Analysis
Slice internals
A slice is a descriptor of an array segment. It consists of a pointer to the array, the length of the segment, and its capacity (the maximum length of the segment).

Our variable s, created earlier by make([]byte, 5), is structured like this:
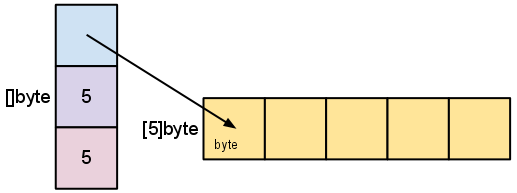
The length is the number of elements referred to by the slice. The capacity is the number of elements in the underlying array (beginning at the element referred to by the slice pointer).
Slice Slices
As we slice s, observe the changes in the slice data structure and their relation to the underlying array:
s := make([]byte, 5)
s = s[2:4]
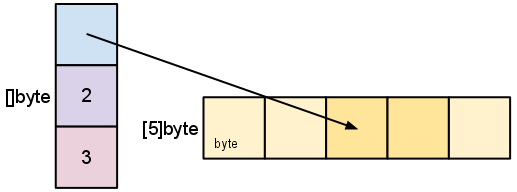
Slicing does not copy the slice’s data. It creates a new slice that points to the original array. This makes slice operations as efficient as manipulating array indices.
证明:
a := make([]byte, 5)
b := a[2:4]
var a1 = *(*[3]int)(unsafe.Pointer(&a))
var a2 = *(*[3]int)(unsafe.Pointer(&b))
fmt.Println(a1)
fmt.Println(a2)
// output
[824634404571 5 5]
[824634404573 2 3]
Therefore, modifying the elements (not the slice itself) of a re-slice modifies the elements of the original slice(这也再次说明了 slice 只是底层array的descriptor):
d := []byte{'r', 'o', 'a', 'd'}
e := d[2:]
// e == []byte{'a', 'd'}
e[1] = 'm'
// e == []byte{'a', 'm'}
// d == []byte{'r', 'o', 'a', 'm'}
Grow Slices’s Length
Let us grow a to its capacity by slicing it again:
a := make([]byte, 2, 3)
b := a[:cap(a)]
var a1 = *(*[3]int)(unsafe.Pointer(&a))
var a2 = *(*[3]int)(unsafe.Pointer(&b))
fmt.Println(a1)
fmt.Println(a2)
// ouput:
[824634404573 2 3]
[824634404573 3 3]
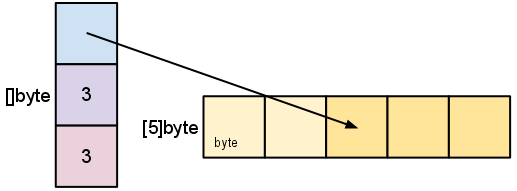
A slice cannot be grown beyond its capacity. Attempting to do so will cause a runtime panic, just as when indexing outside the bounds of a slice or array. Similarly, slices cannot be re-sliced below zero to access earlier elements in the array.
package main
import (
"fmt"
)
func main() {
a := make([]byte, 2, 3)
b := a[:100]
fmt.Println(b)
}
Output:
panic: runtime error: slice bounds out of range [:100] with capacity 3
goroutine 1 [running]:
main.main()
/Users/shiwei/SW/GoPlayground/sw.go:9 +0x4e
Process finished with exit code 2
Copy Slices
This example doubles the capacity of s by making a new slice, t, copying the contents of s into t, and then assigning the slice value t to s:
t := make([]byte, len(s), (cap(s)+1)*2) // +1 in case cap(s) == 0
for i := range s {
t[i] = s[i]
}
s = t
The looping piece of this common operation is made easier by the built-in copy function. As the name suggests, copy copies data from a source slice to a destination slice. It returns the number of elements copied.
func copy(dst, src []T) int
The copy function supports copying between slices of different lengths (it will copy only up to the smaller number of elements). In addition, copy can handle source and destination slices that share the same underlying array, handling overlapping slices correctly.
