The two-phase commit (2PC) protocol should not be confused with the two-phase locking (2PL) protocol, a concurrency control protocol.
两阶段提交协议(Two-phase Commit Protocol,2PC)
In transaction processing, databases, and computer networking, the two-phase commit protocol (2PC) is a type of atomic commitment protocol (ACP). It is a distributed algorithm that coordinates all the processes that participate in a distributed atomic transaction on whether to commit or abort (roll back) the transaction (it is a specialized type of consensus protocol). The protocol achieves its goal even in many cases of temporary system failure (involving either process, network node, communication, etc. failures), and is thus widely used.
However, it is not resilient to all possible failure configurations, and in rare cases, manual intervention is needed to remedy an outcome. To accommodate recovery from failure (automatic in most cases) the protocol’s participants use logging of the protocol’s states. Log records, which are typically slow to generate but survive failures, are used by the protocol’s recovery procedures. Many protocol variants exist that primarily differ in logging strategies and recovery mechanisms. Though usually intended to be used infrequently, recovery procedures compose a substantial portion of the protocol, due to many possible failure scenarios to be considered and supported by the protocol.
In a “normal execution” of any single distributed transaction (i.e., when no failure occurs, which is typically the most frequent situation), the protocol consists of two phases:
- The prepare phase (or voting phase), in which a coordinator process attempts to prepare all the transaction’s participating processes (named participants, cohorts, or workers) to take the necessary steps for either committing or aborting the transaction and to vote,
- either “Yes”: commit (if the transaction participant’s local portion execution has ended properly),
- or “No”: abort (if a problem has been detected with the local portion), and
- The commit phase, in which, based on voting of the participants, the coordinator decides whether to commit (only if all have voted “Yes”) or abort the transaction (otherwise), and notifies the result to all the participants. The participants then follow with the needed actions (commit or abort) with their local transactional resources (also called recoverable resources; e.g., database data) and their respective portions in the transaction’s other output (if applicable).
两阶段提交的过程
两阶段提交包含事务协调者(Transaction Coordinator)和若干事务参与者 (Transaction Participant)两种角色。
这里的事务参与者就是具体的数据库,抽象点可以说是可以控制给数据库的程序。 事务协调者可以和事务参与者 在一台机器上。
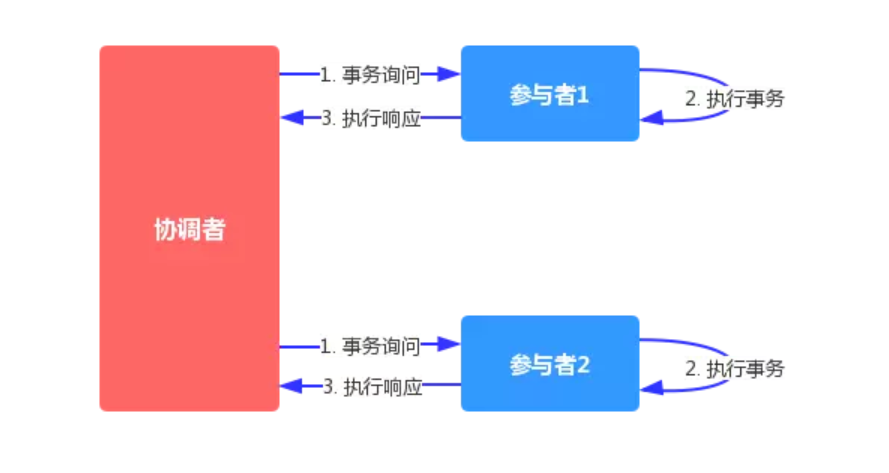
Prepare (or voting) Phase
在这一阶段,coordinator通过向所有participant 发送 prepare request 以询问所有participant 是否准备好提交,此后:
- 如果某个participant 在执行本地的事务的过程中没有出现异常,则向coordinator回复一条
agreement消息(其中标识了Prepared); - 如果某个participant 在执行本地事务的过程中出现了异常,则回复一条
agreement消息(其中标识了Abort)。
Commit (or completion) Phase
如果coordinator在上一阶段收到所有participant 回复(的 agreement 消息中)的 Prepared,则向所有participant 发送 commit request ,否则coordinator会向所有participant 发送 abort request。
