消息队列(Message Queue)
Message Queue, Message broker and message-oriented middleware are used interchangeably.
我们可以把消息队列比作是一个存放消息的容器,当我们需要使用消息的时候可以取出消息供自己使用。消息队列是分布式系统中重要的组件,使用消息队列主要是为了通过异步处理提高系统性能和削峰、降低系统耦合性。目前使用较多的消息队列有ActiveMQ,RabbitMQ,Kafka,RocketMQ。
另外,我们知道队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。比如生产者发送消息1,2,3…对于消费者就会按照1,2,3…的顺序来消费。但是偶尔也会出现消息被消费的顺序不对的情况,比如某个消息消费失败又或者一个 queue 多个consumer 也会导致消息被消费的顺序不对,我们一定要保证消息被消费的顺序正确。
除了上面说的消息消费顺序的问题,使用消息队列,我们还要考虑如何保证消息不被重复消费?如何保证消息的可靠性传输(如何处理消息丢失的问题)?等等问题。所以说使用消息队列也不是十全十美的,使用它也会让系统可用性降低、复杂度提高,另外需要我们保障一致性等问题。
Message Queue VS RPC
Message Queue, Message broker and message-oriented middleware are used interchangeably.
Using a message broker has several advantages compared to direct RPC:
- It can act as a buffer if the recipient is unavailable or overloaded, and thus improve system reliability.
- It can automatically redeliver messages to a process that has crashed, and thus prevent messages from being lost.
- It avoids the sender needing to know the IP address and port number of the recipient (which is particularly useful in a cloud deployment where virtual machines often come and go).
- It allows one message to be sent to several recipients.
- It logically decouples the sender from the recipient (the sender just publishes messages and doesn’t care who consumes them).
However, a difference compared to RPC is that message-passing communication is usually one-way: a sender normally doesn’t expect to receive a reply to its messages. It is possible for a process to send a response, but this would usually be done on a separate channel. This communication pattern is asynchronous: the sender doesn’t wait for the message to be delivered, but simply sends it and then forgets about it.
消息队列的两个model
点对点消息传递模式(Point-to-Point Messaging)