Using copy, we can simplify the code snippet above:
t := make([]byte, len(s), (cap(s)+1)*2)
copy(t, s)
s = t
Grow Slices
A common operation is to append data to the end of a slice. This function appends byte elements to a slice of bytes, growing the slice if necessary, and returns the updated slice value:
func AppendByte(slice []byte, data ...byte) []byte {
m := len(slice)
n := m + len(data)
if n > cap(slice) { // if necessary, reallocate
// allocate double what's needed, for future growth.
newSlice := make([]byte, (n+1)*2)
copy(newSlice, slice)
slice = newSlice
}
slice = slice[0:n]
copy(slice[m:n], data)
return slice
}
One could use AppendByte like this:
p := []byte{2, 3, 5}
p = AppendByte(p, 7, 11, 13)
// p == []byte{2, 3, 5, 7, 11, 13}
Functions like AppendByte are useful because they offer complete control over the way the slice is grown. Depending on the characteristics of the program, it may be desirable to allocate in smaller or larger chunks, or to put a ceiling on the size of a reallocation.
But most programs don’t need complete control, so Go provides a built-in append function that’s good for most purposes; it has the signature
func append(s []T, x ...T) []T
The append function appends the elements x to the end of the slice s, and grows the slice if a greater capacity is needed.
a := make([]int, 1)
// a == []int{0}
a = append(a, 1, 2, 3)
// a == []int{0, 1, 2, 3}
To append one slice to another, use ... to expand the second argument to a list of arguments.
a := []string{"John", "Paul"}
b := []string{"George", "Ringo", "Pete"}
a = append(a, b...) // equivalent to "append(a, b[0], b[1], b[2])"
// a == []string{"John", "Paul", "George", "Ringo", "Pete"}
Implementation
Definition
Compilation Phase
cmd/compile/internal/types.NewSlice 就是编译期间用于创建切片类型的函数:
func NewSlice(elem *Type) *Type {
if t := elem.Cache.slice; t != nil {
if t.Elem() != elem {
Fatalf("elem mismatch")
}
return t
}
t := New(TSLICE)
t.Extra = Slice{Elem: elem}
elem.Cache.slice = t
return t
}
上述方法返回结构体中的 Extra 字段是一个只包含切片内元素类型的结构,也就是说切片内元素的类型都是在编译期间确定的,编译器确定了类型之后,会将类型存储在 Extra 字段中帮助程序在运行时动态获取。
Runtime Phase
编译期间的切片是 cmd/compile/internal/types.Slice 类型的,但是在运行时切片可以由如下的 reflect.SliceHeader 结构体表示(在 64 位电脑上只有 24 字节),其中:
Data是指向数组的指针;Len是当前切片的长度;Cap是当前切片的容量,即Data数组的大小:
// /usr/local/go/src/reflect/value.go
// SliceHeader is the runtime representation of a slice.
// It cannot be used safely or portably and its representation may
// change in a later release.
// Moreover, the Data field is not sufficient to guarantee the data
// it references will not be garbage collected, so programs must keep
// a separate, correctly typed pointer to the underlying data.
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
Data 是一片连续的内存空间,这片内存空间可以用于存储切片中的全部元素,数组中的元素只是逻辑上的概念,底层存储其实都是连续的,所以我们可以将切片理解成一片连续的内存空间加上长度与容量的标识。
