Consistency Model
In computer science, consistency models are used in distributed systems like distributed shared memory systems or distributed data stores (such as filesystems, databases, optimistic replication systems or web caching). The system is said to support a given model if operations on memory follow specific rules.
The data consistency model specifies a contract between programmer and system, wherein the system guarantees that if the programmer follows the rules, memory will be consistent and the results of reading, writing, or updating memory will be predictable. This is different from coherence, which occurs in systems that are cached or cache-less, and is consistency of data with respect to all processors. Coherence deals with maintaining a global order in which writes to a single location or single variable are seen by all processors. Consistency deals with the ordering of operations to multiple locations with respect to all processors.
一致性模型(Consistency Model)
对一致性进行细分,具体包括三种一致性策略:
- 强一致性(Strong Consistency)
- 弱一致性(Weak Consistency)
- 最终一致性(Eventual Consistency)
CAP中说的不可能同时满足的这个一致性指的是强一致性(Strong Consistency)。
强一致性(Strong Consistency)/线性一致性(Linearizability)/严格一致性
强一致性(Strong Consistency)是一致性的最高标准。
即一旦写操作完成,随后任意客户端的查询都必须返回这一新值。
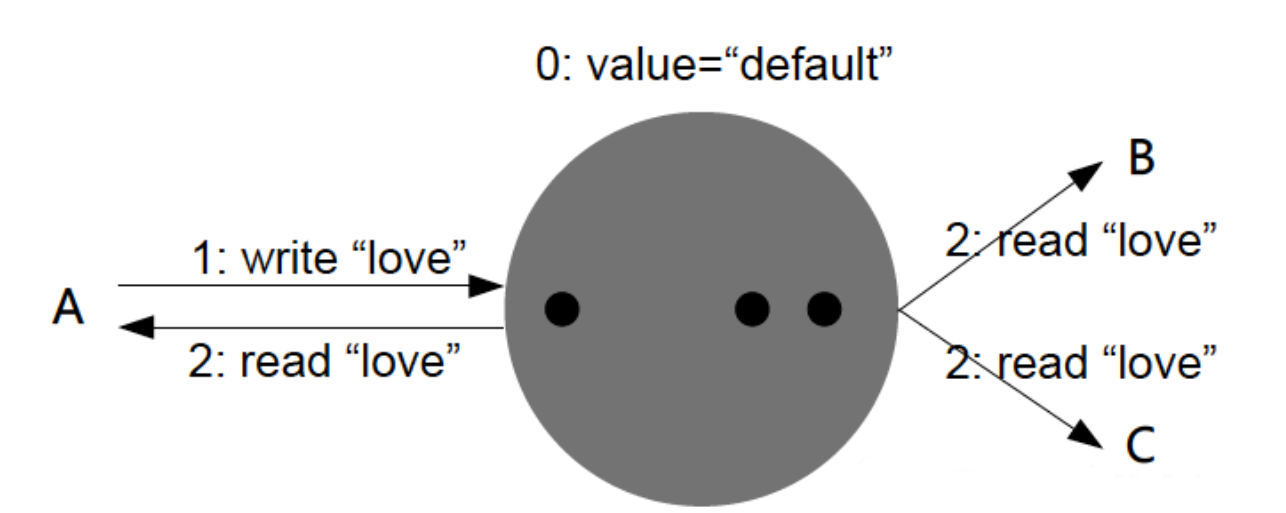
从业务角度来说,强一致性带来的体验简直可以用丝滑来形容!因为它内部的数据“仿佛”只有一份,即使并发访问不同节点,每个操作也都能原子有序。正因如此,强一致数据库在业务架构中往往被用在关键位置。
但是,这种实现对性能影响较大,因为这意味着,只要写操作的同步复制没有同步到其他节点,就不能让用户读取数据。
多个节点时的情况
- 从客户机写到节点1
- 写入通过集群传播,从节点1传播到节点2
- 从节点2到节点1的内部确认
- 从节点1向客户端确认
观察
- 系统总是返回最新的写操作:对于任何传入的写操作,一旦客户端确认了写操作,从任何节点读取的更新值都是可见的。
- 有保证的数据弹性:对于任何传入的写操作,一旦向客户端确认了写操作,更新就会受到冗余节点故障的保护。
为什么不总是使用严格的一致性?