The point-to-point model is used when you need to send a message to only one message consumer. Even though multiple consumers may be listening on the queue for the same message, only one of those consumer threads will receive the message. This is different from the publish-and-subscribe model where a message is broadcast to (and consumed by) multiple consumers.
这种架构描述示意图如下:
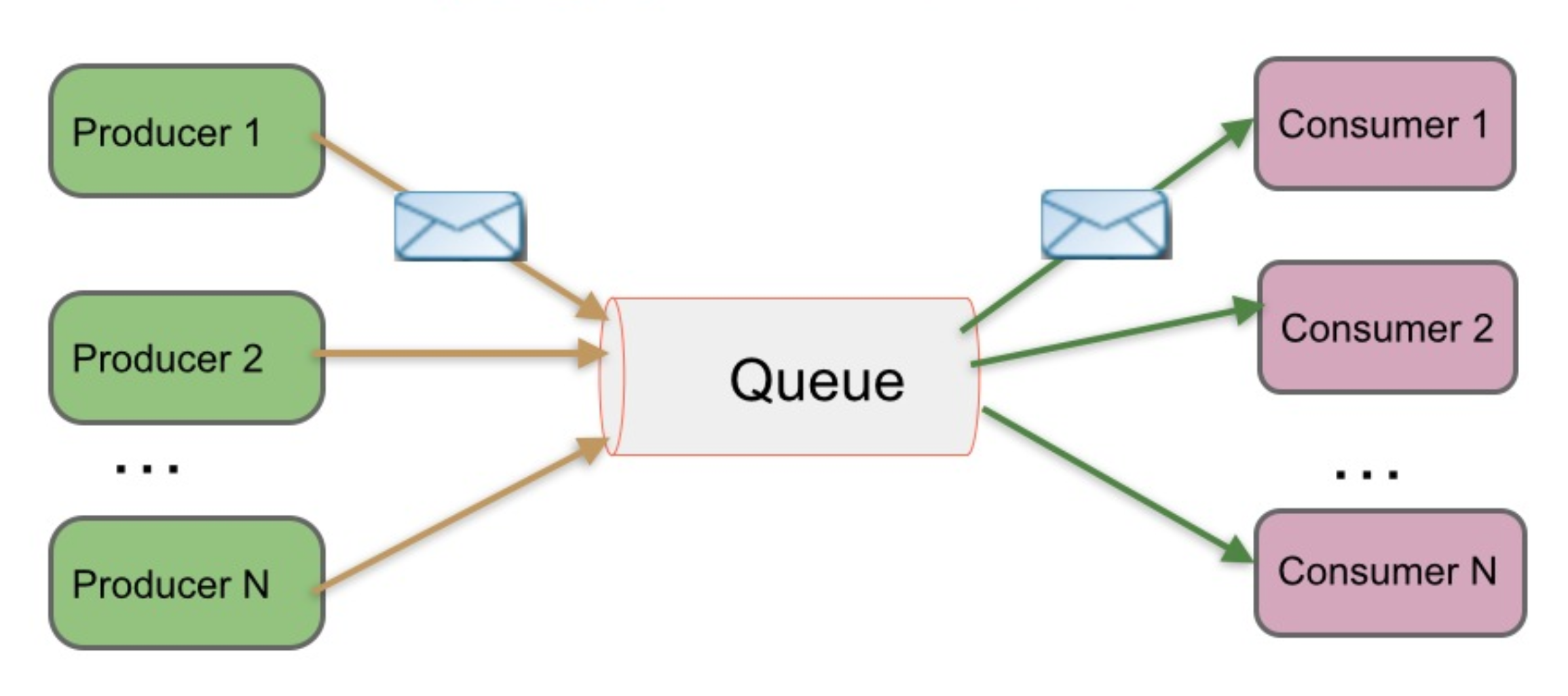
In the p2p model, the producer is called a sender and the consumer is called a receiver. The most important characteristics of the point-to-point model are as follows:
- Messages are exchanged through a virtual channel called a queue. A queue is a destination to which producers send messages and a source from which receivers consume messages.
- Each message is delivered to only one receiver. Multiple receivers may listen on a queue, but each message in the queue may only be consumed by one of the queue’s receivers.
- Messages are ordered. A queue delivers messages to consumers in the order they were placed in the queue by the message server. As messages are consumed, they are removed from the head of the queue (unless message priority is used).
- There is no coupling of the producers to the consumers. Receivers and senders can be added dynamically at runtime, allowing the system to grow or shrink in complexity over time. (This is a characteristic of messaging systems in general.)
发布-订阅消息传递模式(Publish-Subscribe Messaging)
在发布-订阅消息系统中,消息被持久化到一个topic中。与点对点消息系统不同的是,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。在发布-订阅消息系统中,消息的生产者称为发布者,消费者称为订阅者。该模式的示例图如下:
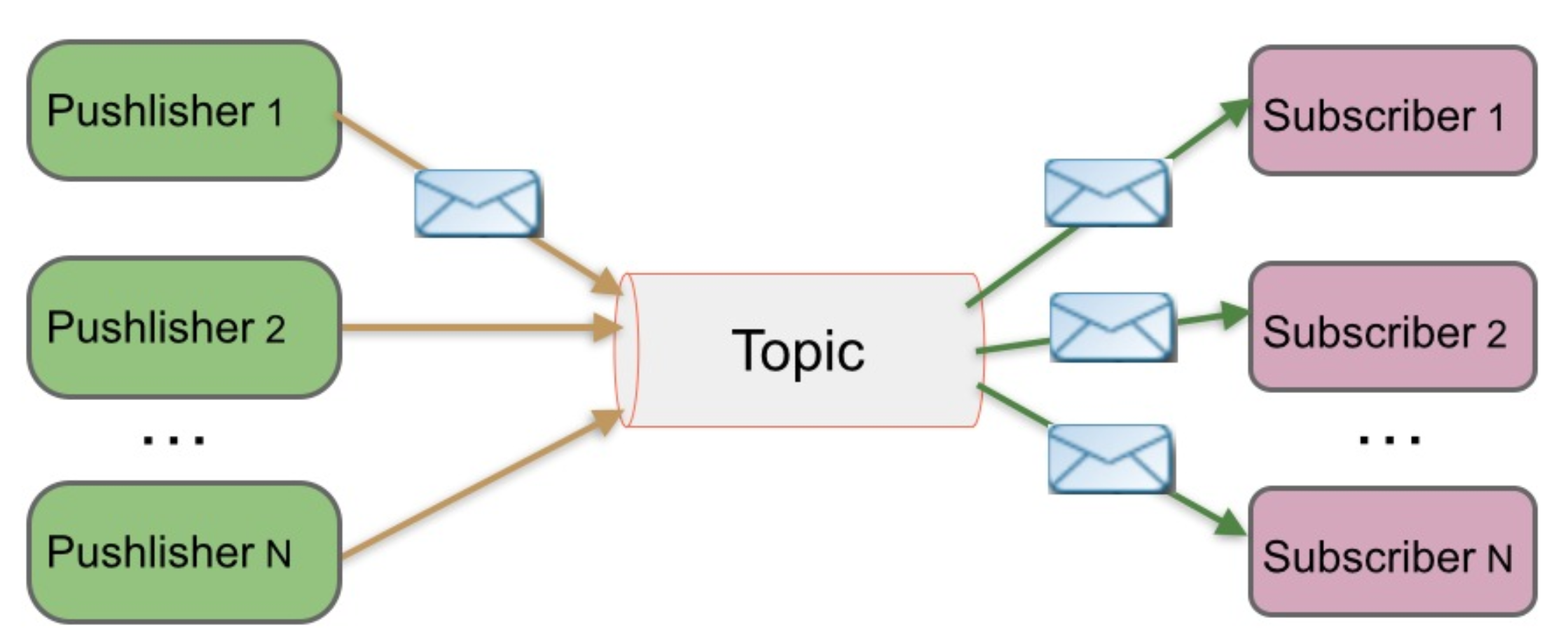
发布者发送到topic的消息,只有订阅了该topic的订阅者才会收到该topic中的消息。
When use
P2P
In most cases, the decision about which model to use depends on the distinct characteristics of each model. With pub/sub, any number of subscribers can be listening on a topic, all receiving copies of the same message. The publisher generally does not care how many subscribers there are or how many of them are actively listening on the topic. For example, consider a publisher that broadcasts stock quotes. If