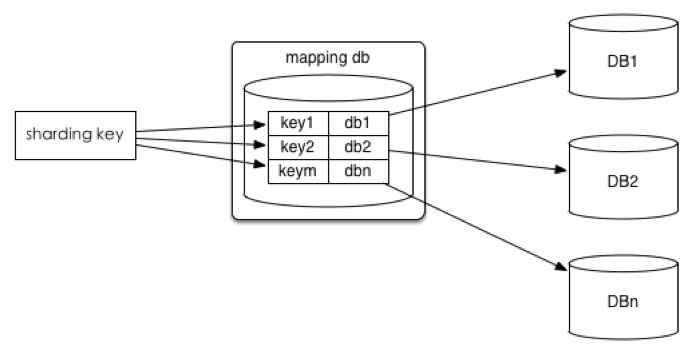
- 优点:ID和库的Mapping算法可以随意更改。
- 缺点:引入额外的单点。
2 范围切分(Range Based Sharding)
比如按照主键、order_id、checkout_id来切分。
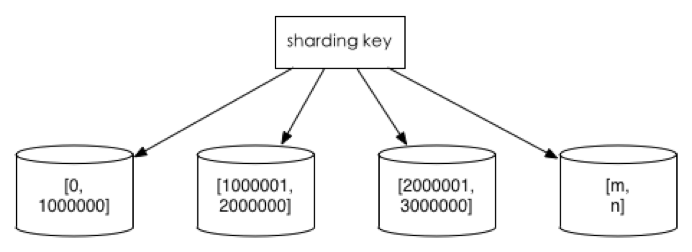
- 优点:单表大小可控,天然水平扩展。
- 缺点:无法解决集中写入瓶颈的问题,即 data skewed。
4 地理区域
比如按照华东,华南,华北这样来区分业务,七牛云应该就是如此。
*5 时间(chronological)
比如每个月的数据,都存在单独的一张表中
Example:
- txn_tab contains past 3 months of txns, with monthly sharding to txn_tab_yyyymm.
- It is currently 2016 Aug.
- Txns created 2016 Jun-Aug (past 3 months) are in txn_tab.
- Txns created 2016 May are in txn_tab_201605, and so on.
- Next month, txns created 2016 Jun will be moved to a newly created txn_tab_201606.
- User will be unable to see txns > 3 months ago, or be able to, but as a separate, slower operation (align this with business rules).
按照时间切分,即将1个月前,或者一年前的数据切出去放到另外的一张表,这称为archive,因为随着时间流逝,这些表的数据被查询的概率变小,所以没必要和“热数据”放在一起,这个也是“冷热数据分离”。
但是通过时间进行 shard通常是为了解决archive的问题,但会出现明显的hot spot问题,就bottleneck可能是某一个表,因为在当前时间附近产生的所有数据都会被写到同一个表中。
这种shard方式适用于存储低read低write的情况,比如audit信息。
垂直分表分库(Vertical Partitioning)
垂直分表
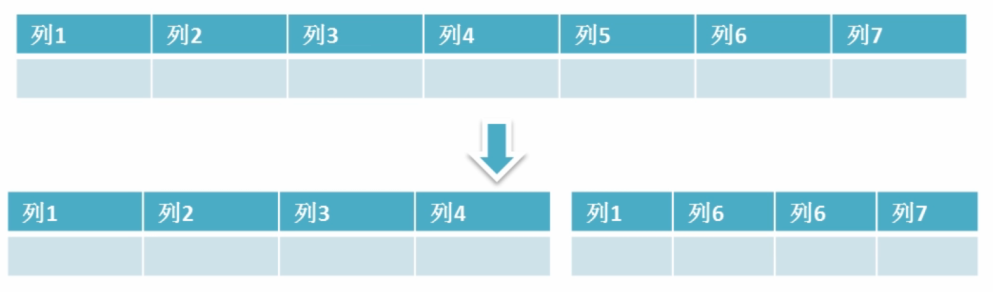
典型的应用场景是在文章列表这样的场景,一般来讲,我们的文章表会有title、userId、Content等字段,其中的Content字段一般是Text或者LongText类型,而其它的字段都是固定长度的数据类型。我们知道一个数据库优化规则是:
- 如果一个表的所有字段都是固定长度类型的,那么它就是定长表,定长表比动态长度表查询性能要高
- 那么,我们就可以使用垂直分表来将文章表分成文章表和文章内容表。于是文章列表页面所需的查询,就只需要查询一张定长表了。
或者,某个表中的字段比较多,可以新建立一张“扩展表”,将不经常使用或者长度较大的字段拆分出去放到“扩展表”中。
Vertical Partitioning Case Study
Consider the following table:
user_tab(`` ``uid, username, mobile_no, email, password_hash, password_salt, name, gender, birthday,`` ``recv_promo_email, recv_receipt_email, device_id, device_type={ios, android}, app_version)
It is indeed normalized. However, there are many columns, and this can cause performance issues.