coordinator向所有participant 发送 commit request
- 如 participant 收到了
commit命令,其会释放本地事务过程中持有的锁和其他资源,并将事务在本地提交(持久化一条commit日志)。然后向coordinator发送acknowledgement命令以标志操作成功; - 最终,如果coordinator收到了所有participant 回复的
acknowledgement消息,coordinator完成该事务,并向客户端返回事务成功消息。
coordinator向所有participant 发送 abort request
- 在 Voting phase 中,若任何一个participant 回复
No或超时未应答,coordinator会先在本地持久化事务状态,并向所有participant 发送rollback命令; - participant 收到
rollback命令后,会回滚事务(有必要的情况下还要持久化一条 abort 日志),并释放本地资源和锁。最终,向coordinator发送acknowledgement消息以表示 rollback 成功; - 当coordinator收到所有participant 回复的
acknowledgement消息后,coordinator取消该事务,并向客户端返回事务失败消息。
例子
支付宝 + 余额宝
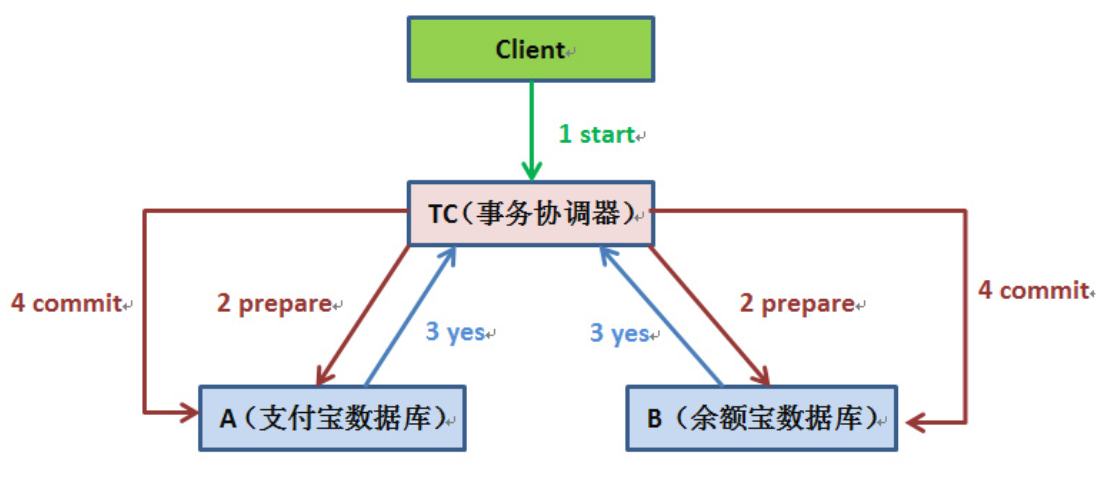
我们设想从支付宝里转10000元到余额宝的场景……
- 首先我们的应用程序发起一个请求到coordinator者,然后由coordinator来保证分布式事务。
- Vote Phase
- coordinator先将
prepare消息写到本地日志。 - 向所有的participant 发起
prepare消息。以支付宝转账到余额宝为例,协调器给participant A 的prepare消息,是通知支付宝数据库相应账目扣款 10000,coordinator给 participant B 的prepare消息是通知余额宝数据库相应账目增加 10000。 - participant 收到
prepare消息后,执行本机事务,如果本地事务成功则向coordinator返回Yes,不成功则返回No。类似的,在返回前participant 会将操作写入本地日志。
- coordinator先将
- Commit Phase:coordinator这时已经获得了所有participant 返回的消息,
- 如果所有participant 都返回
Yes,coordinator会给所有 participant 发送commit消息,participant 收到commit后,将执行本地事务的commit操作(在执行后写入本地日志),并返回acknowledgement消息给coordinator - 如果有任一个participant 返回
No,coordinator会给所有participant 发送rollback消息,participant 收到rollback消息后执行本地事务的rollback操作(在执行后写入本地日志),并返回acknowledgement消息给coordinator。 - coordinator将操作写入本地日志,并最终返回结果给客户端。
- 如果所有participant 都返回
Assumptions
The protocol works in the following manner: one node is a designated coordinator, which is the master site, and the rest of the nodes in the network are designated the participants. The protocol assumes that there is stable storage at each node with a write-ahead log, that no node crashes forever, that the data in the write-ahead log is never lost or corrupted in a crash, and that any two nodes can communicate with each other. The last assumption is not too restrictive, as network communication can typically be rerouted. The first two assumptions are much stronger; if a node is totally destroyed then data can be lost.
The protocol is initiated by the coordinator after the last step of the transaction has been reached. The participants then respond with an agreement message or an abort message depending on whether the transaction has been processed successfully at the participant.
Failure Handling
Two-phase commit protocol heavily relies on the coordinator node to communicate the outcome of the transaction. Until the outcome of the transaction is known, the individual cluster nodes cannot allow any other transactions to write to the keys participating in the pending transaction. The cluster nodes block until the outcome of the transaction is known. This puts some critical requirements on the coordinator
The coordinator needs to remember the state of the transactions even in case of a process crash.
Coordinator uses Write-Ahead Log to record every update to the state of the transaction. This way, when the coordinator crashes and comes back up, it can continue to work on the transactions which are incomplete.
