Redis
需要注意的是,在所有master-slave系统中,可以是CAP中 CP 系统, 即C(strong consistency)可以被保证。
CP 系统 - Strong Consistency
Solution 1
即 Master Slave也可以是强一致性的。
比如:当我们写Master的时候,Master负责先写自己,等成功后,再写Slave,两者都写成功后,才返回写操作成功。
整个过程是同步的,如果写Slave失败了,那么两种方法:
- retry
- 或者rollback master 的写入(如果rollback失败,则一直retry)
你可以看到,如果Master-Slave需要做成强一致性有多复杂。
Solution 2
开启 Redis 的 AOF appendfsync always,这意味着每一个写操作在写入memory后,都会同步的写入disk中(不仅仅写入kernal buffer,因为如果写入kernal buffer,当突然断电时,强一致性仍然无法被保证)。
而且还要考虑长时间写入AOF的Log Rewriting问题和Data Loading问题,即
- Log Rewriting 仍然需要耗费大量的CPU的
- Data Loading问题会导致当Redis Node重启后,需要先 Loading Data,这时候 Redis是无法对外进行工作的。
- 因而如果 Data 非常大,down time 时间也无法接受
Analysis
显然,这两种 solution 的性能都很差,因为都是sync write。
而且,个人理解,从Redis的设计理念来说,其本身就不是为了保证的一致性的(甚至最终一致性都很难保证,除非牺牲大量的性能),其本身的设计始终优先最求性能和可用性,而数据的持久性的一致性相对比较次要。
No Consistency
