日志服务
日志服务是我们应用程序后端不可或缺的一个组件,通常我们会组合使用 ELK(Elasticsearch+Logstash+Kibana)技术栈来自行搭建一个日志存储和分析系统。
为什么做日志系统
通常当系统发生故障时,工程师需要登录到各个服务器上,使用 grep / sed / awk 等 Linux 脚本工具去日志里查找故障原因。在没有日志系统的情况下,首先需要定位处理请求的服务器,如果这台服务器部署了多个实例,则需要去每个应用实例的日志目录下去找日志文件。每个应用实例还会设置日志滚动策略(如:每天生成一个文件),还有日志压缩归档策略等。 这样一系列流程下来,对于我们排查故障以及及时找到故障原因,造成了比较大的麻烦。因此,如果我们能把这些日志集中管理,并提供集中检索功能,不仅可以提高诊断的效率,同时对系统情况有个全面的理解,避免事后救火的被动。 总的来说有一下三点
- 数据查找:通过检索日志信息,定位相应的 bug,找出解决方案。
- 服务诊断:通过对日志信息进行统计、分析,了解服务器的负荷和服务运行状态
- 数据分析:可以做进一步的数据分析。
ELK
Why
ELK是什么东西,很好理解,就是收集(L:Logstash),存储(E:Elasticsearch),可视化日志(K:Kibana)的。
在前几年ELK为什么没有怎么听说,那是因为在服务器上 tail -f 就可以看日志,或者下载下来打开直接看。但是随着软件的不断发展,分布式,推荐系统,大数据等等,这些数据日积月累后的必然产物就诞生了。
就拿分布式系统来说,日志都分布在各个node上,要查看一个bug,需要登录到服务器上看好多node上的日志,再比如调用连很长的话,在服务器上看日志,或者下载下来看日志,我只能说有可能好几天都找不出来问题所在。还有登陆到服务器上,是一个很危险的信号,万一rm -rf,就真的是从入门到删库跑路了。以上种种问题怎么解决呢?这个时候就是ELK上场了。
ELK工作流程

在需要收集日志的所有服务上部署logstash,作为logstash agent(logstash shipper)用于监控并过滤收集日志,将过滤后的内容发送到Redis,然后logstash indexer将日志收集在一起交给全文搜索服务ElasticSearch,可以用ElasticSearch进行自定义搜索,通过Kibana 来结合自定义搜索进行页面展示。
部署方式
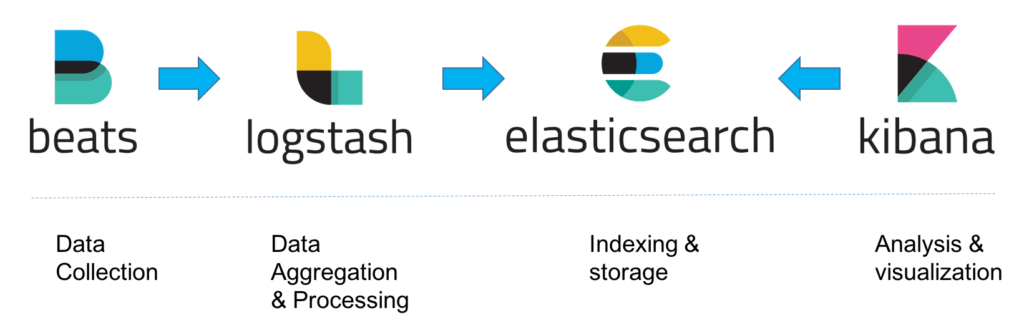
ELK部署最简单的方式就是L-E-K方式,不添加任何其他辅助系统,部署简单快速,容易上手。
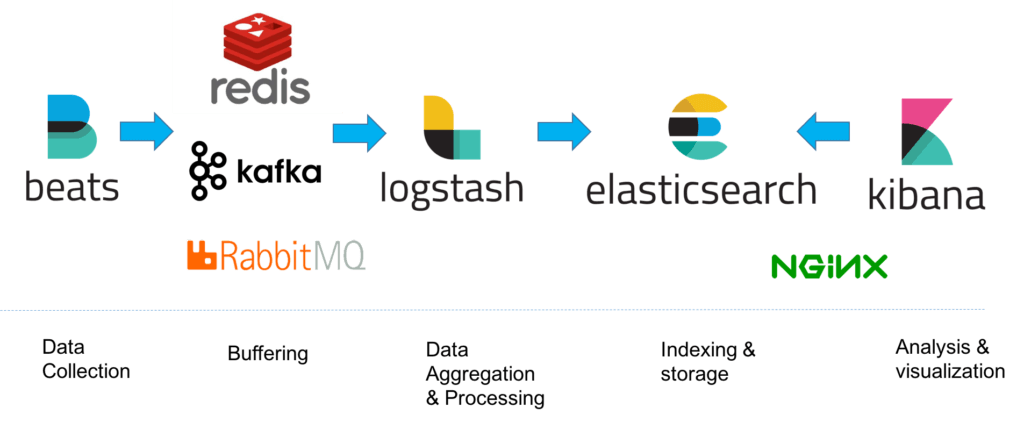
第二种方式:随着业务的增长,上面的方案已满足不了我们的需求,这个时候我们可以增加一层缓冲层,比如用消息队列(如Kafka)、Redis。
这种架构使用 Logstash 从各个数据源搜集数据,然后经消息队列输出插件输出到消息队列中。目前 Logstash 支持 Kafka、Redis、RabbitMQ 等常见消息队列。然后 Logstash 通过消息队列输入插件从队列中获取数据,分析过滤后经输出插件发送到 Elasticsearch,最后通过 Kibana 展示。
Elasticsearch
Elasticsearch是个开源分布式全文搜索和分析引擎(full-text search and analysis engine),它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash - Log Aggregator
Logstash是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(如用于搜索)。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana
Kibana 也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志
使用Filebeat来采集日志


Reference
- https://www.elastic.co/guide/en/elastic-stack-get-started/current/get-started-elastic-stack.html
- https://www.elastic.co/guide/index.html
- https://logz.io/learn/complete-guide-elk-stack/#elasticsearch
- https://www.jianshu.com/p/09beacb7dbf6
- https://zhuanlan.zhihu.com/p/45490773
- https://www.jianshu.com/p/934c457a333c
- https://hackernoon.com/elastic-stack-a-brief-introduction-794bc7ff7d4f