两阶段提交的容错方式(Failover)
两阶段提交(2PC)在执行过程中,可能发生 coordinator 或者 participant 突然宕机的情况,同时,在不同时期的宕机可能会出现不同的情况。
Case 1 - coordinator 宕机,participant 正常
这种情况其实比较好解决,只要找一个coordinator的替代者。当它成为新的coordinator的时候,either 查看当前本地日志 or 询问 participant,它就能够知道当前事务处于哪个状态。
所以,这种情况不会导致数据不一致。
Coordinator Fails After sending a prepare request
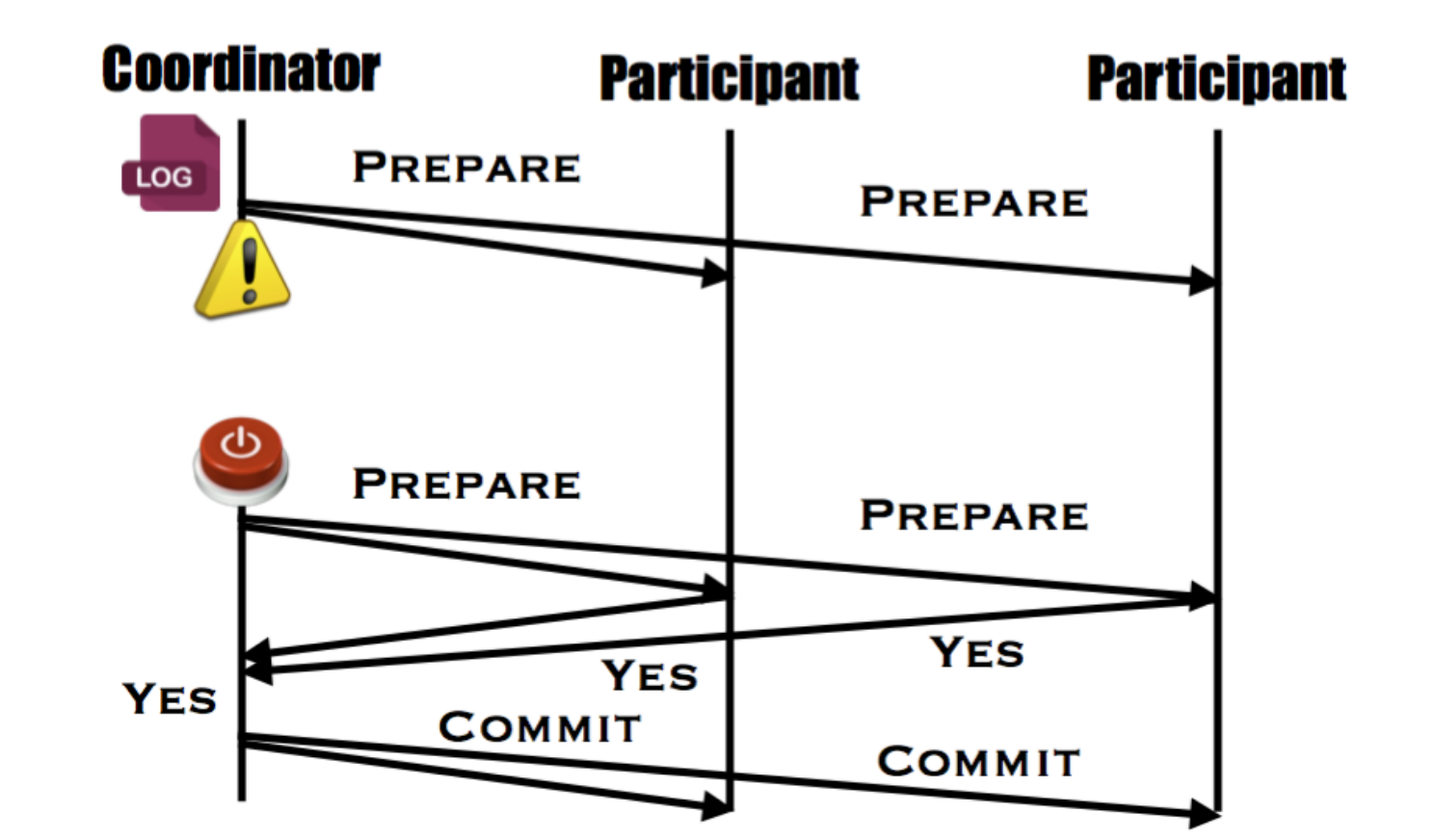
Coordinator Fails After sending decision
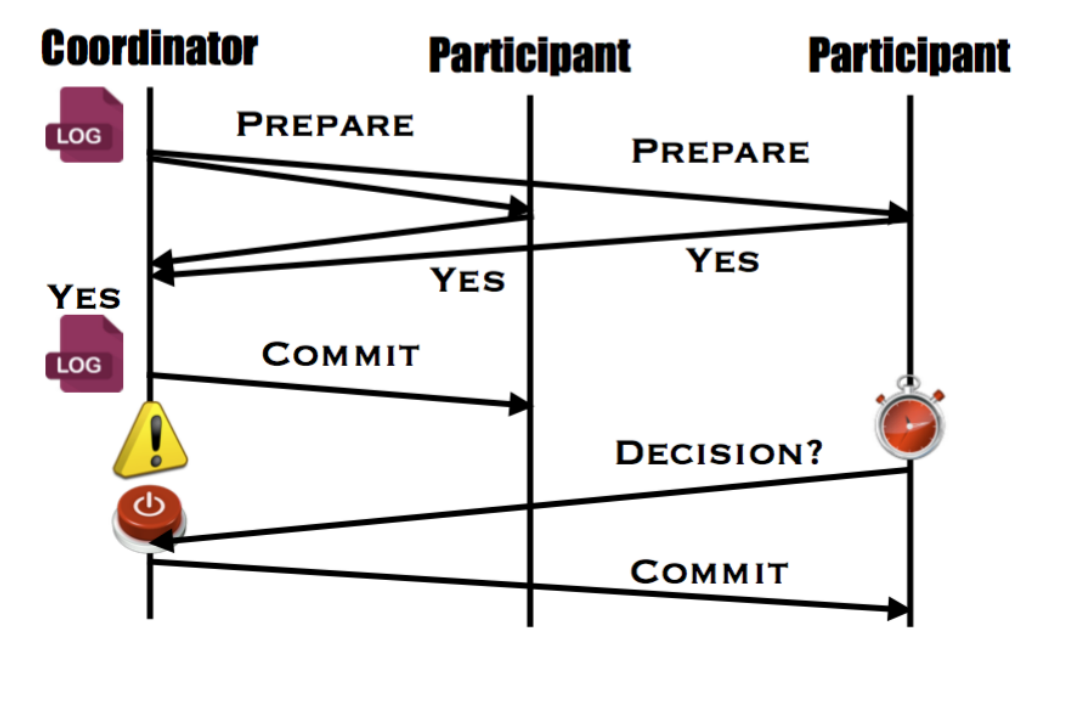
Case 2 - participant 宕机,coordinator正常
这种情况其实也比较好解决。如果coordinator宕机了。那么之后的事情有几种情况:
Participant Fails Before sending response
coordinator会通知所有participant rollback, 因此不会导致数据不一致的问题。
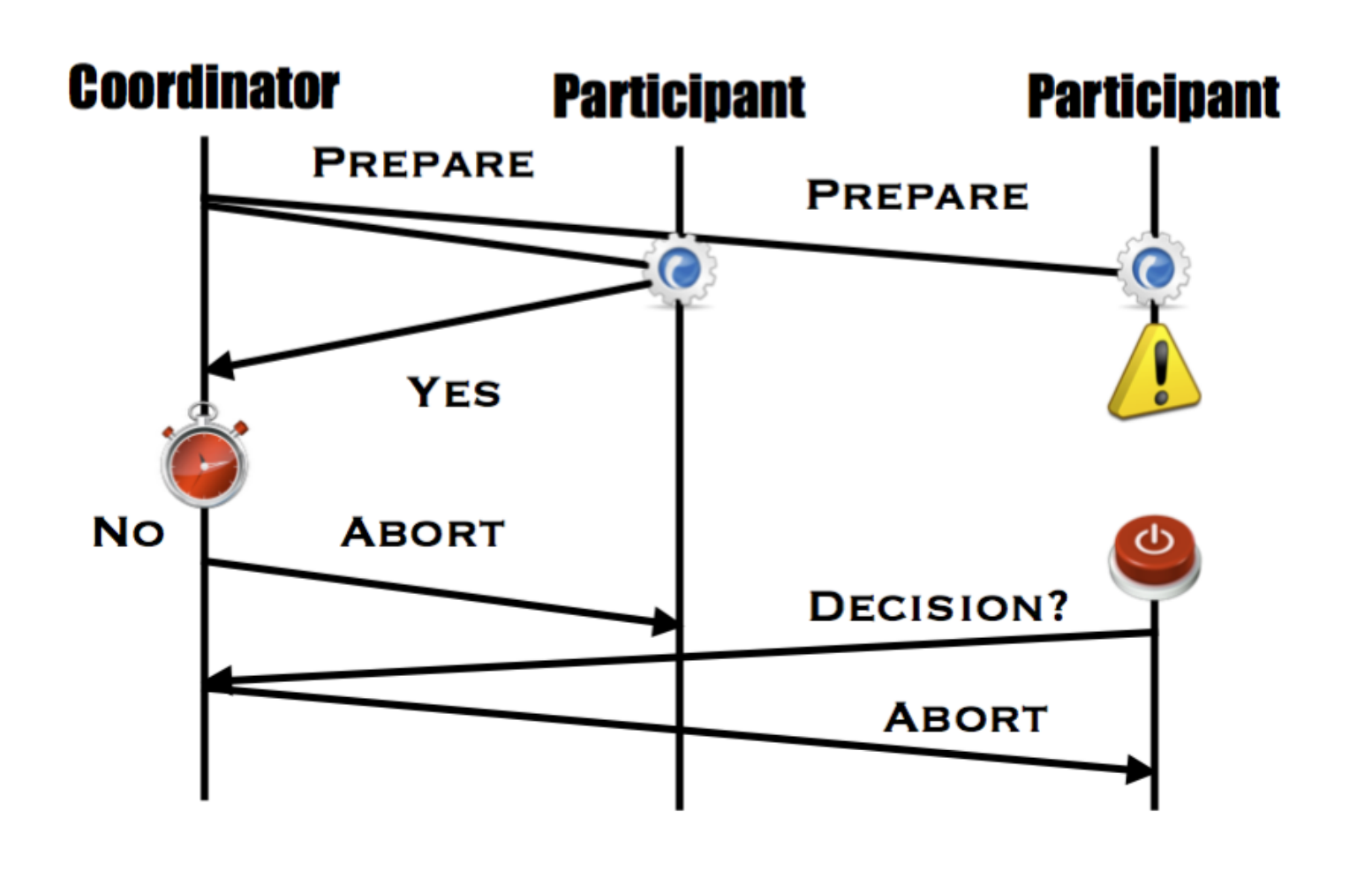
Participant Fails After sending response
宕机之后又恢复了,这时取决于宕机的时长:
- 如果很短,可能没有任何影响(比如宕机后又恢复的 Participant 仍然收到了 commit)
- 如果很长,可能这时候 coordinator已经发送了commit,但并没有被收到,此时coordinator就会一直的发送 commit,直到commit 被成功接收
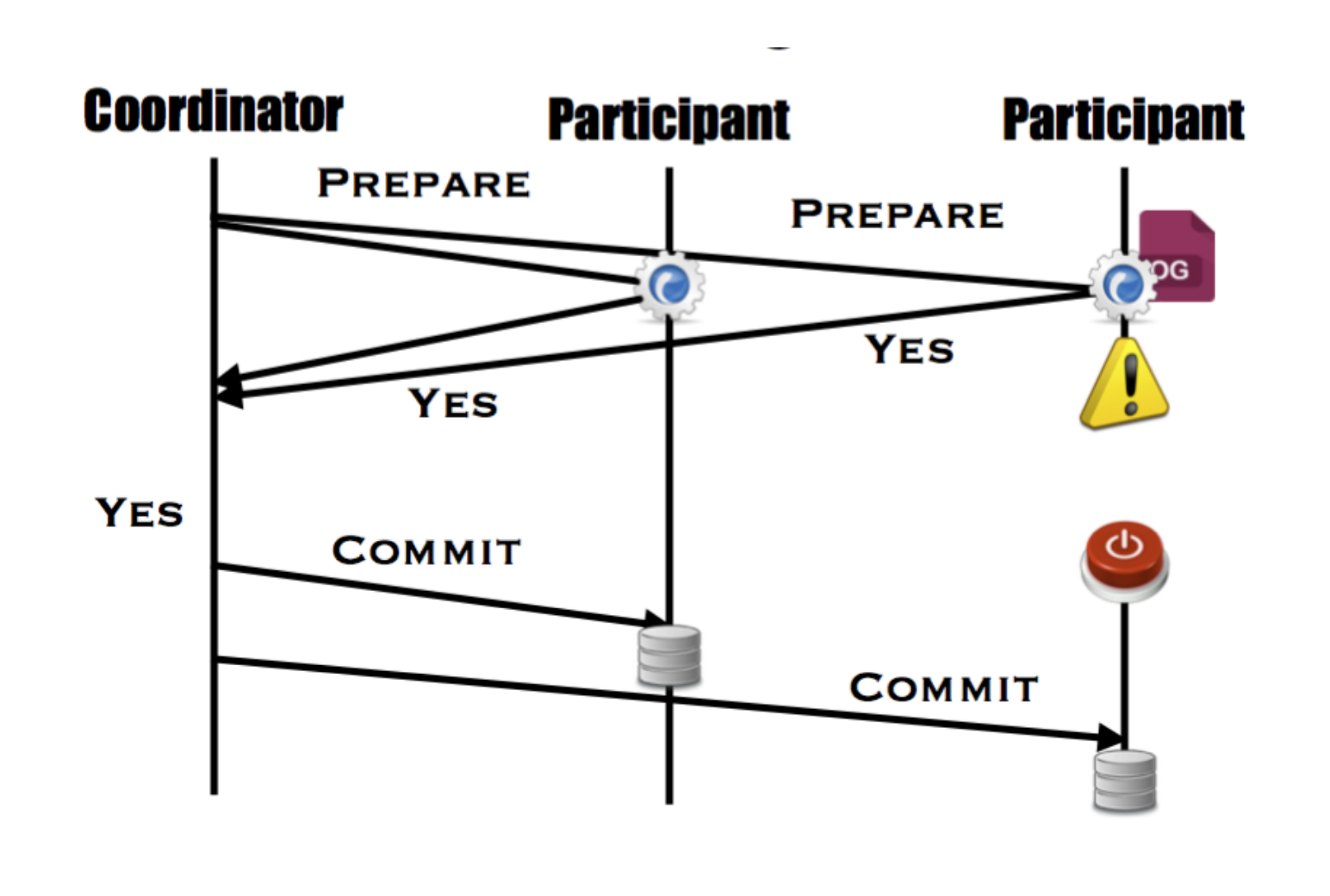
Participant Lost a Vote
宕机之后又恢复了,这时 participant 会询问 coordinator 目前应该进行什么操作,coordinator 就会比对自己的事务执行记录和该 participant 的事务执行记录,并告诉这个 participant 应该执行什么操作(当然也会告诉其 participant),来保持数据的一致性。
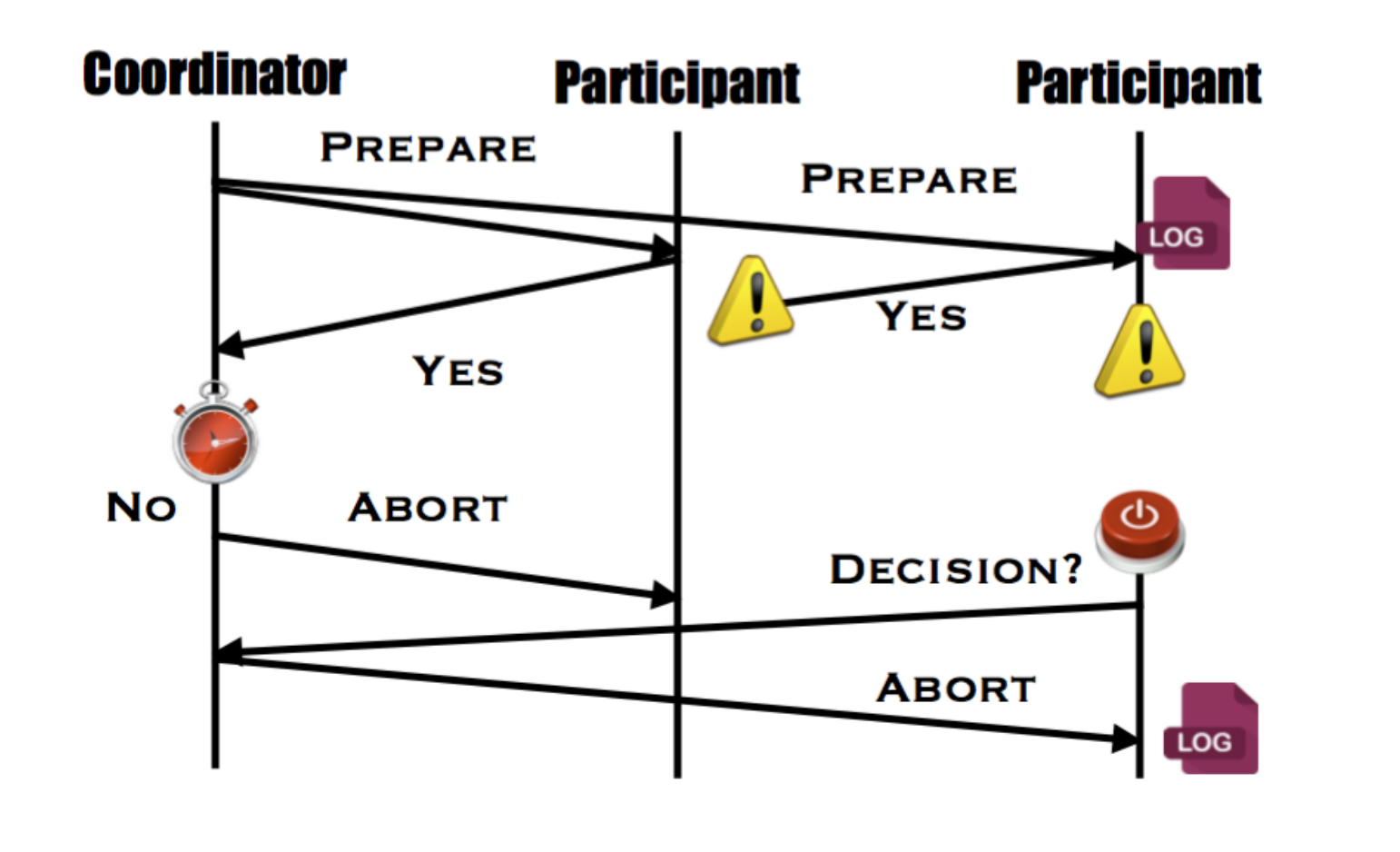
Case 3 - participant 宕机,coordinator也宕机
这种情况比较复杂,是两阶段提交无法完美解决的情况。
我们分别进行讨论。
coordinator 和 participant 在 voting phase 宕机了
新选出来的coordinator可以查看本地日志,或者询问各个participant 的情况。
- 如果 coordinator 还没有发送
prepare(可以从本地日志中得知),则发送prepare给各个 participant,并继续往下执行 - 如果 coordinator 已经发送了