主要是因为实现严格的一致性会显著影响性能。具体来说,延迟和吞吐量将会受到影响。影响的程度取决于具体情况。
严格的一致性并不总是必需的,在某些用例中最终的一致性可能就足够了。例如,在购物车中,假设添加了一个项目,但数据中心失败了。对客户来说,再次添加该项目并不是一种灾难。在这种情况下,最终的一致性就足够了。
然而,你不希望你的银行账户刚刚存入的钱发生这种情况。因为节点失败而导致资金消失是不可接受的。财务交易要求严格的一致性。
例子
- 最典型的,就是分布式的关系型数据库,即使在发生极端情况时,仍然优先保证数据的强一致性,代价就是舍弃系统的可用性。
- Paxos、Raft、ZAB、2PC协议
- 分布式系统中常用的Zookeeper
顺序一致性(Sequential Consistency)
顺序一致性弱于线性一致性,不保证操作的全局时序,但保证每个客户端操作能按顺序被执行。下图中,A先写x=10,后写x=20;B先写x=99,后写x=999。当C读取时,顺序一致性保证了10先于20被读到、99先于999被读到。
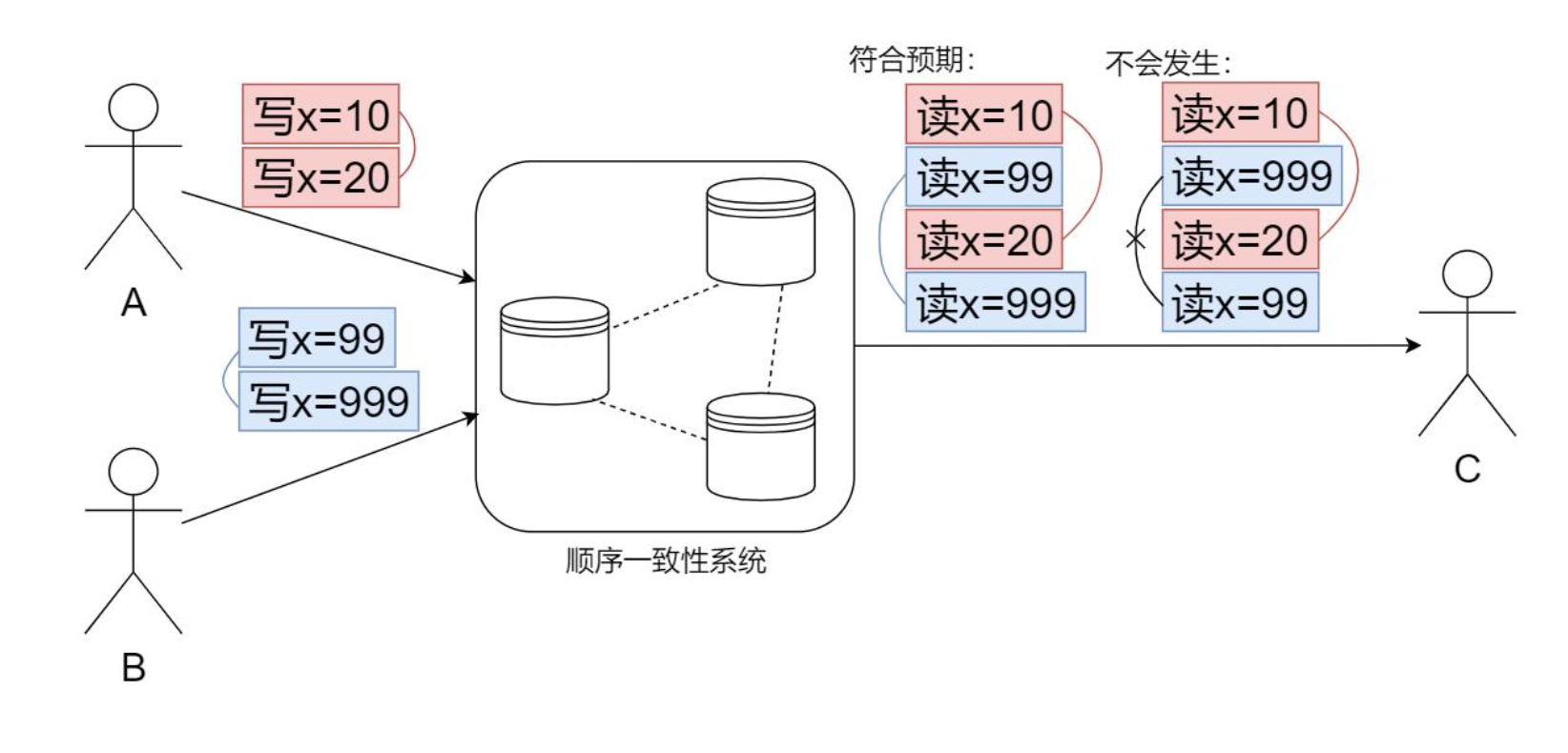
Zookeeper基于ZAB协议,所有写操作都经由主节点协调,实现了顺序一致性。
因果一致性(Causal Consistency)/ Consistent Prefix Reads
Problem
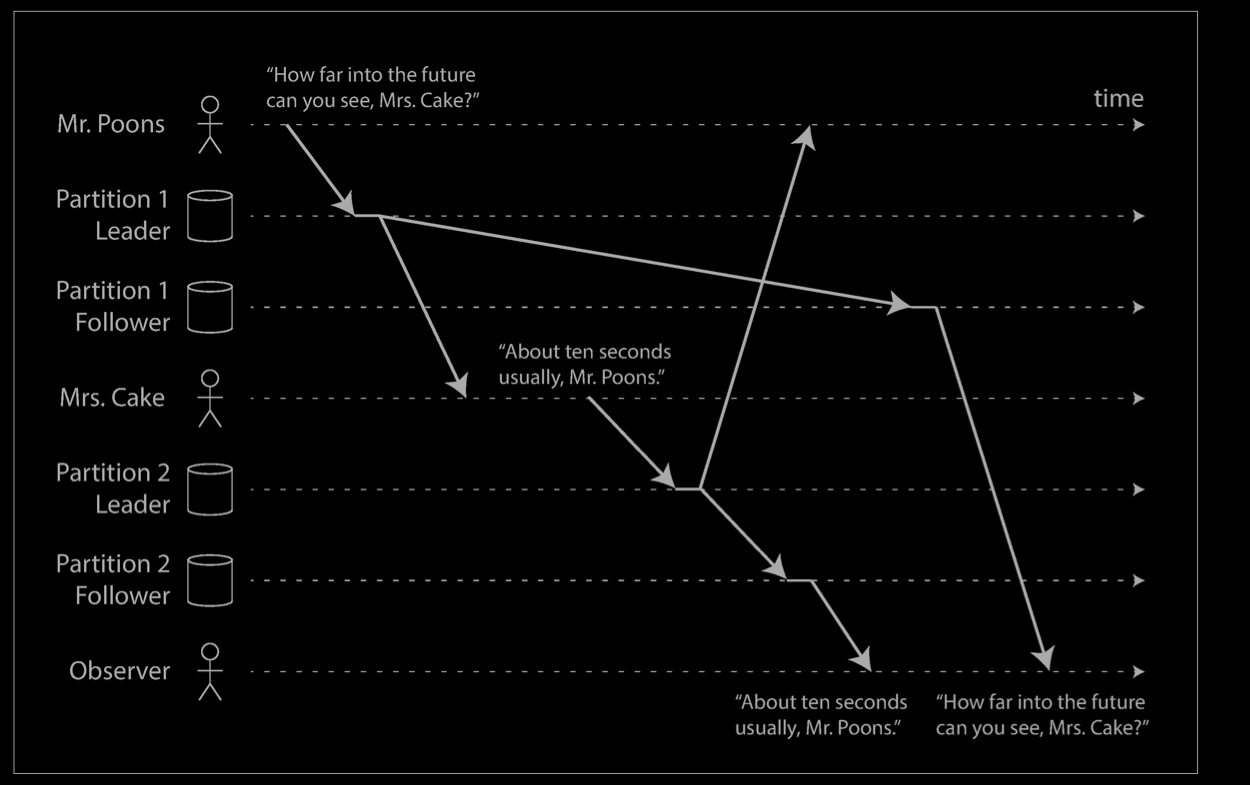
Imagine the following short dialog between Mr. Poons and Mrs. Cake:
- Mr. Poons How far into the future can you see, Mrs. Cake?