any particular subscriber is not currently connected and misses out on a great quote, the publisher is not concerned. In contrast, with point-to-point messaging, a particular message is likely to be intended for a one-on-one conversation with a specific application at the other end. In this scenario, every message matters.
Another use case for point-to-point messaging is when you need synchronous communication between components, but those components are written in different programming languages or implemented in different technology platforms (e.g., J2EE and .NET). For example, you may have a stock trading client written as a Java Swing client that needs to communicate with a .NET/C# trading server to process the stock trade. In this scenario, point-to-point messaging can be used to provide the interoperability between these heterogeneous platforms.
Why 消息队列
使用消息队列的好处:
- 通过异步处理提高系统性能(削峰、减少响应所需时间)
- 降低系统耦合性(Simplifed Decouping)
- Increased Reliability
- Granular Scalability
1 异步处理提高系统性能
秒杀系统需要解决的核心问题是,如何利用有限的服务器资源,尽可能多地处理短时间内的海量请求。我们知道,处理一个秒杀请求包含了很多步骤,例如:
- 风险控制;
- 库存锁定;
- 生成订单;
- 短信通知;
- 更新统计数据。
如果没有任何优化,正常的处理流程是:App 将请求发送给网关,依次调用上述 5 个流程,然后将结果返回给 APP。
对于对于这 5 个步骤来说,能否决定秒杀成功,实际上只有风险控制和库存锁定这 2 个步骤。只要用户的秒杀请求通过风险控制,并在服务端完成库存锁定,就可以给用户返回秒杀结果了,对于后续的生成订单、短信通知和更新统计数据等步骤,并不一定要在秒杀请求中处理完成。
所以当服务端完成前面 2 个步骤,确定本次请求的秒杀结果后,就可以马上给用户返回响应,然后把请求的数据放入消息队列中,由消息队列异步地进行后续的操作。
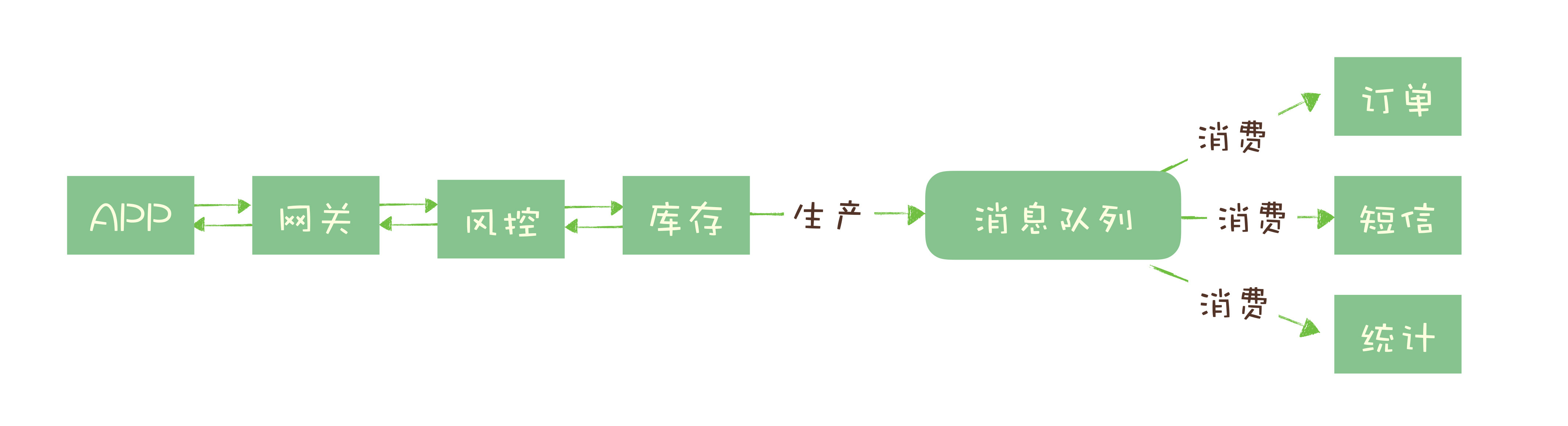
处理一个秒杀请求,从 5 个步骤减少为 2 个步骤,这样不仅响应速度更快,并且在秒杀期间,我们可以把大量的服务器资源用来处理秒杀请求。秒杀结束后再把资源用于处理后面的步骤,充分利用有限的服务器资源处理更多的秒杀请求。
**可以看到,在这个场景中,消息队列被用于实现服务的异步处理。**这样做的好处是:
- 可以更快地返回结果;
- 减少等待,自然实现了步骤之间的并发,提升系统总体的性能。
2. 流量控制 - 削峰(deal with traffic spikes)
继续说我们的秒杀系统,我们已经使用消息队列实现了部分工作的异步处理,但我们还面临一个问题:如何避免过多的请求压垮我们的秒杀系统?
一个设计健壮的程序有自我保护的能力,也就是说,它应该可以在海量的请求下,还能在自身能力范围内尽可能多地处理请求,拒绝处理不了的请求并且保证自身运行正常。不幸的是,现实中很多程序并没有那么“健壮”,而直接拒绝请求返回错误对于用户来说也是不怎么好的体验。
因此,我们需要设计一套足够健壮的架构来将后端的服务保护起来。我们的设计思路是,使用消息队列隔离网关和后端服务,以达到流量控制和保护后端服务的目的。
加入消息队列后,整个秒杀流程变为:
- 网关在收到请求后,将请求放入请求消息队列;