通常的master-slave architecture就无法保证 Consistency,因为如果当一部分数据被写入master后,这一部分数据会被async地同步到slave中,而当这个同步还没有完成时,master node挂了,这时候一个slave node被promote,以代替这个挂了的master node,并作为新的master node。这时候因为丢到的数据不会在新的master node中(而且之后也不可能在),因而eventual consistency都没有被保证。
在无法保证 Consistency 的情况下,我们仍然可以做一些trade-off,即性能与不一致的程度。
单机持久化
Redis提供两种持久化方式分别是:RDB和AOF。需要说明的一点是*写入文件并不代表持久化成功,还需要将文件同步到磁盘。*
比如
- 开启RDB,以定时打snapshot
- AOF 的
appendfsync everysec可以保证最多 1s的数据被丢失
master-slave
这个是非常常用的architecture。
MySQL
Master-slave MySQL
对于这种架构,Slave一般是Master的备份。在这样的系统中,一般是如下设计的:
- 读写请求都由Master负责
- 写请求写到Master上后,由Master同步(sync)或者异步(async)地同步到Slave上。
从Master同步到Slave上,你可以使用异步,也可以使用同步;可以使用Master来push,也可以使用Slave来pull。 通常来说是Slave来周期性的pull。
如果Slave pull,如果Master被下次pull之后 down了,那么这个时间片内的数据直接会丢失,且永远
Master-master MySQL
Master-Master,又叫Multi-master,是指一个系统存在两个或多个Master,每个Master都提供read-write服务。这个模型是Master-Slave的加强版,数据间同步一般是通过Master间的异步完成,所以是最终一致性。 Master-Master的好处是,一台Master挂了,别的Master可以正常做读写服务,他和Master-Slave一样,当数据没有被复制到别的Master上时,数据会丢失。很多数据库都支持Master-Master的Replication的机制。