- Mrs. Cake About ten seconds usually, Mr. Poons.
There is a causal dependency between those two sentences: Mrs. Cake heard Mr. Poons’s question and answered it.
Now, imagine a third person is listening to this conversation through followers. The things said by Mrs. Cake go through a follower with little lag, but the things said by Mr. Poons have a longer replication lag. This observer would hear the following:
- Mrs. Cake About ten seconds usually, Mr. Poons.
- Mr. Poons How far into the future can you see, Mrs. Cake?
To the observer it looks as though Mrs. Cake is answering the question before Mr. Poons has even asked it. Such psychic powers are impressive, but very confusing.
Solution
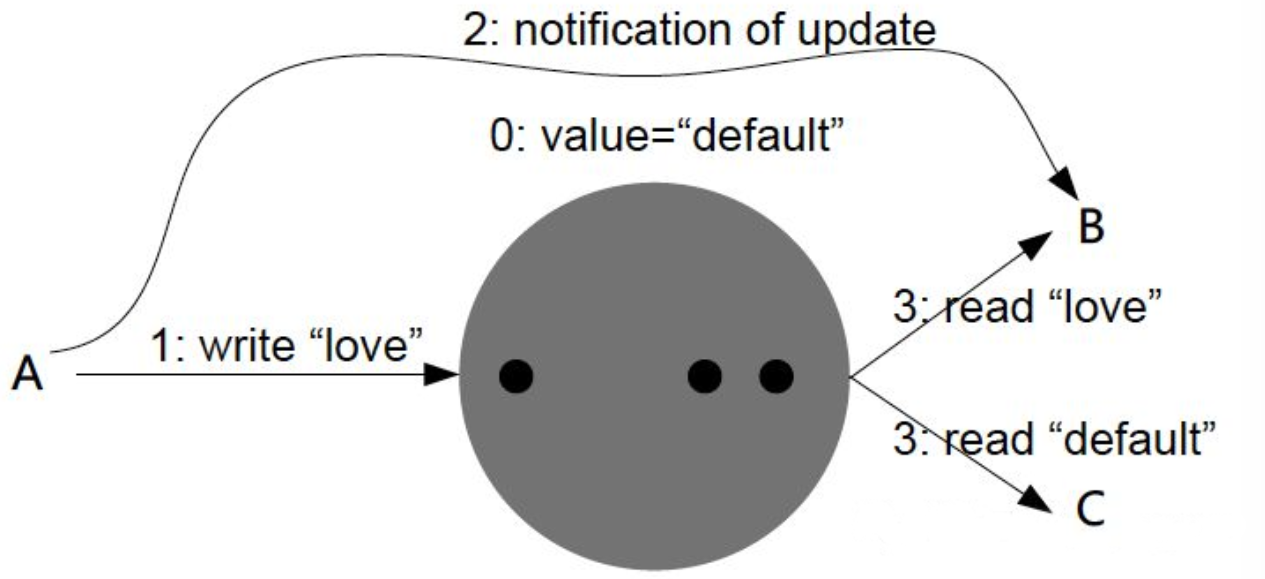
Preventing this kind of anomaly requires another type of guarantee: consistent prefix reads. This guarantee says that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order.
This is a particular problem in partitioned (sharded) databases. If the database always applies writes in the same order, reads always see a consistent prefix, so this anomaly cannot happen. However, in many distributed databases, different partitions operate independently, so there is no global ordering of writes: when a user reads from the database, they may see some parts of the database in an older state and some in a newer state.