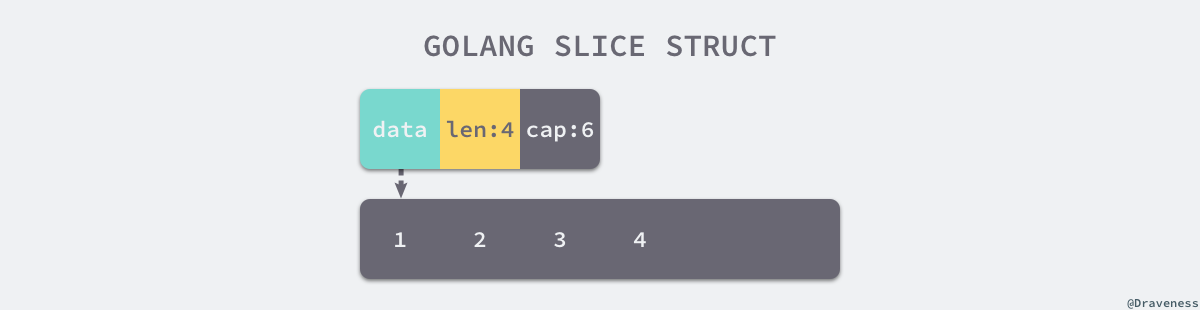
从上图中,我们会发现切片与数组的关系非常密切,切片引入了一个抽象层,提供了对数组中部分连续片段的引用,而作为数组的引用,我们可以在运行区间可以修改它的长度和范围。当切片底层的数组长度不足时就会触发扩容,切片指向的数组可能会发生变化,不过在上层看来切片是没有变化的,上层只需要与切片打交道不需要关心数组的变化。
你可以使用以下代码来查看slice的结构:
s := []string{"w", "a", "g"}
d := (*reflect.SliceHeader)(unsafe.Pointer(&s))
fmt.Println(*d)
第一个字段array指向底层数组的一个指针,len记录切片访问元素的个数(可访问长度) cap允许元素增长的个数(切片容量)
Initialization
Go 语言中包含三种初始化切片的方式:
- 通过下标的方式获得数组或者切片的一部分;
- 使用字面量初始化新的切片;
- 使用关键字
make创建切片:
arr[0:3] or slice[0:3]
slice := []int{1, 2, 3}
slice := make([]int, 10)
通过数组创建切片
通过数组创建切片是最原始也最接近汇编语言的方式,它是所有方法中最为底层的一种,编译器会将 arr[0:3] 或者 slice[0:3] 等语句转换成 OpSliceMake 操作,我们可以通过下面的代码来验证一下:
// ch03/op_slice_make.go
package opslicemake
func newSlice() []int {
arr := [3]int{1, 2, 3}
slice := arr[0:1]
return slice
}
通过 GOSSAFUNC 变量编译上述代码可以得到一系列 SSA 中间代码,其中 slice := arr[0:1] 语句在 “decompose builtin” 阶段对应的代码如下所示:
v27 (+5) = SliceMake <[]int> v11 v14 v17
name &arr[*[3]int]: v11
name slice.ptr[*int]: v11
name slice.len[int]: v14
name slice.cap[int]: v17
SliceMake 操作会接受四个参数并创建一个新的切片,分别是元素类型、数组指针、切片大小和容量。
需要注意的是使用通过数组创建切片,并不会拷贝原数组,而是创建一个指向原数组的切片结构体,所以
- 修改新切片中的值也会修改原数组的值
- 当然,修改原数组的值也会影响切片中的值
package main
import (
"fmt"
)
func main() {
a := [2]string{"1", "2"}
b := a[0:1]
a[0] = "0"
fmt.Println(b)
a[0] = "3"
fmt.Println(a)
}
// output:
[0]
[3 2]
字面量 Literal
当我们使用字面量 []int{1, 2, 3} 创建新的切片时,cmd/compile/internal/gc.slicelit 函数会在编译期间将它展开成如下所示的代码片段:
// /usr/local/go/src/cmd/compile/internal/gc/sinit.go
// 1.make a static array
var vstat [3]int
// 2. assign (data statements) the constant part, note that this step is optional (when there is no constant part)
vstat = constpart{}
// 3.make an auto pointer to array and allocate heap to it
var vauto *[3]int = new([3]int)
// 4.copy the static array to the auto array
*vauto = vstat
// 5. for each dynamic part assign to the array
vstat[0] = 1
vstat[1] = 2
vstat[2] = 3
// 6. assign slice of allocated heap to var
slice := vauto[:]
- 根据切片中的元素数量对底层数组的大小进行推断并创建一个数组;
- 初始化数组的constant 部分;
- 创建一个同样指向
[3]int类型的数组指针; - 将静态存储区的数组
vstat赋值给vauto指针所在的地址; - 将这些字面量元素存储到初始化的数组中;
- 通过
[:]操作获取一个底层使用vauto的切片;
第 6 步中的 [:] 就是使用下标创建切片的方法,从这一点我们也能看出 [:] 操作是创建切片最底层的一种方法。
代码实现:
// /usr/local/go/src/cmd/compile/internal/gc/sinit.go
func slicelit(ctxt initContext, n *Node, var_ *Node, init *Nodes) {
// make an array type corresponding the number of elements we have
t := types.NewArray(n.Type.Elem(), n.Right.Int64())
dowidth(t)
if ctxt == inNonInitFunction {
// put everything into static array
vstat := staticname(t)
fixedlit(ctxt, initKindStatic, n, vstat, init)
fixedlit(ctxt, initKindDynamic, n, vstat, init)
// copy static to slice
var_ = typecheck(var_, ctxExpr|ctxAssign)
var nam Node
if !stataddr(&nam, var_) || nam.Class() != PEXTERN {
Fatalf("slicelit: %v", var_)
