HBase
HBase is an open-source non-relational distributed database
Use Apache HBase when you need random, realtime read/write access to your Big Data. This project’s goal is the hosting of very large tables – billions of rows X millions of columns – atop clusters of commodity hardware.
Apache HBase is an open-source, NoSQL, distributed big data store. It enables random, strictly consistent, real-time access to petabytes of data.
HBase is a column-oriented, non-relational database. This means that data is stored in individual columns, and indexed by a unique row key.
特性
底层的LSM数据结构和RowKey有序排列等架构上的独特设计,使得Hbase写入性能也非常高,可支持千万级高并发。
HBase 写入速度快是因为数据并不是真的立即落盘,而是先写入内存,随后异步刷入HFile。所以在客户端看来,写入速度很快。
HBase从自身读写性能对比而言,是一种读比写慢的数据库。
Data Model
Terminology
命名空间(Name Spaces)
HBase 中的命名空间是表的逻辑分组,类似 RDBMS 中的数据库实例,这种抽象为多租户的相关功能奠定了基础。命名空间包含:
- 表(Table):所有表都是命名空间的成员,即表必须属于某个命名空间,若没有指定,则建在 default 命名空间中。
- RS 组(RegionServer Group):一个命名空间或一张表可以被固定到一组 RegionServer 上,从而保证了数据的隔离性。
- 权限管理(Permission):可定义控制访问列表(ACL),例如,创建表、读取表、更新表、删除表等操作。
- 配额管理(Quota):限制一个命名空间可以使用的资源(Region 或者 Table 等)。
表(Table)
HBase 中的数据以表的形式存储于 Region 中。同一个表中的数据通常是相关的,使用表主要是可以把某些列组织起来一起访问。表名作为 HDFS 存储路径的一部分来使用,在 HDFS 中可以看到每个表名都作为独立的目录结构。
Region
- 一张表(Table)在 HBase 中会被**水平切分(row key 范围)**成多个 Region。
- 假设你有一张表叫 user_logs,包含大量用户数据(row key 是用户ID)。HBase 会自动把这张表切分成多个 Region,比如下表,这些 Region 会被分布到不同的 RegionServer 上,提升并发性和负载均衡。
| Region 范围 (row key)** |
|---|
| 0000 - 0999 |
| 1000 - 1999 |
| 2000 - 2999 |
Region 结构(简化):
Table
└── Region A (rowkey: 0000 - 0999)
│ ├── Column Family 1 -> Store -> HFile
│ └── Column Family 2 -> Store -> HFile
└── Region B (rowkey: 1000 - 1999)
└── ...
可以看到,同一个 rowkey 的数据,一定位于同一个 region,该 rowkey 不同 Column Family 的column 的值会被存储在不同的 HFile
Region有点像Kafka里的 Partition 的概念,目的是实现 horizential scalability。
行键(Row Key)
访问 HBase 表中的行,有三种方式:
- 通过 get 方式,指定 RowKey 获取唯一一条记录
- 通过 scan 方式,设置 startRow 和 stopRow 参数进行范围匹配
- 全表扫描,即直接扫描整张表中所有行记录
在 HBase 表里,每一行代表一个数据对象,每一行都以行键来进行唯一标识,是用来检索记录的主键。行键可以是任意字符串,最大长度是 64KB, 实际应用中长度一般为 10-100bytes.