因果一致性多用于各种博客的评论系统、社交软件等。毕竟,我们回复某条评论的内容(评论),不应早于该评论本身被显示出来。
这是一个听起来简单,实际却很难解决的问题。一种方案是应用保证将问题和对应的回答写入相同的分区。但并不是所有的数据都能如此轻易地判断因果依赖关系。
向量时钟(Vector Clock)
Refer to https://swsmile.info/post/Distributed-System-vector-clock
弱一致性(Weak Consistency)
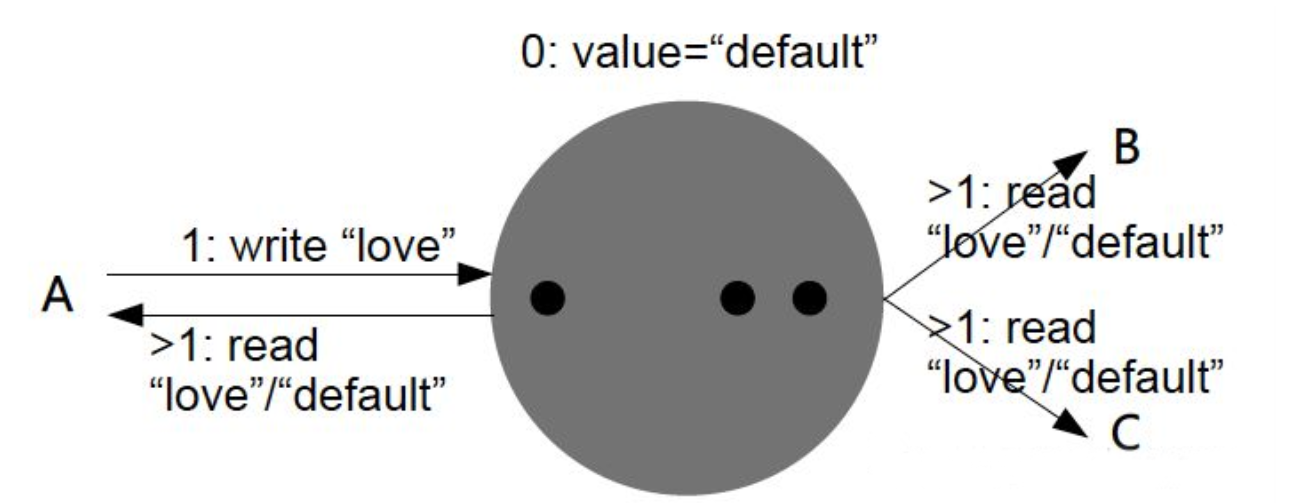
系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。但会尽可能保证在某个时间级别(比如秒级别)之后,可以让数据达到一致性状态。
因此,弱一致性一般是最终一致性(Eventual Consistency)。因为若在超过在某个时间级别之后,数据仍不具有一致性,则在某种程度上可以认为这个系统是没有意义的。
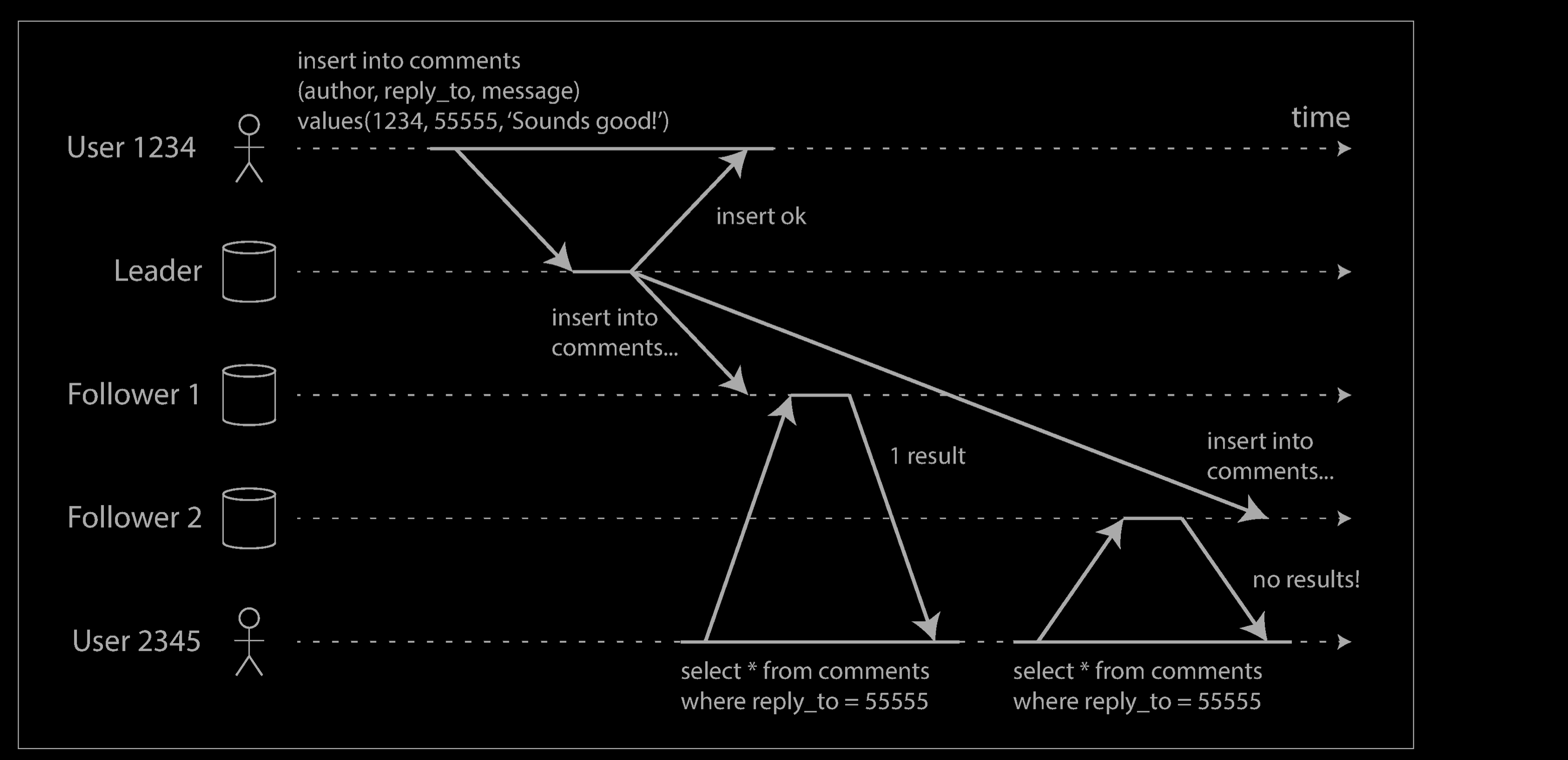
读己所写一致性(Read-your-writes Consistency)
Problem
Many applications let the user submit some data and then view what they have sub‐mitted. This might be a record in a customer database, or a comment on a discussion thread, or something else of that sort. When new data is submitted, it must be sent to the leader, but when the user views the data, it can be read from a follower. This is especially appropriate if data is frequently viewed but only occasionally written.