- 后端服务从请求消息队列中获取 APP 请求,完成后续秒杀处理过程,然后返回结果。

秒杀开始后,当短时间内大量的秒杀请求到达网关时,不会直接冲击到后端的秒杀服务,而是先堆积在消息队列中,后端服务按照自己的最大处理能力,从消息队列中消费请求进行处理。
对于超时的请求可以直接丢弃,APP 将超时无响应的请求处理为秒杀失败即可。运维人员还可以随时增加秒杀服务的实例数量进行水平扩容,而不用对系统的其他部分做任何更改。
这种设计的优点是:能根据下游的处理能力自动调节流量,达到“削峰填谷”的作用。但这样做同样是有代价的:
- 增加了系统调用链环节,导致总体的响应时延变长。
- 上下游系统都要将同步调用改为异步消息,增加了系统的复杂度。
3 服务解耦
我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
我们最常见的**事件驱动架构(Event-driven architecture)**类似生产者消费者模式,在大型网站中通常用利用消息队列实现事件驱动结构
消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。 从上图可以看到消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计。
消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。
举一个电商的例子来说明解耦的作用和必要性。
我们知道订单是电商系统中比较核心的数据,当一个新订单创建时:
- 支付系统需要发起支付流程;
- 风控系统需要审核订单的合法性;
- 客服系统需要给用户发短信告知用户;
- 经营分析系统需要更新统计数据;
- ……
这些订单下游的系统都需要实时获得订单数据。随着业务不断发展,这些订单下游系统不断的增加,不断变化,并且每个系统可能只需要订单数据的一个子集,负责订单服务的开发团队不得不花费很大的精力,应对不断增加变化的下游系统,不停地修改调试订单系统与这些下游系统的接口。任何一个下游系统接口变更,都需要订单模块重新进行一次上线,对于一个电商的核心服务来说,这几乎是不可接受的。
所有的电商都选择用消息队列来解决类似的系统耦合过于紧密的问题。引入消息队列后,订单服务在订单变化时发送一条消息到消息队列的一个主题 Order 中,所有下游系统都订阅主题 Order,这样每个下游系统都可以获得一份实时完整的订单数据。
无论增加、减少下游系统或是下游系统需求如何变化,订单服务都无需做任何更改,实现了订单服务与下游服务的解耦。
常见的消息队列
| 对比方向 | 概要 |
|---|---|
| 吞吐量 | 万级的 ActiveMQ 和 RabbitMQ 的吞吐量(ActiveMQ 的性能最差)要比十万级甚至是百万级的 RocketMQ 和 Kafka 低一个数量级。 |
| 可用性 | 都可以实现高可用。ActiveMQ 和 RabbitMQ 都是基于主从架构实现高可用性。RocketMQ 基于分布式架构。 kafka 也是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 时效性 | RabbitMQ 基于erlang开发,所以并发能力很强,性能极其好,延时很低,达到微秒级。其他三个都是 ms 级。 |
| 功能支持 | 除了 Kafka,其他三个功能都较为完备。 Kafka 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
| 消息丢失 | ActiveMQ 和 RabbitMQ 丢失的可能性非常低, RocketMQ 和 Kafka 理论上不会丢失。 |
总结:
- Apache ActiveMQ 的社区算是比较成熟,但是较目前来说,ActiveMQ 的性能比较差,而且版本迭代很慢,不推荐使用。
- RabbitMQ 在吞吐量方面虽然稍逊于 Kafka 和 RocketMQ ,但是由于它基于 erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级。但是也因为 RabbitMQ 基于 erlang 开发,所以国内很少有公司有实力做erlang源码级别的研究和定制。如果业务场景对并发量要求不是太高(十万级、百万级),那这四种消息队列中,RabbitMQ 一定是你的首选。如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