在 HBase 内部,行键是不可分割的字节数组,并且行键是按照字典排序(byte order)由低到高存储在表中的。设计 Key 时,要充分考虑排序存储这个特性,将经常一起读取的行存储放到一起(位置相关性)。注意:字典排序对 int 类型排序的结果是 1,10,100,11,12,13,14,15,16,17,18,19,2,20,21 … 。因此要保持 int 的自然序,行键必须用 0 作左填充。
行的一次读写是原子操作(不论一次读写多少列),这个设计决策能够使用户很容易理解程序在对同一个行进行并发更新操作时的行为。
在 HBase 中可以针对行键建立索引,以提高检索数据的速度。
列族(Colunm Family)
HBase 中的列族是一些列的集合,必须在使用表之前进行定义,每个列必须归属于某个列族,列族的名字必须是可显示的字符串,列族中所有列成员的列名都以列族名字作为前缀,例如,info:name, info:age 都属于 info 这个列族。
列族支持动态扩展,用户可以很轻松地添加一个列族或列,无须预定义列的数量以及类型。但需要注意的是,访问控制、磁盘和内存的使用统计都是在列族层面进行的,列族越多,在取一行数据时所需要参与 I/O、搜寻的文件就越多,所以,如果没有必要,不要设置太多的列族。
列族中的所有列均以字符串形式存储,用户在使用时需要自行进行数据类型的转换。
列标识(Column Qualifier)
列族中的数据通过列标识来进行定位,属于某一个列族,类似 RDBMS 表中的字段名。列标识没有特定的数据类型,以二进制字节来存储。通常以 Column Family:Colunm Qualifier 来确定列族中的某列。
单元格(Cell)
每一个行键、列族、列标识共同确定一个单元格,最小单元格还需要加上时间戳。单元格的内容也没有特定的数据类型,以二进制字节来存储。最小单元格可以用以下元组方式来进行访问:
<RowKey,Column Family:Column Qualifier,Timestamp>
时间戳(Timestamp)
在默认情况下,每一个单元格插入数据时都会用时间戳来进行版本标识,每个单元格保存着同一份数据的多个版本,不同时间版本的数据按照时间先后倒序排序,最新的数据排在最前面。版本通过时间戳来索引,时间戳的类型是 64 位整型,其格式是毫秒级 Unix 时间戳。