With asynchronous replication, there is a problem, illustrated below: if the user views the data shortly after making a write, the new data may not yet have reached the replica. To the user, it looks as though the data they submitted was lost, so they will be understandably unhappy.
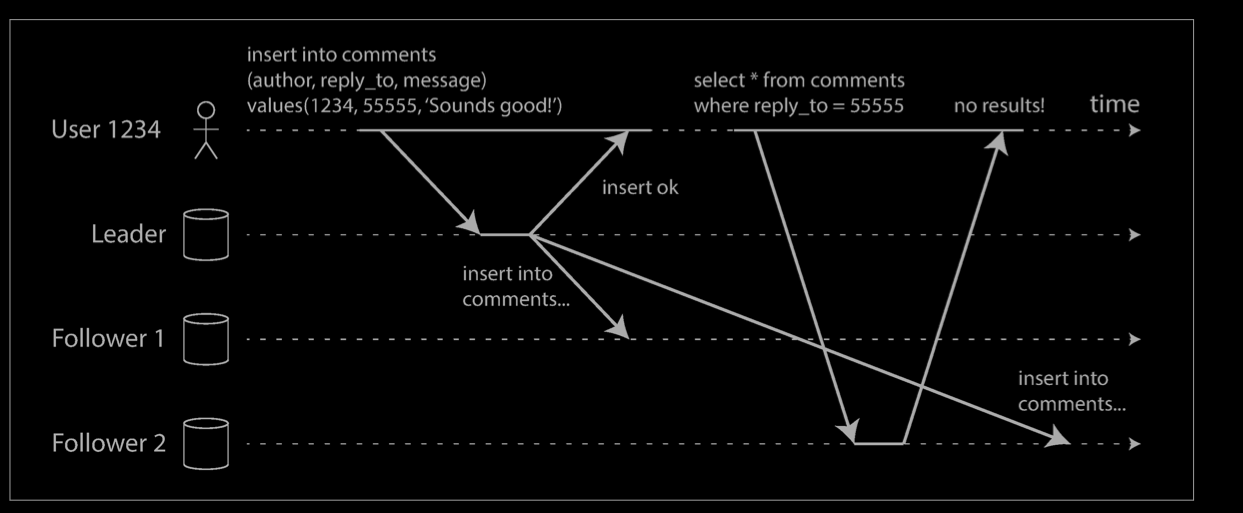
In this situation, we need read-after-write consistency, also known as read-your-writes consistency. This is a guarantee that if the user reloads the page, they will always see any updates they submitted themselves. It makes no promises about other users: other users’ updates may not be visible until some later time. However, it reassures the user that their own input has been saved correctly.
Solution
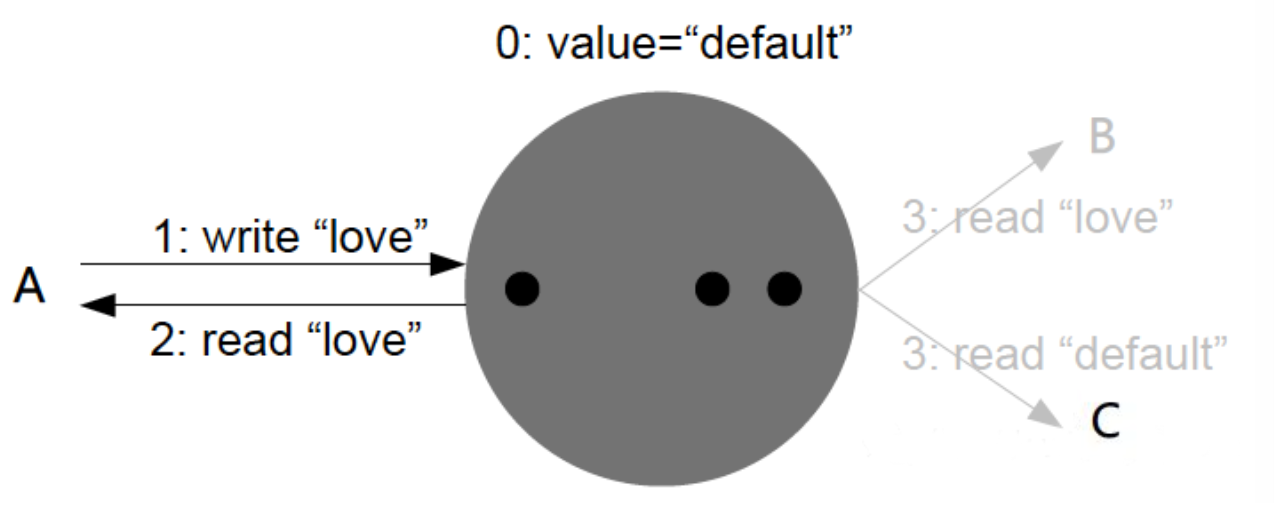
读己所写一致性是因果一致性的特定形式。进程总可以获取到自己上次更新写入的值。
手机刷虎扑的时候经常遇到,回复某人的帖子然后想马上查看,但我刚提交的回复可能尚未到达从库,看起来好像是刚提交的数据丢失了,很不爽。
在这种情况下,我们需要读写一致性(read-after-write consistency),也称为读己之写一致性。它可以保证,如果用户刷新页面,他们总会看到自己刚提交的任何更新。它不会对其他用户的写入做出承诺,其他用户的更新可能稍等才会看到,但它保证用户自己提交的数据能马上被自己看到。
如何实现读写一致性?