- RocketMQ 阿里出品,Java 系开源项目,源代码我们可以直接阅读,然后可以定制自己公司的MQ,并且 RocketMQ 有阿里巴巴的实际业务场景的实战考验。RocketMQ 社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准 JMS 规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用RocketMQ 挺好的
- Kafka 的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。
RabbitMQ
常见应用场景
- 邮箱发送:用户注册后投递消息到
rabbitmq中,由消息的消费方异步的发送邮件,提升系统响应速度 - 流量削峰:一般在秒杀活动中应用广泛,秒杀会因为流量过大,导致应用挂掉,为了解决这个问题,一般在应用前端加入消息队列。用于控制活动人数,将超过此一定阀值的订单直接丢弃。缓解短时间的高流量压垮应用。
- 订单超时:利用
rabbitmq的延迟队列,可以很简单的实现订单超时的功能,比如用户在下单后30分钟未支付取消订单
Apache ActiveMQ
Apache ActiveMQ is an open source message broker written in Java together with a full Java Message Service (JMS) client. It provides “Enterprise Features” which in this case means fostering the communication from more than one client or server.
Apache RocketMQ
RocketMQ is a distributed messaging and streaming platform with low latency, high performance and reliability, trillion-level capacity and flexible scalability. It is the third generation distributed messaging middleware open sourced by Alibaba in 2012.
Kafka
如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
Redis
Reference
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
- https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern
- https://en.wikipedia.org/wiki/Message_queue
- https://en.wikipedia.org/wiki/Message-oriented_middleware
- https://aws.amazon.com/message-queue/benefits/
- https://www.oreilly.com/library/view/java-message-service/9780596802264/ch04.html
- https://docs.oracle.com/cd/E19316-01/820-6424/aerbj/index.html
- https://cloud.google.com/pubsub/docs/overview
- https://en.wikipedia.org/wiki/Apache_ActiveMQ
- https://en.wikipedia.org/wiki/Apache_RocketMQ
- 《大型网站技术架构》
- https://learn.lianglianglee.com/%E4%B8%93%E6%A0%8F/%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97%E9%AB%98%E6%89%8B%E8%AF%BE/01%20%20%E4%B8%BA%E4%BB%80%E4%B9%88%E9%9C%80%E8%A6%81%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97%EF%BC%9F.md