读取单元格数据时,如果时间戳没有被指定,则默认返回最新的数据;写入新的单元格数据时,时间戳可以由客户显式赋值,如果没有设置,默认使用精确到毫秒的当前系统时间。如果应用要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
每一个列族的单元数据的版本数量都被 HBase 单独维护,默认情况下 HBase 保留 3 个版本数据,另外 HBase 还提供了两种数据版本回收方式:
- 保存数据的最后 n 个版本
- 保存最近一段时间内的版本(设置数据的生命周期 TTL)
用户可以针对每个列族进行设置。
逻辑模型
表是 HBase 中数据的逻辑组织方式,从用户视角来看,HBase 表的逻辑模型如下图所示:
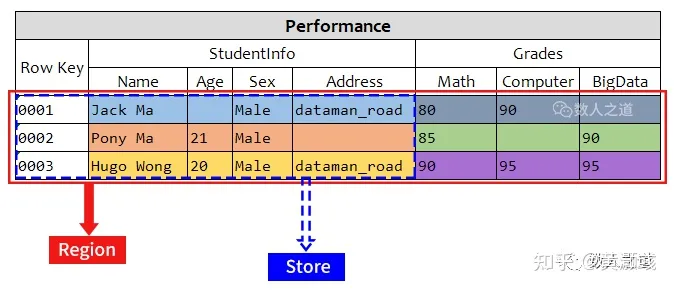
上图展示的是 HBase 中的学生成绩表 Performance:有四行记录和两个列族,行键分别为 0001、0002、0003 和 0004,两个列族分别为 StudentInfo 和 Grades, 每个列族中含有若干列。表存储在 Region 中,列族存放在 Store 中(HBase 架构中会介绍)。
从上图的表逻辑模型来看,HBase 表与 RDBMS 中的表结构之间似乎没有太大差异,只不过多了列族的概念,但实际上是有很大差别的。
RDBMS 中表的结构需要预先定义,如列名及其数据类型和约束等内容,如果需要添加新列,则需要修改表结构,这会对已有的数据产生很大影响。而在 HBase 中,列不是固定的表结构,在创建表时,不需要预先定义列名,可以在插入数据时临时创建。
同时,RDBMS 中的表为每个列预留了存储空间,即上图表中的空白 Cell 数据在 RDBMS 中以“NULL”值占用存储空间。而在 HBase 中,如上图表中的空白 Cell 在物理上是不占用存储空间的,即不会存储空白的键值对。因此,若一个请求获取 RowKey 为 0001 的 StudentInfo:Age 值时,其结果为空。类似地,若一个请求获取 RowKey 为 0002 的 StudentInfo:Address 值时,其结果也为空。
物理模型
与面向行存储的关系型数据库不同,HBase 是面向列存储的,且在实际的物理存储中,列族是分开存储的,即学生成绩表将被存储为 StudentInfo 和 Grades 两个部分。
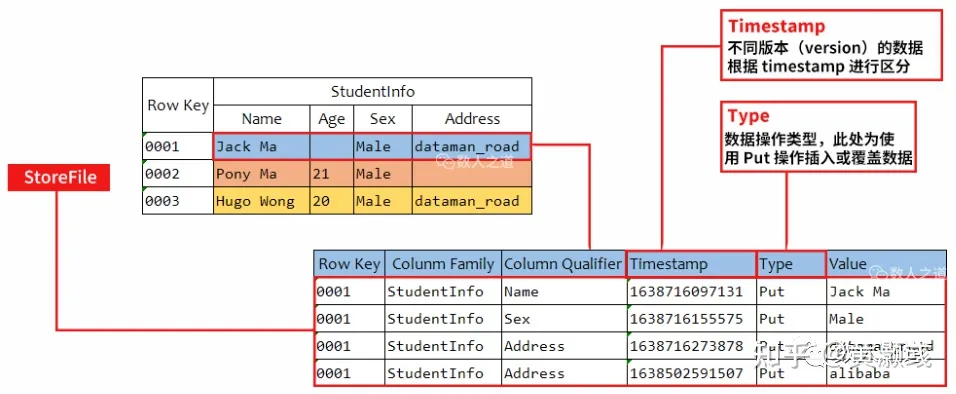