另外,如果多个Master对同一个数据进行修改的时候,这个模型的恶梦就出现了——对数据间的冲突合并,这并不是一件容易的事情。看看Dynamo的Vector Clock的设计(记录数据的版本号和修改者)就知道这个事并不那么简单,而且Dynamo对数据冲突这个事是交给用户自己搞的。就像我们的SVN源码冲突一样,对于同一行代码的冲突,只能交给开发者自己来处理。
MySQL + Redis
数据更新时 - 异步更新缓存
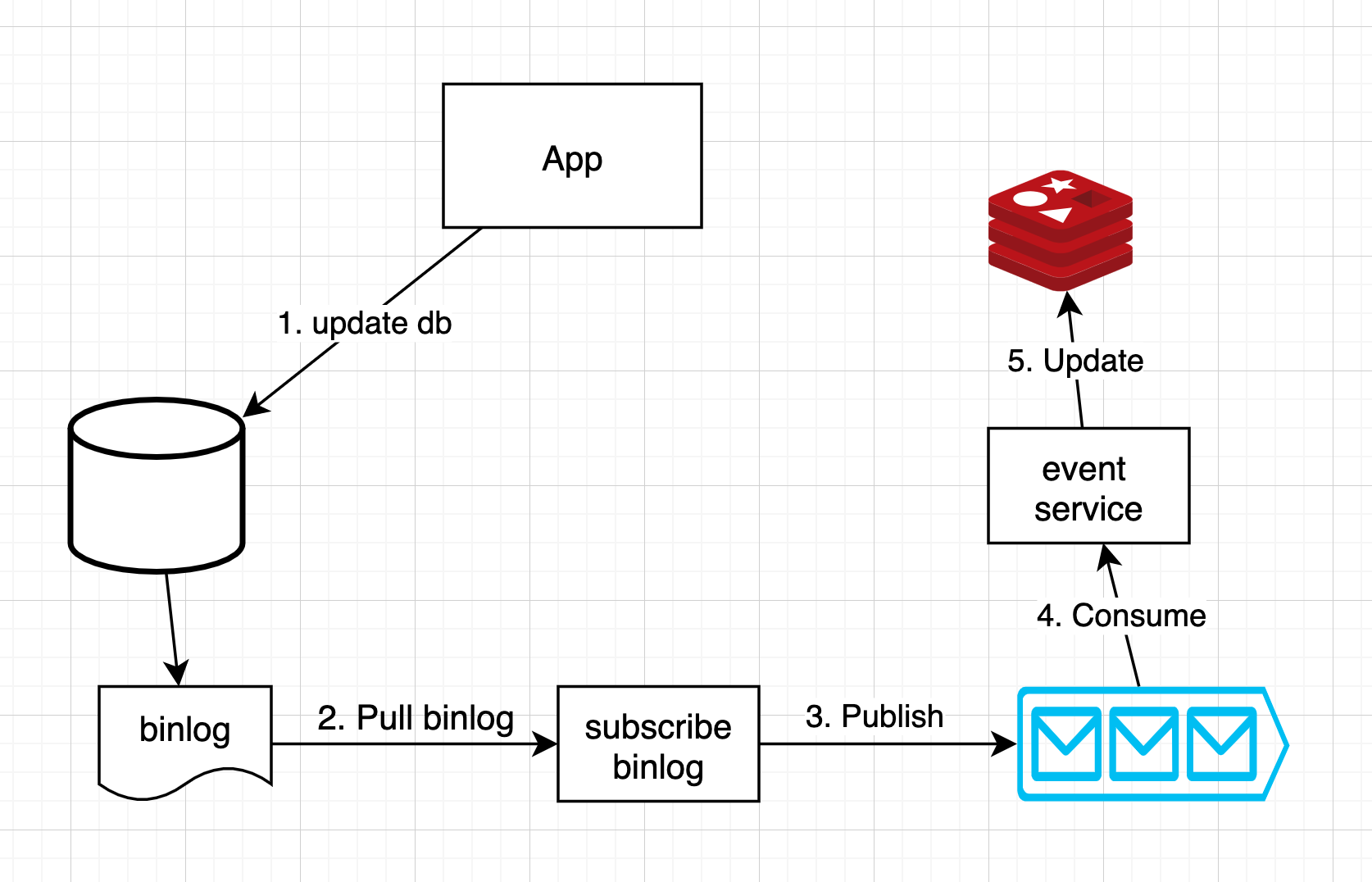
- single source of truth 为 DB
缓存与数据库双存储双写
数据更新时 - 缓存延时双删
即发生数据更新时,
-
先写数据库
-
删除缓存
-
休眠1秒,再次删除缓存
-
这一步可以这样实现:
- Solution 1:在第一次删除缓存后,开启一个线程,并让这个线程在1s后,执行再次删除
- Solution 2:通过读取DB的binlog和一个消息队列来实现再次删除
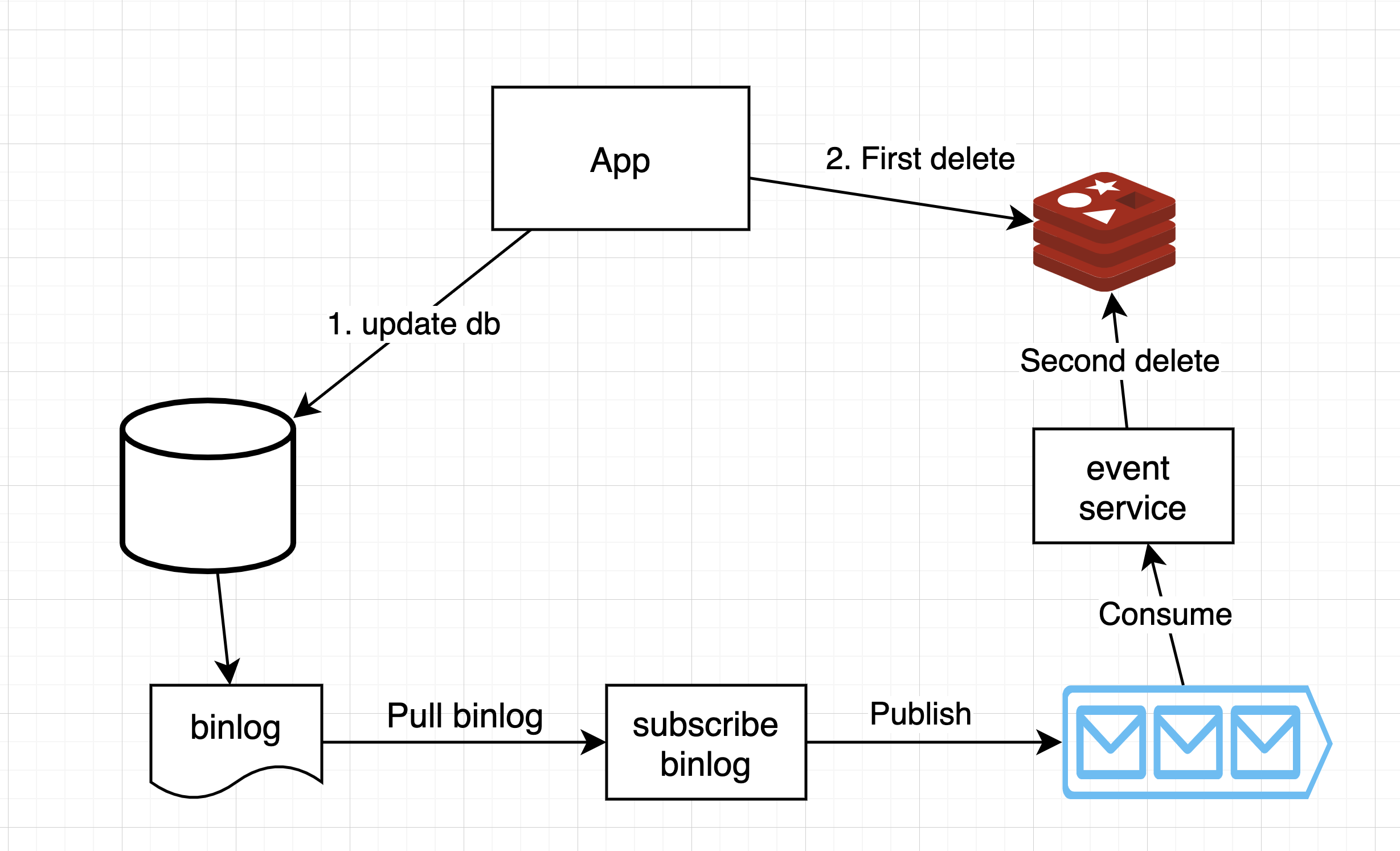
-
Analysis
- single source of truth 为 DB
- 这里具体休眠多久要结合业务情况考虑。
- 如果考虑到删除可能失败,再增加删除失败时的重试机制。
Reference
- https://xiaomi-info.github.io/2020/01/02/distributed-transaction/
- https://www.infoq.cn/article/hh4iouiijhwb4x46vxeo
- https://www.jdon.com/51363