- When reading something that the user may have modified, read it from the leader; otherwise, read it from a follower. This requires that you have some way of knowing whether something might have been modified, without actually querying it. For example, user profile information on a social network is normally only editable by the owner of the profile, not by anybody else. Thus, a simple rule is: always read the user’s own profile from the leader, and any other users’ profiles from a follower.
- If most things in the application are potentially editable by the user, that approach won’t be effective, as most things would have to be read from the leader (negating the benefit of read scaling). In that case, other criteria may be used to decide whether to read from the leader. For example, you could track the time of the last update and, for one minute after the last update, make all reads from the leader. You could also monitor the replication lag on followers and prevent queries on any follower that is more than one minute behind the leader.
- The client can remember the timestamp of its most recent write—then the system can ensure that the replica serving any reads for that user reflects updates at least until that timestamp. If a replica is not sufficiently up to date, either the read can be handled by another replica or the query can wait until the replica has caught up. The timestamp could be a logical timestamp (something that indicates ordering of writes, such as the log sequence number) or the actual system clock (in which case clock synchronization becomes critical).
- If your replicas are distributed across multiple datacenters (for geographical proximity to users or for availability), there is additional complexity. Any request that needs to be served by the leader must be routed to the datacenter that contains the leader.
Another complication arises when the same user is accessing your service from multiple devices, for example a desktop web browser and a mobile app. In this case you may want to provide cross-device read-after-write consistency: if the user enters some information on one device and then views it on another device, they should see the information they just entered.
In this case, there are some additional issues to consider:
