Context
Sometimes a service instance can be incapable of handling requests yet still be running. For example, it might have ran out of database connections. When this occurs, the monitoring system should generate a alert. Also, the load balancer or service registry should not route requests to the failed service instance.
Problem
How to detect that a running service instance is unable to handle requests?
Forces
- An alert should be generated when a service instance fails
- Requests should be routed to working service instances
Solution
A service has an health check API endpoint (e.g. HTTP /health) that returns the health of the service. The API endpoint handler performs various checks, such as
- the status of the connections to the infrastructure services used by the service instance
- the status of the host, e.g. disk space
- application specific logic
A health check client - a monitoring service, service registry or load balancer - periodically invokes the endpoint to check the health of the service instance.
So the Health Check checker (system) will reach the endpoint even if these security features are enabled. If you are using your own authentication system, the health check path must allow anonymous access.
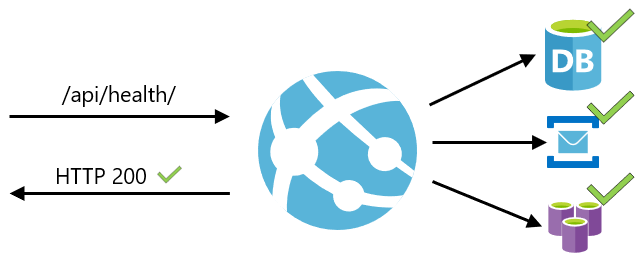
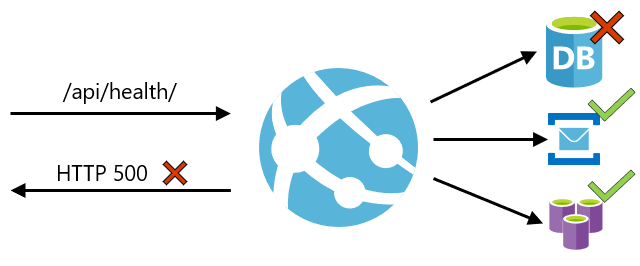
The health check path should check the critical components of your application. For example, if your application depends on a database and a messaging system, the health check endpoint should connect to those components. If the application cannot connect to a critical component, then the path should return a HTTP error response code to indicate that the app is unhealthy.
Health Check Types
Shallow and Deep health checks
(1) Shallow health checks often manifest themselves as a simple ‘ping’, telling you superficial information about the capability for a server instance to be reachable. However, it doesn’t tell you much about the logical dependency of the system or whether a particular API will successfully return from that server instance.
(2) Deep health checks, on the other hand, give you a much better understanding of the health of your application since they can catch issues with dependencies. The problem with deep health checks is that they are expensive — they can take a lot of time to run; incur costs on your dependencies; and be sensitive to false-positives — when issues occur in the dependencies themselves.

Health Check In Practise
kubenetes
K8s has no smoke test and health check concepts, but it provides 3 kinds of probes for similar purposes:
- startup probes: this is used to know when a container application has started, only after startup, the other two probes will be used.
- readiness probes: this is used to know when a container is ready to start accepting traffic, when a Pod is not ready, it is removed from Service load balancers.
- liveness probes: this is used to know when to restart a container, for example, liveness probes could catch a deadlock, where an application is running, but unable to make progress.
istio
Integrated with k8s probes mentioned above, refer to https://istio.io/latest/docs/ops/configuration/mesh/app-health-check/.
grpc
No smoke test mentioned, health check is supported, refer to https://github.com/grpc/grpc/blob/master/doc/health-checking.md, grpc itself doesn’t help monitor the instance and take any actions, just support exposing health status to clients through the RPC.
Discussion
Relation between Smoke Test and Health Check
In computer programming and software testing, smoke testing (also confidence testing, sanity testing, build verification test (BVT) and build acceptance test) is preliminary testing to reveal simple failures severe enough to, for example, reject a prospective software release.
Testing Scope of Health Chcek
Reference
- https://microservices.io/patterns/observability/health-check-api.html
- https://docs.microsoft.com/en-us/azure/architecture/patterns/health-endpoint-monitoring
- https://www.ibm.com/garage/method/practices/manage/health-check-apis/
- https://medium.com/the-cloud-architect/patterns-for-resilient-architecture-part-3-16e8601c488e
- https://azure.github.io/AppService/2020/08/24/healthcheck-on-app-service.html
- https://en.wikipedia.org/wiki/Smoke_testing_(software)
Shopee
- https://confluence.shopee.io/pages/viewpage.action?pageId=532419100#heading-Concepts
- https://confluence.shopee.io/display/SPDEV/Smoke+Test+Guide
- https://docs.google.com/presentation/d/1sf_1iL0_4aw6sHFRE0psJu0LSHqS71wqgcV-qP24fjA/edit#slide=id.g5a55b8a65c_1_30