上图展示了 StudentInfo 这个列族中 RowKey 为 0001 的数据的实际物理存储方式,列族的数据会从内存写到 StoreFile 中(HBase 架构中会介绍)。可以看到空白 Cell 是没有被存储下来的。
在上图中还可以看到,0001 的 StudentInfo:Address 存储了两个版本的数据,通过时间戳(Timestamp)区分开来,最新的数据放在前面,在没有指定的情况下默认读取此最新版本的数据(dataman_road 而非 alibaba)。通过加上时间戳指定可读取旧版本的数据:
<0001,StudentInfo:Address,1638502591507>
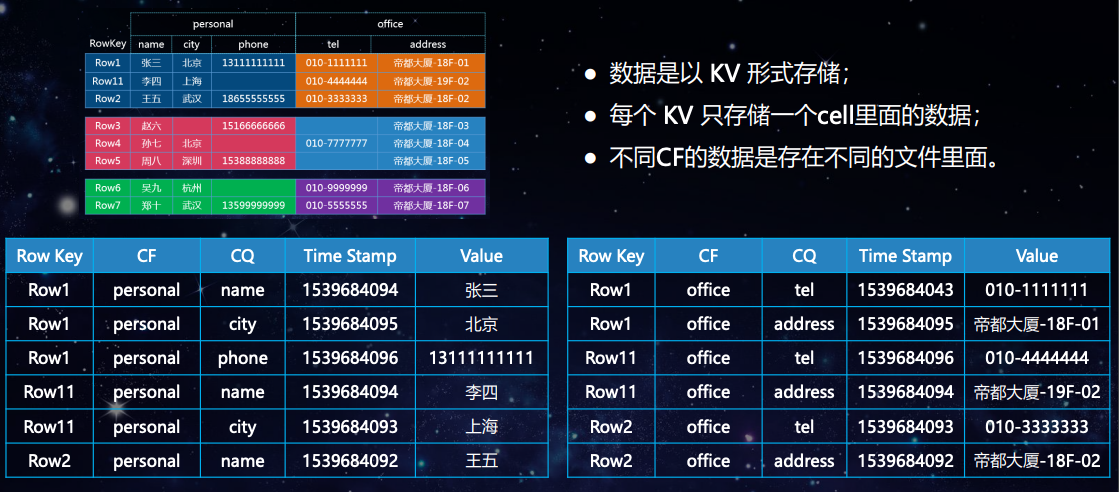
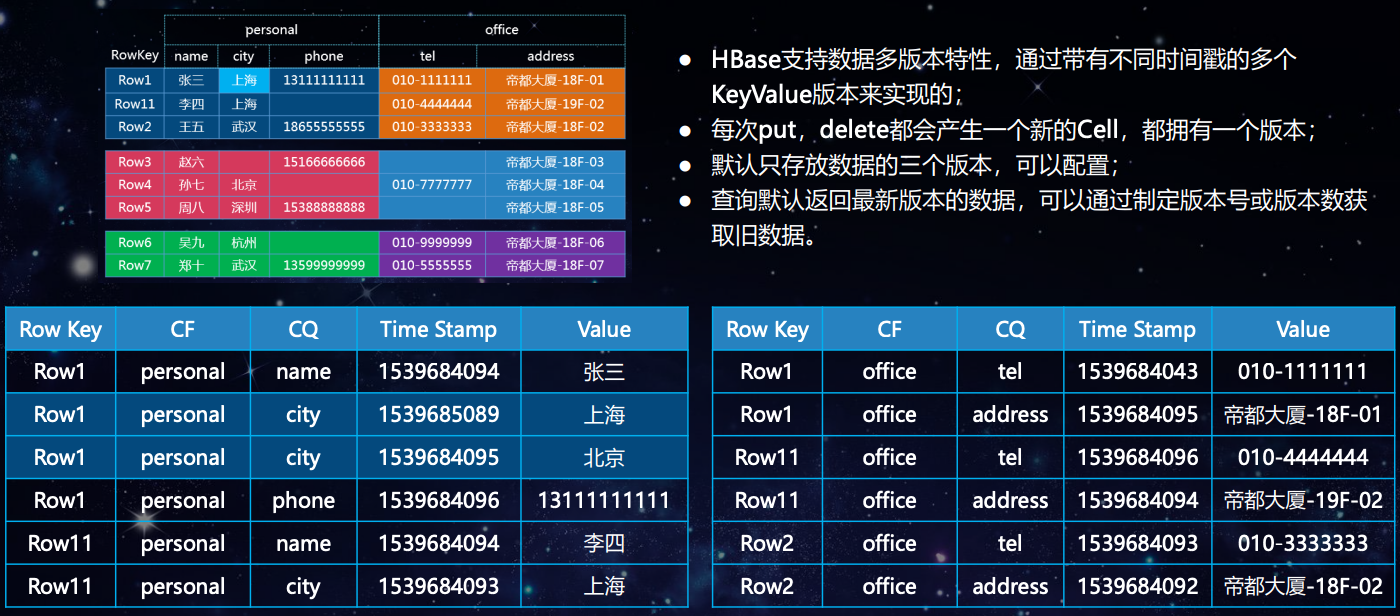
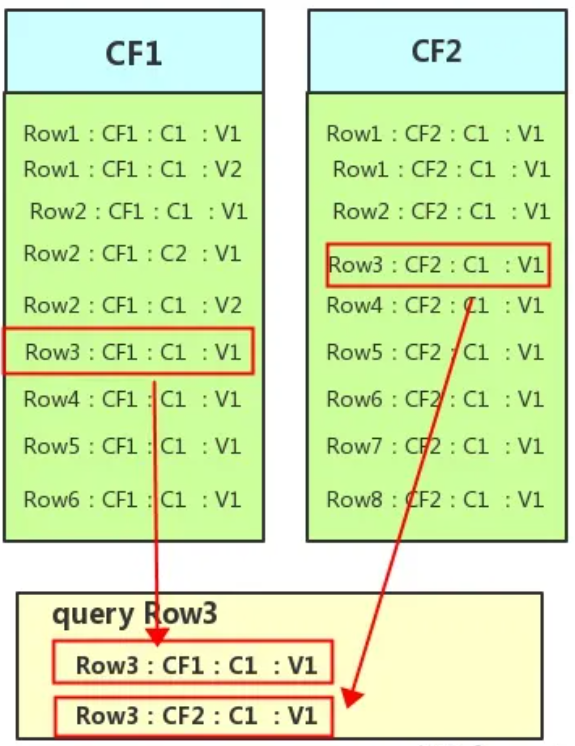
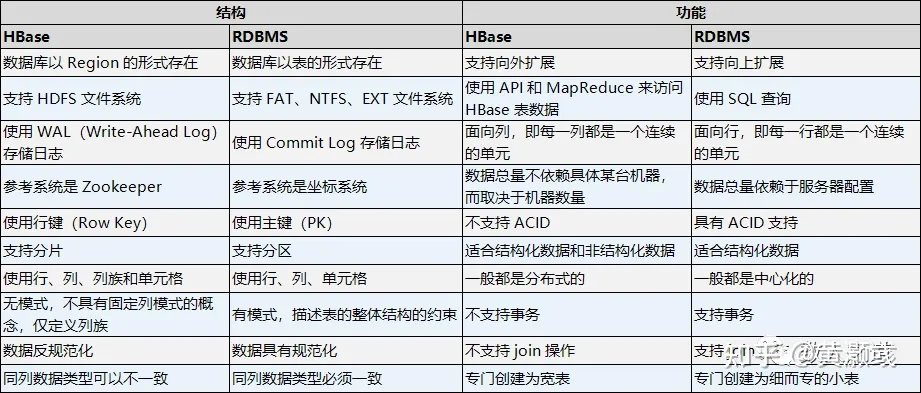
HBase 与 RDBMS 的区别
HBase 介于 NoSQL 和 RDBMS 之间,可以存储结构化和半结构化的松散数据,因此它不具备 RDBMS 的一些特点,例如,它不支持 SQL 的跨行事务(可通过 Hive 来实现多表 join 等复杂操作),也不要求数据之间有严格的范式关系,同时它允许在同一列的不同行中存储不同类型的数据。
HBase 与 RDBMS 在结构和功能方面的具体区别如下:
物理存储
整体结构

场景
- 写密集型应用,每天写入量巨大,而相对读数量较小的应用,比如IM的历史消息,游戏的日志等等
- 不需要复杂查询条件来查询数据的应用,HBase只支持基于rowkey的查询,对于HBase来说,单条记录或者小范围的查询是可以接受的,大范围的查询由于分布式的原因,可能在性能上有点影响,而对于像SQL的join等查询,HBase无法支持。
- 对性能和可靠性要求非常高的应用,由于HBase本身没有单点故障,可用性非常高。
- 数据量较大,而且增长量无法预估的应用,HBase支持在线扩展,即使在一段时间内数据量呈井喷式增长,也可以通过HBase横向扩展来满足功能。
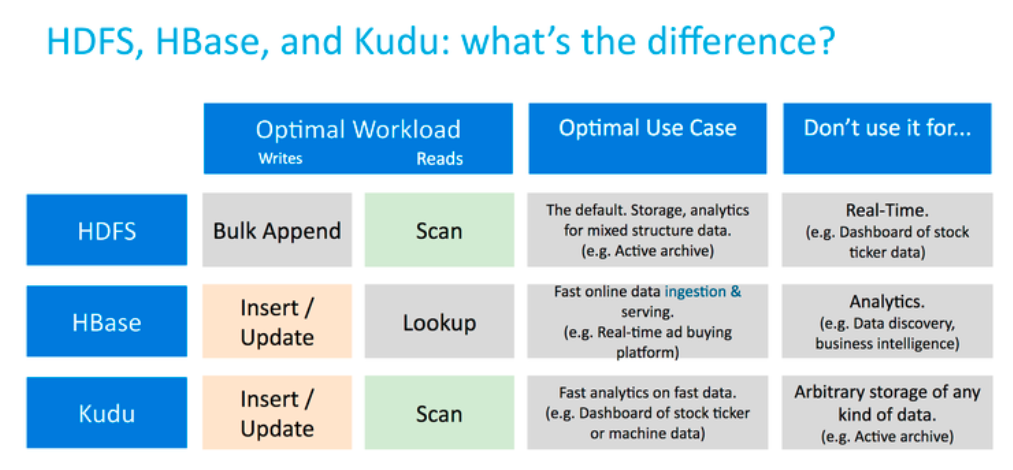
Cloudera在推出新的列存储引擎Kudu的时候讨论过HDFS,HBase,和Kudu的应用场景。
用户画像
标签数据是稀疏矩阵的代表,描述了实体的各类属性,主要应用于智能推荐、商务智能或营销引擎等领域。