- Approaches that require remembering the timestamp of the user’s last update become more difficult, because the code running on one device doesn’t know what updates have happened on the other device. This metadata will need to be centralized.
- If your replicas are distributed across different datacenters, there is no guarantee that connections from different devices will be routed to the same datacenter. (For example, if the user’s desktop computer uses the home broadband connection and their mobile device uses the cellular data network, the devices’ network routes may be completely different.) If your approach requires reading from the leader, you may first need to route requests from all of a user’s devices to the same datacenter.
会话一致性(Session Consistency)
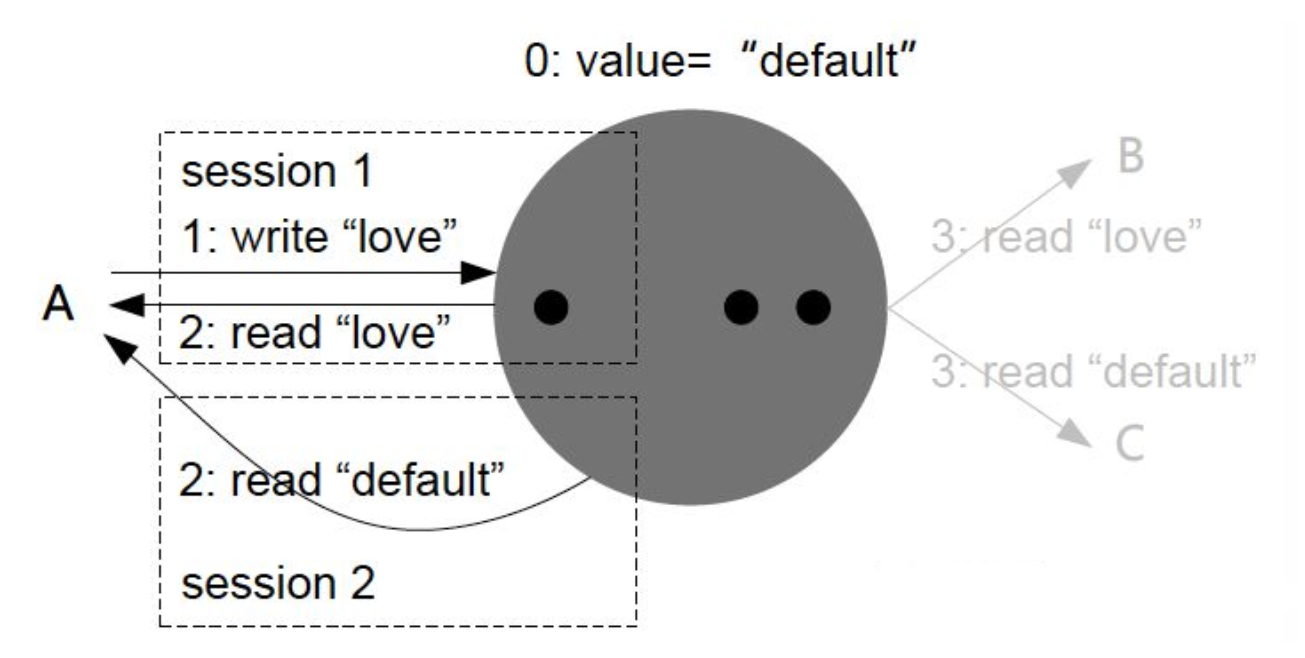
会话一致性是读己所写一致性的特定形式。在访问存储系统同一个会话内的不同进程,都会获取到上次更新写入的值。
具体来说,将一致性要求高的请求直接发往主节点,而可以接受最终一致性的请求则通过读写分离发往只读节点。这既增加了主节点的压力,影响读写分离的效果,又增加了应用开发的负担。
单调读一致性(Monotonic Reads)
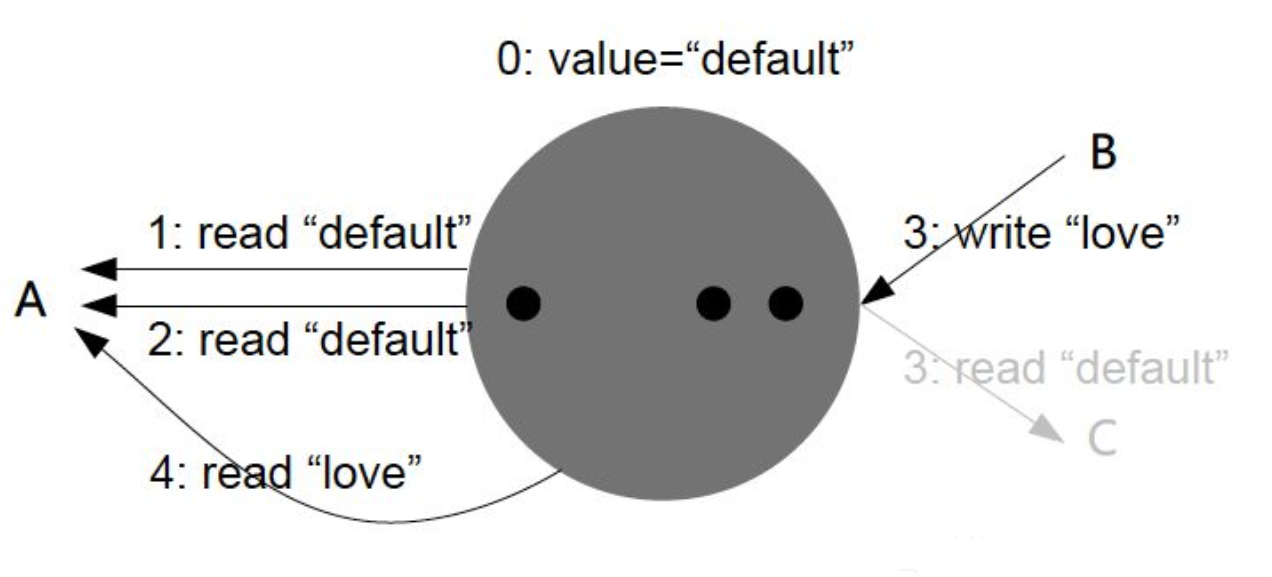
Our second example of an anomaly that can occur when reading from asynchronous followers is that it’s possible for a user to see things moving backward in time.
This can happen if a user makes several reads from different replicas. For example, the diagram above shows user 2345 making the same query twice, first to a follower with little lag, then to a follower with greater lag. (This scenario is quite likely if the user refreshes a web page, and each request is routed to a random server.) The first query returns a comment that was recently added by user 1234, but the second query doesn’t return anything because the lagging follower has not yet picked up that write. In effect, the second query is observing the system at an earlier point in time than the first query. This wouldn’t be so bad if the first query hadn’t returned anything, because user 2345 probably wouldn’t know that user 1234 had recently added a comment. However, it’s very confusing for user 2345 if they first see user 1234’s comment appear, and then see it disappear again.
Monotonic reads is a guarantee that this kind of anomaly does not happen. It’s a lesser guarantee than strong consistency, but a stronger guarantee than eventual consistency. When you read data, you may see an old value; monotonic reads only means that if one user makes several reads in sequence, they will not see time go backward—i.e., they will not read older data after having previously read newer data.