}
var v Node
v.Type = types.Types[TINT]
setintconst(&v, t.NumElem())
nam.Xoffset += int64(slice_array)
gdata(&nam, nod(OADDR, vstat, nil), Widthptr)
nam.Xoffset += int64(slice_nel) - int64(slice_array)
gdata(&nam, &v, Widthptr)
nam.Xoffset += int64(slice_cap) - int64(slice_nel)
gdata(&nam, &v, Widthptr)
return
}
// recipe for var = []t{...}
// 1. make a static array
// var vstat [...]t
// 2. assign (data statements) the constant part
// vstat = constpart{}
// 3. make an auto pointer to array and allocate heap to it
// var vauto *[...]t = new([...]t)
// 4. copy the static array to the auto array
// *vauto = vstat
// 5. for each dynamic part assign to the array
// vauto[i] = dynamic part
// 6. assign slice of allocated heap to var
// var = vauto[:]
//
// an optimization is done if there is no constant part
// 3. var vauto *[...]t = new([...]t)
// 5. vauto[i] = dynamic part
// 6. var = vauto[:]
// if the literal contains constants,
// make static initialized array (1),(2)
var vstat *Node
mode := getdyn(n, true)
if mode&initConst != 0 && !isSmallSliceLit(n) {
vstat = staticname(t)
if ctxt == inInitFunction {
vstat.Name.SetReadonly(true)
}
fixedlit(ctxt, initKindStatic, n, vstat, init)
}
// make new auto *array (3 declare)
vauto := temp(types.NewPtr(t))
// set auto to point at new temp or heap (3 assign)
var a *Node
if x := prealloc[n]; x != nil {
// temp allocated during order.go for dddarg
if !types.Identical(t, x.Type) {
panic("dotdotdot base type does not match order's assigned type")
}
if vstat == nil {
a = nod(OAS, x, nil)
a = typecheck(a, ctxStmt)
init.Append(a) // zero new temp
} else {
// Declare that we're about to initialize all of x.
// (Which happens at the *vauto = vstat below.)
init.Append(nod(OVARDEF, x, nil))
}
a = nod(OADDR, x, nil)
} else if n.Esc == EscNone {
a = temp(t)
if vstat == nil {
a = nod(OAS, temp(t), nil)
a = typecheck(a, ctxStmt)
init.Append(a) // zero new temp
a = a.Left
} else {
init.Append(nod(OVARDEF, a, nil))
}
a = nod(OADDR, a, nil)
} else {
a = nod(ONEW, nil, nil)
a.List.Set1(typenod(t))
}
a = nod(OAS, vauto, a)
a = typecheck(a, ctxStmt)
a = walkexpr(a, init)
init.Append(a)
if vstat != nil {
// copy static to heap (4)
a = nod(ODEREF, vauto, nil)
a = nod(OAS, a, vstat)
a = typecheck(a, ctxStmt)
a = walkexpr(a, init)
init.Append(a)
}
// put dynamics into array (5)
var index int64
for _, value := range n.List.Slice() {
if value.Op == OKEY {
index = indexconst(value.Left)
if index < 0 {
Fatalf("slicelit: invalid index %v", value.Left)
}
value = value.Right
}
a := nod(OINDEX, vauto, nodintconst(index))
a.SetBounded(true)
index++
// TODO need to check bounds?
switch value.Op {
case OSLICELIT:
break
case OARRAYLIT, OSTRUCTLIT:
k := initKindDynamic
if vstat == nil {
// Generate both static and dynamic initializations.