Furthermore, the columns can be broken up into conceptually independent chunks (w.r.t. business logic):
user_account_info_tab(uid, username, mobile_no, email)``user_login_info_tab(uid, password_hash, password_salt) ``// Assume app uses uid for login.``user_personal_info_tab(uid, name, gender, birthday)``user_settings_tab(uid, recv_promo_email, recv_receipt_email)``user_device_tab(uid, device_id, device_type {ios, android}, app_version)
Now, we can apply different services based on the needs of each chunk, such as:
- Auto cache if table is frequently read e.g. user_settings_tab.
- Auto log changes if table needs auditing e.g. user_login_info_tab.
- Auto encrypt/decrypt if sensitive info e.g. user_personal_info_tab.
垂直分库
垂直分库针对的是一个系统中的不同业务进行拆分,比如用户User一个库,商品Producet一个库,订单Order一个库。 切分后,要放在多个服务器上,而不是一个服务器上。为什么?
我们想象一下,一个购物网站对外提供服务,会有用户,商品,订单等的CRUD。没拆分之前, 全部都是落到单一的库上的,这会让数据库的单库处理能力成为瓶颈。按垂直分库后,如果还是放在一个数据库服务器上, 随着用户量增大,这会让单个数据库的处理能力成为瓶颈,还有单个服务器的磁盘空间,内存,tps等非常吃紧。 所以我们要拆分到多个服务器上,这样上面的问题都解决了,以后也不会面对单机资源问题。
数据库业务层面的拆分,和服务的“治理”,“降级”机制类似,也能对不同业务的数据分别的进行管理,维护,监控,扩展等。 数据库往往最容易成为应用系统的瓶颈,而数据库本身属于“有状态”的,相对于Web和应用服务器来讲,是比较难实现“横向扩展”的。 数据库的连接资源比较宝贵且单机处理能力也有限,在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈。
分库分表中间件方案
如何进行分库分表,目前互联网上有许多的版本,比较知名的一些方案:阿里的TDDL,DRDS和cobar,京东金融的sharding-jdbc;民间组织的MyCAT;360的Atlas;美团的zebra
其他比如网易,58,京东等公司都有自研的中间件。
但是这么多的分库分表中间件方案,归总起来,就两类:client模式和proxy模式。
- cobar
- TDDL
- atlas
- sharding-jdbc
- mycat
分库分表后面临的问题
事务支持
分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会导致较高的系统复杂度。
多库结果集合并(group by,order by)
跨库join
分库分表后表之间的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表, 结果原本一次查询能够完成的业务,可能需要多次查询才能完成。 粗略的解决方法: 全局表:基础数据,所有库都拷贝一份。 字段冗余:这样有些字段就不用join去查询了。 系统层组装:分别查询出所有,然后组装起来,较复杂。
Analysis
Benefits of Sharding
Sharding allows you to scale your database to handle increased load to a nearly unlimited degree by providing increased read/write throughput, storage capacity, and high availability. Let’s look at each of those in a little more detail.
- Increased Read/Write Throughput — By distributing the dataset across multiple shards, both read and write operation capacity is increased as long as read and write operations are confined to a single shard.
- Increased Storage Capacity — Similarly, by increasing the number of shards, you can also increase overall total storage capacity, allowing near-infinite scalability.
- High Availability — Finally, shards provide high availability in two ways. First, since each shard is a replica set, every piece of data is replicated. Second, even if an entire shard becomes unavailable since the data is distributed, the database as a whole still remains partially functional, with part of the schema on different shards.
Drawbacks of Sharding
Sharding does come with several drawbacks, namely overhead in query result compilation, complexity of administration, and increased infrastructure costs.
- Query Overhead — Each sharded database must have a separate machine or service which understands how to route a querying operation to the appropriate shard. This introduces additional latency on every operation. Furthermore, if the data required for the query is horizontally partitioned across multiple shards, the router must then query each shard and merge the result together. This can make an otherwise simple operation quite expensive and slow down response times.
- Complexity of Administration — With a single unsharded database, only the database server itself requires upkeep and maintenance. With every sharded database, on top of managing the shards themselves, there are additional service nodes to maintain. Plus, in cases where replication is being used, any data updates must be mirrored across each replicated node. Overall, a sharded database is a more complex system which requires more administration.
- Increased Infrastructure Costs — Sharding by its nature requires additional machines and compute power over a single database server. While this allows your database to grow beyond the limits of a single machine, each additional shard comes with higher costs. The cost of a distributed database system, especially if it is missing the proper optimization, can be significant.
Reference
- https://en.wikipedia.org/wiki/Shard_(database_architecture)
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
- https://www.digitalocean.com/community/tutorials/understanding-database-sharding
- https://www.mongodb.com/features/database-sharding-explained
- 大众点评订单系统分库分表实践 - https://tech.meituan.com/2016/11/18/dianping-order-db-sharding.html