prepare(可以从本地日志中得知),但并没有收到所有 participant 的返回,则再次发送prepare给各个 participant,以确认participant的状态,并继续执行 - 如果 coordinator 已经发送了
prepare(可以从本地日志中得知),但并没有收到部分 participant 的返回,则再次发送prepare给这些participant,以确认participant的状态,并继续执行 - 如果 coordinator 已经发送了
prepare(可以从本地日志中得知),且收到了所有 participant的返回,那当然也没问题,继续执行
这里均不会出现数据不一致的问题。
coordinator 和 participant 在 commit phase 宕机了
宕机了的这个participant ,在宕机之前并没有接收到coordinator的指令,或者接收到指令之后,还没来的及做 commit 或者 rollback 操作。
这种情况下,当新的coordinator被选出来之后,它先查询本地日志,并可能询问所有的 participant 的情况。
- 如果得知有的participant 执行了
rollback操作,就向 participant 发送rollback。 - 如果得知没有任何participant 执行
rollback操作,而且有的participant 执行了commit操作,那么就直接向其他 participant 发送commit
在这种情况下,不会导致数据不一致的现象。
两阶段提交的优缺点
优点
- 原理简单,易于实现
- 该协议是一个保证强一致性的协议
缺点
同步阻塞
The greatest disadvantage of the two-phase commit protocol is that it is a blocking protocol.
在 voting phase,如果参与者收不到协调者的commit/fallback指令,参与者将处于“状态未知”阶段,参与者完全不知道要怎么办,比如:如果所有的参与者完成第一阶段的回复后(可能全部yes,可能全部no,可能部分yes部分no),如果协调者在这个时候挂掉了。那么所有的结点完全不知道怎么办(问别的参与者都不行)。为了一致性,要么死等协调者,要么重发第一阶段的yes/no命令。
coordinator 单点故障(协调者挂了整个系统就没法对外服务)
coordinator在整个两阶段提交过程中扮演着举足轻重的作用,一旦coordinator宕机,那么就会影响整个分布式系统的正常运行,比如在 Voting Phase 中,如果coordinator因为故障不能正常发送事务提交或回滚通知给participant(这个故障可以是coordinator自身的故障,或者网络的故障),或者 coordinator 还没有收到所有 participant 发来的 Yes(比如由于网络故障) ,那么 participant 们的本地事务一直未被释放(因而导致查询性能下降)。
A two-phase commit protocol cannot dependably recover from a failure of both the coordinator and a cohort member during the Commit phase.