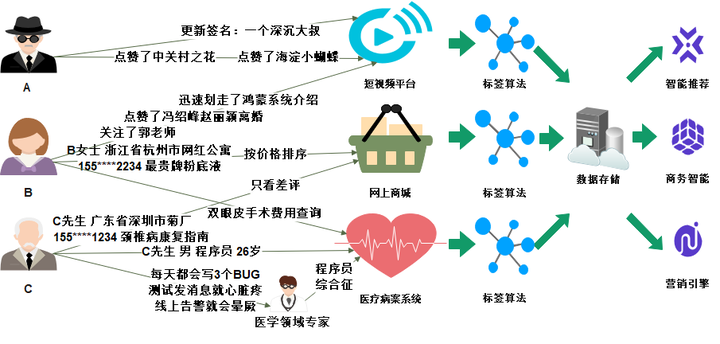
三个不同的用户在同一公司旗下的不同APP中留下了大量的行为数据,这些数据中包含了直接填写的用户资料、使用APP的具体行为以及领域专家对某些现象的标记,通过后台的标签算法可以得到这样的数据:
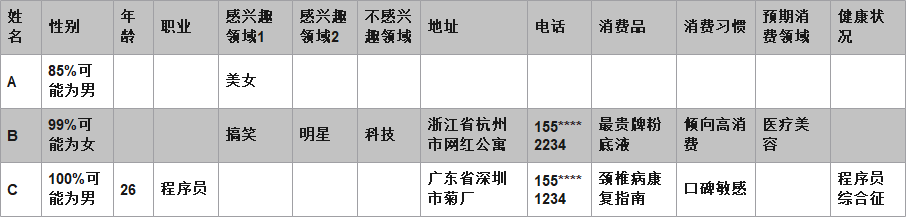
我们能发现,对用户行为采集存在局限性,因此所能得到的标签种类各不相同,表中大量的数据项只能被置空,也就是所谓的稀疏矩阵。而且随着用户更深度的使用APP,可以预见到,对用户感兴趣领域/不感兴趣领域会逐渐被发掘,那么表的列也会随之增加。这样的特点对于MySQL是灾难性的,这是因为在MySQL建表时就必须定义表结构,属性的动态增删是巨大的工作量,同时大量NULL值的存储会导致存储成本变得难以接受。但是使用HBase存储时,未指定value的列不会占用任何的存储空间,因而可以将有限的资源高效利用,且HBase表在创建时只需指定ColumnFamily,而对于Column的增删极为容易,有利于应对未来属性的扩张。
如何设计row key
在 HBase 中,定位一条数据(即一个 Cell)我们需要 4 个维度的限定:行键(RowKey)、列族(Column Family)、列限定符(Column Qualifier)、时间戳(Timestamp)
热点现象产生
HBase 中的行是按照 Rowkey 的字典顺序排序的,这种设计优化了 scan 操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于 scan。
然而糟糕的 Rowkey 设计是热点的源头。 热点发生在大量的 client 直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。
大量访问会使热点 region 所在的单个机器超出自身承受能力,引起性能下降甚至 region 不可用,这也会影响同一个 RegionServer 上的其他 region,由于主机无法服务其他 region 的请求,这样就造成 数据热点现象。 (这一点其实和数据倾斜类似)
所以我们在向 HBase 中插入数据的时候,应优化 RowKey 的设计,使数据被写入集群的多个 region,而不是一个。尽量均衡地把记录分散到不同的 Region 中去,平衡每个 Region 的压力。