// See issue #31987.
k = initKindLocalCode
}
fixedlit(ctxt, k, value, a, init)
continue
}
if vstat != nil && isLiteral(value) { // already set by copy from static value
continue
}
// build list of vauto[c] = expr
setlineno(value)
a = nod(OAS, a, value)
a = typecheck(a, ctxStmt)
a = orderStmtInPlace(a, map[string][]*Node{})
a = walkstmt(a)
init.Append(a)
}
// make slice out of heap (6)
a = nod(OAS, var_, nod(OSLICE, vauto, nil))
a = typecheck(a, ctxStmt)
a = orderStmtInPlace(a, map[string][]*Node{})
a = walkstmt(a)
init.Append(a)
}
make 关键字
Compilation Phase
如果使用字面量的方式创建切片,大部分的工作都会在编译期间完成。但是当我们使用 make 关键字创建切片时,很多工作都需要运行时的参与;调用方必须向 make 函数传入切片的大小以及可选的容量,类型检查期间的 cmd/compile/internal/gc.typecheck1 函数会校验入参:
// /usr/local/go/src/cmd/compile/internal/gc/typecheck.go
// The result of typecheck1 MUST be assigned back to n, e.g.
// n.Left = typecheck1(n.Left, top)
func typecheck1(n *Node, top int) (res *Node) {
switch n.Op {
...
case OMAKE:
args := n.List.Slice()
i := 1
switch t.Etype {
case TSLICE:
if i >= len(args) {
yyerror("missing len argument to make(%v)", t)
return n
}
l = args[i]
i++
var r *Node
if i < len(args) {
r = args[i]
}
...
if Isconst(l, CTINT) && r != nil && Isconst(r, CTINT) && l.Val().U.(*Mpint).Cmp(r.Val().U.(*Mpint)) > 0 {
yyerror("len larger than cap in make(%v)", t)
return n
}
n.Left = l
n.Right = r
n.Op = OMAKESLICE
}
...
}
}
上述函数不仅会检查 len 是否传入,还会保证传入的容量 cap 一定大于或者等于 len。除了校验参数之外,当前函数会将 OMAKE 节点转换成 OMAKESLICE,中间代码生成的 cmd/compile/internal/gc.walkexpr 函数会依据下面两个条件转换 OMAKESLICE 类型的节点:
- 切片的大小和容量是否足够小;
- 切片是否发生了逃逸,最终在堆上初始化
当切片发生逃逸或者非常大时,运行时需要 runtime.makeslice 在堆上初始化切片,如果当前的切片不会发生逃逸并且切片非常小的时候,make([]int, 3, 4) 会被直接转换成如下所示的代码:
var arr [4]int
n := arr[:3]
上述代码会初始化数组并通过下标 [:3] 得到数组对应的切片,这两部分操作都会在编译阶段完成,编译器会在栈上或者静态存储区创建数组并将 [:3] 转换成上一节提到的 OpSliceMake 操作。
Runtime Phase
分析了主要由编译器处理的分支之后,我们回到用于创建切片的运行时函数 runtime.makeslice,这个函数的实现很简单:
// Create a slice
// runtime/slice.go
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 根据类型大小获取可比较的最大长度
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// NOTE: Produce a 'len out of range' error instead of a
// 'cap out of range' error when someone does make([]T, bignumber).
// 'cap out of range' is true too, but since the cap is only being
// supplied implicitly, saying len is clearer.
// See golang.org/issue/4085.
mem, overflow := math.MulUintptr(et.size, uintptr(len))
// 比较容量和长度 比较容量和最大值
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
// panic 而不是 error 的原因是容量小于长度的切片会在编译时报错
panicmakeslicecap()
}
// 申请一块内存
return mallocgc(mem, et, true)
}
上述函数的主要工作是计算切片占用的内存空间并在堆上申请一片连续的内存,它使用如下的方式计算占用的内存:
内存空间=切片中元素大小×切片容量
虽然编译期间可以检查出很多错误,但是在创建切片的过程中,如果发生了以下错误,会直接触发运行时错误并panic:
- 内存空间的大小发生了溢出;
- 申请的内存大于最大可分配的内存;
- 传入的长度小于 0 或者长度大于容量;
runtime.makeslice 在最后调用的 runtime.mallocgc 是用于申请内存的函数,这个函数的实现还是比较复杂,如果遇到了比较小的对象会直接初始化在 Go 语言调度器里面的 P 结构中,而大于 32KB 的对象会在堆上初始化。
在之前版本的 Go 语言中,数组指针、长度和容量会被合成一个 runtime.slice 结构,但是从 cmd/compile: move slice construction to callers of makeslice 提交之后,构建结构体 reflect.SliceHeader 的工作就都交给了 runtime.makeslice 的调用方,该函数仅会返回指向底层数组的指针,调用方会在编译期间构建切片结构体:
func typecheck1(n *Node, top int) (res *Node) {
switch n.Op {
...
case OSLICEHEADER:
switch
t := n.Type
n.Left = typecheck(n.Left, ctxExpr)
l := typecheck(n.List.First(), ctxExpr)
c := typecheck(n.List.Second(), ctxExpr)
l = defaultlit(l, types.Types[TINT])
c = defaultlit(c, types.Types[TINT])
n.List.SetFirst(l)
n.List.SetSecond(c)
...