One way of achieving monotonic reads is to make sure that each user always makes their reads from the same replica (different users can read from different replicas). For example, the replica can be chosen based on a hash of the user ID, rather than randomly. However, if that replica fails, the user’s queries will need to be rerouted to another replica.
单调写一致性
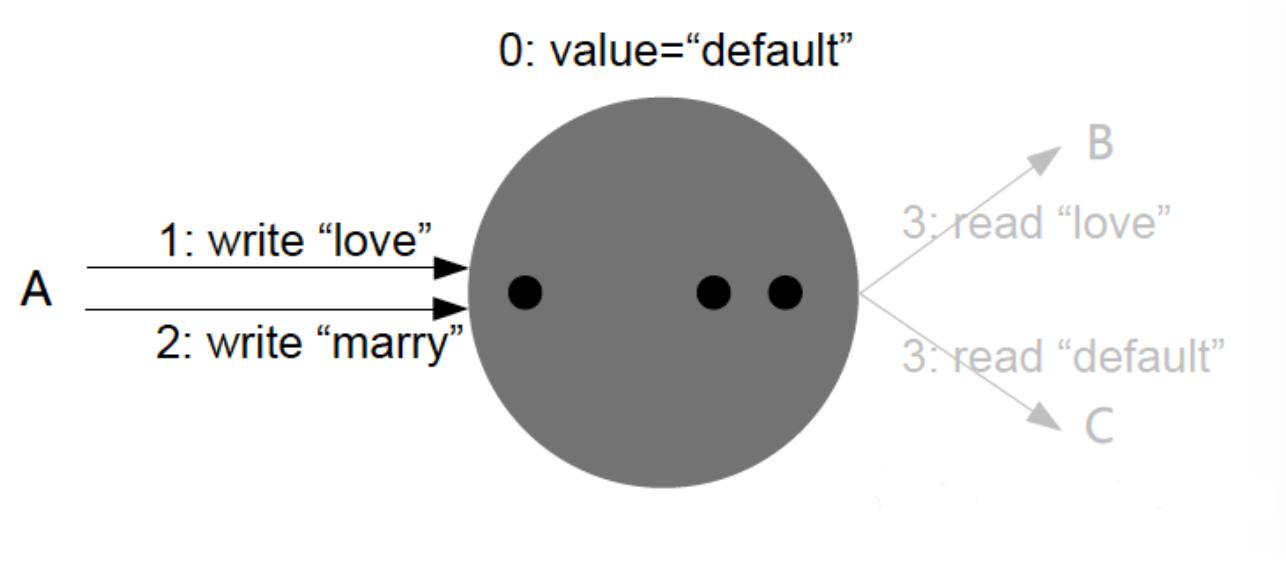
系统保证同一个进程写入操作的串行化。对于多副本系统来说,保证写顺序的一致性(串行化),是很重要的。
最终一致性(Eventual Consistency)
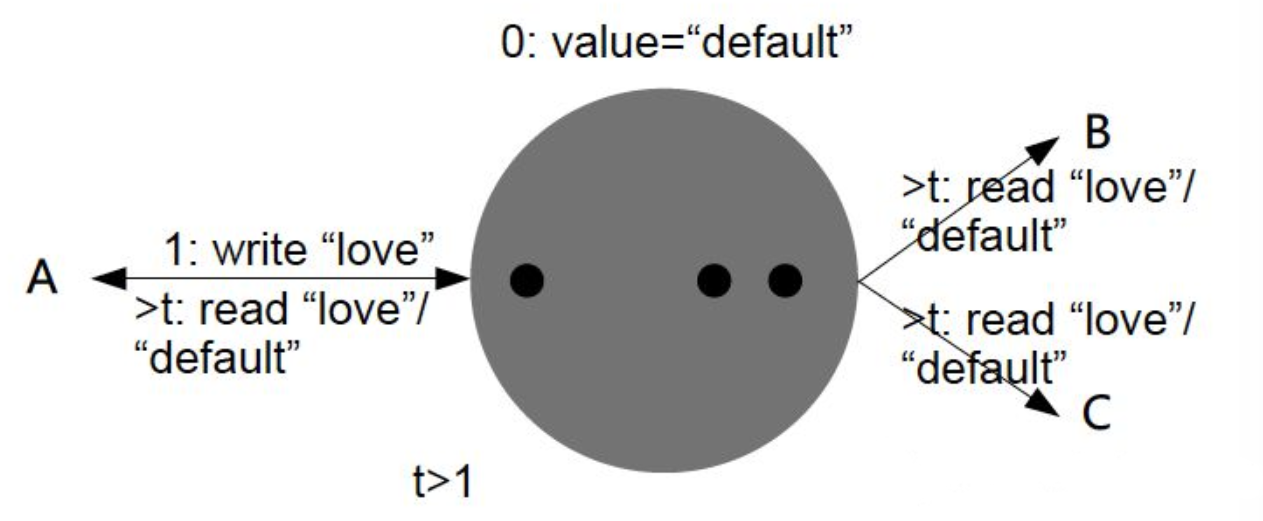
弱一致性的特定形式。
它指的是停止写入并等待一段时间,最终所有客户端都能读到相同的新数据,但具体时限不作保证。许多分布式数据库都满足最终一致性,如MySQL主从集群等。
然而,这其实是一个非常弱的保证。由于不确定系统内部过多久才能收敛一致,在此之前,用户随时可能体验到数据不一致。因此最终一致性有天然的局限性,经常会给业务逻辑带来混乱。
例子
DNS
- 发布一张网页到 CDN,多个服务器有这张网页的副本。后来发现一个错误,需要更新网页,这时只能每个服务器都更新一遍
- 一般来说,网页的更新不是特别强调一致性。短时期内,一些用户拿到老版本,另一些用户拿到新版本,问题不会特别大。当然,所有人最终都会看到新版本。所以,这个场合就是可用性高于一致性。
12306,淘宝
很多系统在可用性方面会做很多事情来保证系统的全年可用性可以达到N个9,所以,对于很多业务系统来说,比如淘宝的购物,12306的买票。都是在可用性和一致性之间舍弃了一致性而选择可用性
你在12306买票的时候肯定遇到过这种场景,当你购买的时候提示你是有票的(但是可能实际已经没票了),你也正常的去输入验证码,下单了。但是过了一会系统提示你下单失败,余票不足。这其实就是先在可用性方面保证系统可以正常的服务。
- 值得注意的是,这在数据的一致性方面做了些牺牲(这意味着用户看到的并不一定是正确的结果),因而会影响一些用户体验,但是也不至于造成用户流程的严重阻塞。
当进行最后下单的时候,还是会保证强一致性(通过牺牲可用性,可体现为等待时间较长,甚至出现失败)。
其他
- 电子邮件、Amazon S3,Google搜索引擎
Consideration
如果不考虑性能的话,事务得到保证并不困难,系统慢一点就行了。除了考虑性能外,我们还要考虑可用性,也就是说,一台机器没了,数据不丢失,服务可由别的机器继续提供。 于是,我们需要重点考虑下面的这么几个情况:
- 容灾:数据不丢、结点的Failover
- 数据的一致性:事务处理
- 性能:吞吐量 、 响应时间
前面说过,要解决数据不丢,只能通过数据冗余的方法,就算是数据分区,每个区也需要进行数据冗余处理。这就是数据副本:当出现某个节点的数据丢失时可以从副本读到,数据副本是分布式系统解决数据丢失异常的唯一手段。所以,在这篇文章中,简单起见,我们只讨论在数据冗余情况下考虑数据的一致性和性能的问题。简单说来:
- 要想让数据有高可用性,就得写多份数据
- 写多份的问题会导致数据一致性的问题
- 数据一致性的问题又会引发性能问题
这就是软件开发,按下了葫芦起了瓢。
Summary
下图来自:Google App Engine的co-founder Ryan Barrett在2009年的google i/o上的演讲《Transaction Across DataCenter》(视频: http://www.youtube.com/watch?v=srOgpXECblk)
![]()
前面,我们说过,要想让数据有高可用性,就需要冗余数据写多份。写多份的问题会带来一致性的问题,而一致性的问题又会带来性能问题。从上图我们可以看到,我们基本上来说不可以让所有的项都绿起来,这就是著名的CAP理论:一致性,可用性,分区容忍性,你只可能要其中的两个。
Reference
- https://en.wikipedia.org/wiki/Consistency_model
- https://coolshell.cn/articles/10910.html
- Google App Engine的co-founder Ryan Barrett在2009年的google i/o上的演讲《Transaction Across DataCenter》
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
- https://www.allthingsdistributed.com/2007/12/eventually_consistent.html