Both the coordinator and a cohort member failed, it is possible that the failed cohort member was the first to be notified, and had actually done the commit. Even if a new coordinator is selected, it cannot confidently proceed with the operation until it has received an agreement from all cohort members, and hence must block until all cohort members respond.
数据不一致性
两阶段提交协议虽然实现了数据的强一致性,但仍然存在数据不一致性的可能,比如在第二阶段中,假设coordinator发出了事务 commit 的通知,但是因为网络问题该通知仅被一部分participant 所收到并执行了 commit 操作,其余的 participant 的本地事务则因为没有收到通知一直处于阻塞状态,这时候就产生了数据的不一致性。
正是由于分布式事务存在很严重的性能问题,大部分高并发服务都在避免使用两阶段提交,而往往通过其他途径来解决数据一致性问题。
Implementation
DTM
- https://github.com/dtm-labs/dtm
- https://betterprogramming.pub/understanding-xa-transactions-with-practical-examples-in-go-67e99fd333db
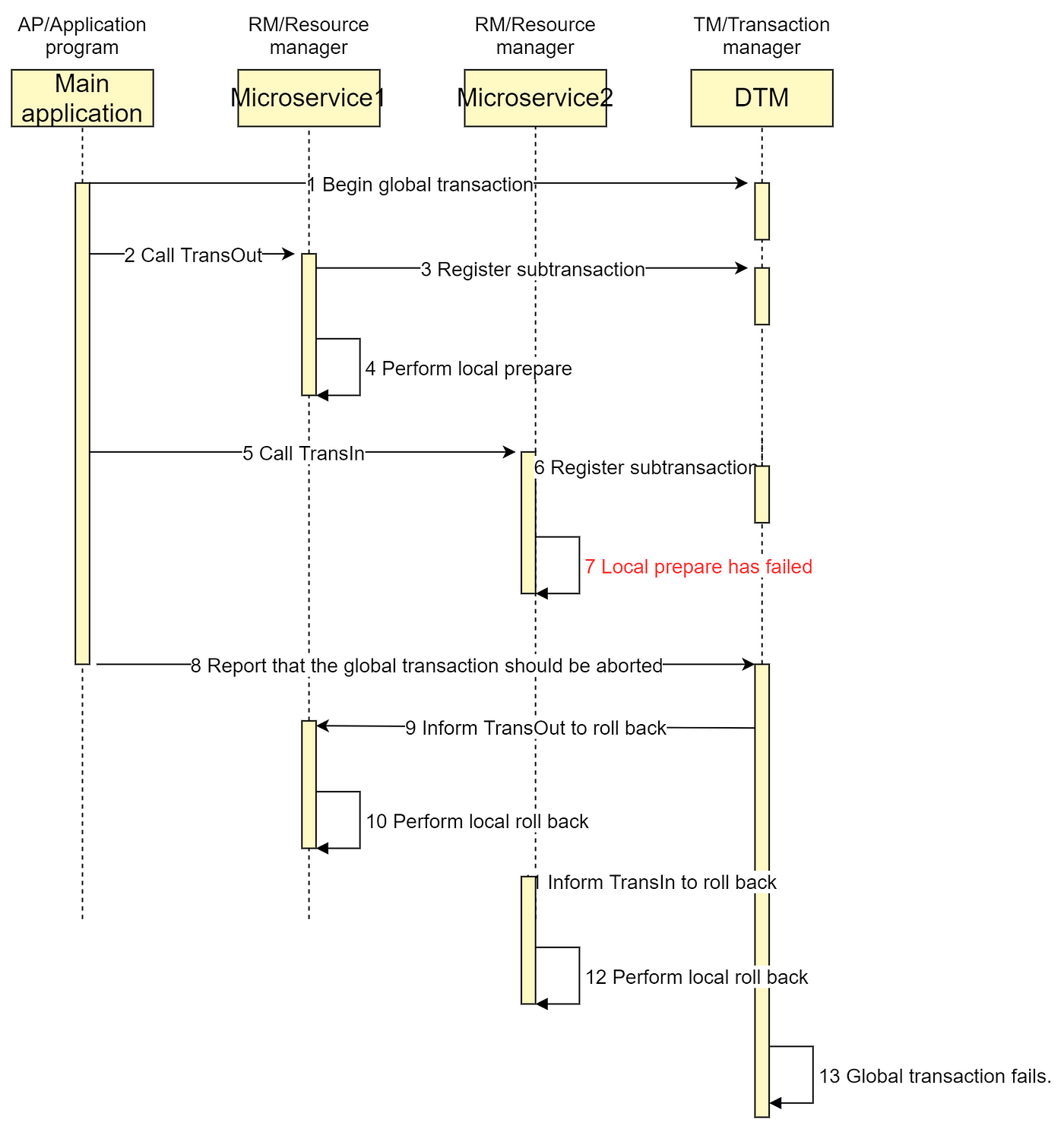
The following figure illustrates a successful global transaction:
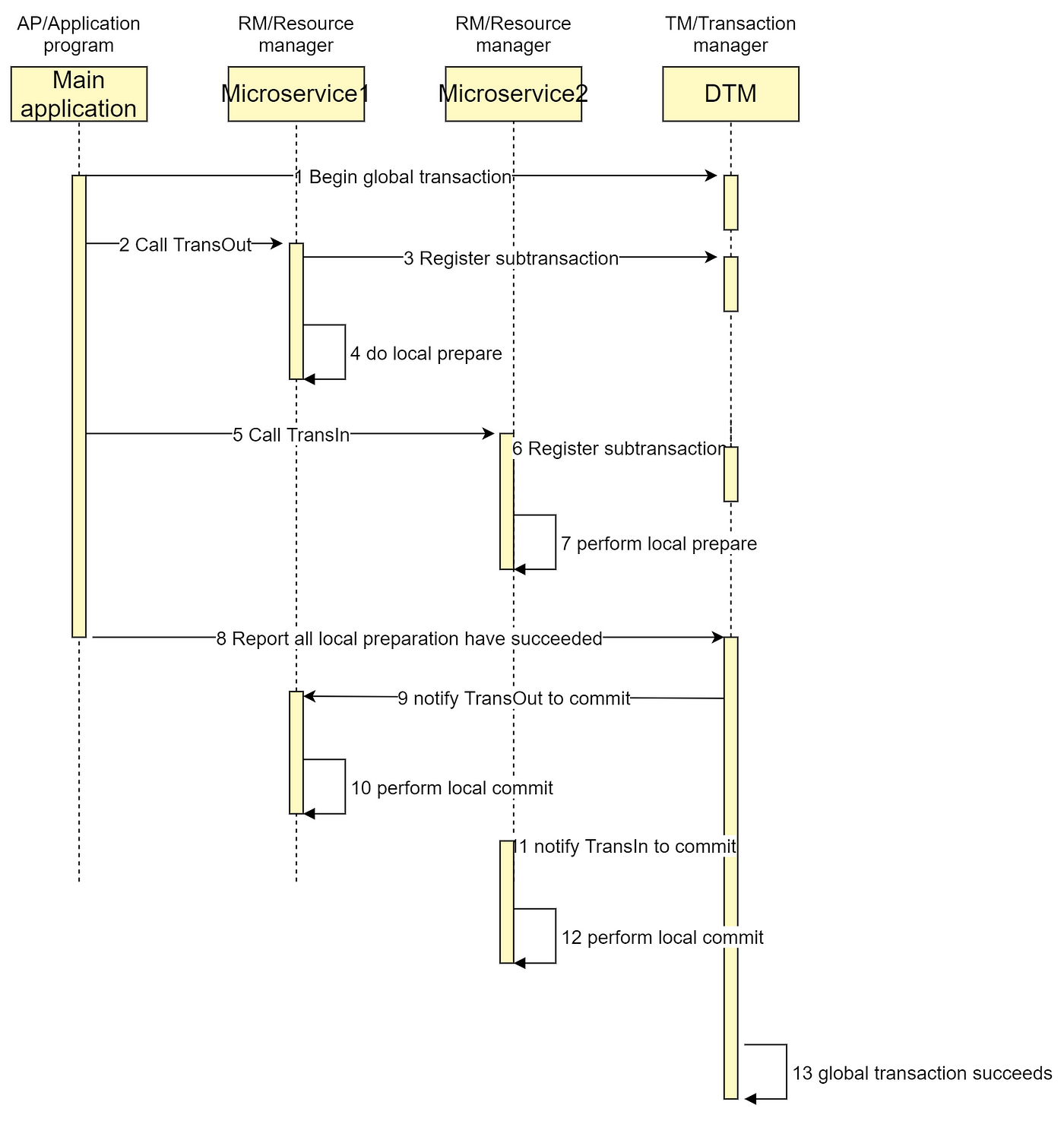
The timing diagram for failure is as follows:
Examples
Distributed databases like CockroachDB, MongoDB etc. implement two phase commit to atomically storing values across partitions
Kafka allows producing messages across multiple partitions atomically with the implementation similar to two phase commit.
Reference
- https://ecommons.cornell.edu/bitstream/handle/1813/6323/82-483.pdf?sequence=1&isAllowed=y
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
- Google App Engine的co-founder Ryan Barrett在2009年的google i/o上的演讲《Transaction Across DataCenter》
- https://coolshell.cn/articles/10910.html
- https://martinfowler.com/articles/patterns-of-distributed-systems/two-phase-commit.html
- https://en.wikipedia.org/wiki/Three-phase_commit_protocol
- https://en.wikipedia.org/wiki/X/Open_XA
- https://www.cs.princeton.edu/courses/archive/fall16/cos418/docs/L6-2pc.pdf
- https://alibaba-cloud.medium.com/tech-insights-two-phase-commit-protocol-for-distributed-transactions-ff7080eefe00
- https://mp.weixin.qq.com/s/ELgV-bqveOPOwTZIWG2X0w