}
}
OSLICEHEADER 操作会创建我们在上面介绍过的结构体 reflect.SliceHeader,其中包含数组指针、切片长度和容量,它是切片在运行时的表示:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
正是因为大多数对切片类型的操作并不需要直接操作原来的 runtime.slice 结构体,所以 reflect.SliceHeader 的引入能够减少切片初始化时的少量开销,该改动不仅能够减少 ~0.2% 的 Go 语言包大小,还能够减少 92 个 runtime.panicIndex 的调用,占 Go 语言二进制的 ~3.5%1。
Access Elements
//TODO
Copy Slices
Compilation Phase
// /usr/local/go/src/cmd/compile/internal/gc/walk.go
func copyany(n *Node, init *Nodes, runtimecall bool) *Node {
// runtime/slice.go
func slicecopy(to, fm slice, width uintptr) int {}
Append Elements and Grow Slices
// runtime/slice.go
// growslice handles slice growth during append.
// It is passed the slice element type, the old slice, and the desired new minimum capacity,
// and it returns a new slice with at least that capacity, with the old data
// copied into it.
// The new slice's length is set to the old slice's length,
// NOT to the new requested capacity.
// This is for codegen convenience. The old slice's length is used immediately
// to calculate where to write new values during an append.
// TODO: When the old backend is gone, reconsider this decision.
// The SSA backend might prefer the new length or to return only ptr/cap and save stack space.
func growslice(et *_type, old slice, cap int) slice {
if raceenabled {
callerpc := getcallerpc()
racereadrangepc(old.array, uintptr(old.len*int(et.size)), callerpc, funcPC(growslice))
}
if msanenabled {
msanread(old.array, uintptr(old.len*int(et.size)))
}
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
if et.size == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve old.array in this case.
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For sys.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
// The check of overflow in addition to capmem > maxAlloc is needed
// to prevent an overflow which can be used to trigger a segfault
// on 32bit architectures with this example program:
//
// type T [1<<27 + 1]int64
//
// var d T
// var s []T
//
// func main() {
// s = append(s, d, d, d, d)
// print(len(s), "\n")
// }
if overflow || capmem > maxAlloc {
panic(errorString("growslice: cap out of range"))
}
var p unsafe.Pointer
if et.ptrdata == 0 {
p = mallocgc(capmem, nil, false)
// The append() that calls growslice is going to overwrite from old.len to cap (which will be the new length).
// Only clear the part that will not be overwritten.
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
// Only shade the pointers in old.array since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem)
}
}
memmove(p, old.array, lenmem)
return slice{p, old.len, newcap}
}
Discussion
Potential Performance Issue - Hold A Big Arrary
As mentioned earlier, re-slicing a slice doesn’t make a copy of the underlying array. The full array will be kept in memory until it is no longer referenced. Occasionally this can cause the program to hold all the data in memory when only a small piece of it is needed.
For example, this FindDigits function loads a file into memory and searches it for the first group of consecutive numeric digits, returning them as a new slice.
var digitRegexp = regexp.MustCompile("[0-9]+")
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return digitRegexp.Find(b)
}
This code behaves as advertised, but the returned []byte points into an array containing the entire file. Since the slice references the original array, as long as the slice is kept around the garbage collector can’t release the array; the few useful bytes of the file keep the entire contents in memory.
To fix this problem one can copy the interesting data to a new slice before returning it:
func CopyDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
b = digitRegexp.Find(b)
c := make([]byte, len(b))
c = append(c, b...)
return c
}
Reference
- https://blog.golang.org/slices-intro
- https://blog.golang.org/slices
- https://github.com/golang/go/wiki/SliceTricks
- https://research.swtch.com/godata
- https://zhuanlan.zhihu.com/p/28399762
- https://draveness.me/golang/docs/part2-foundation/ch03-datastructure/golang-array-and-slice/
- https://zhuanlan.zhihu.com/p/282096939