避免数据热点的方法
在日常使用中,主要有 3 个方法来避免热点现象,分别是反转,加盐和哈希,下面咱们逐个举例分析:
Reversing
Reversing 的原理是反转一段固定长度或者全部的键
abc.iteblog.com -> moc.golbeti.cba
www.iteblog.com -> moc.golbeti.www
cdn.iteblog.com -> moc.golbeti.ndc
def.iteblog.com -> moc.golbeti.fed
优缺点:有效地打乱了行键,但是却牺牲了行排序的属性。
Salting
Salting 的原理是将固定长度的随机数放在行键的起始处
foo0001 -> afoo0001
foo0002 -> bfoo0002
foo0003 -> cfoo0003
foo0004 -> dfoo0004
优缺点:由于前缀是随机生成的,因而如果想要按照字典顺序找到这些行,则需要做更多的工作。从这个角度上看,salting增加了写操作的吞吐量,却也增大了读操作的开销
Hashing
Hashing 的原理将RowKey进行hash计算,然后取 hash的部分字符串和原来的RowKey进行拼接。
foo0001 -> aaafoo0001
foo0002 -> bbbfoo0002
foo0003 -> cccfoo0003
foo0004 -> dddfoo0004
Or
- For example: I have two ID 123456783 and 123456789 and our function is (mod 10).
- Then: 123456783 → (mod 10) → 3, 123456789 → (mod 10) → 9.
- So: the final row key should be 3123456783 and 9123456789
优缺点:可以一定程度打散整个数据集,但是不利于Scan;由于不同数据的hash值可能 一样,实际应用中可以使用md5计算,然后截取前几位的字符串。如下:
subString(MD5(设备ID), 0, x) + 设备ID,其中x一般取5或6。
RowKey 的设计原则
RowKey 长度原则
Reference
- HBase:The Definitive Guide
- https://en.wikipedia.org/wiki/Apache_HBase
- https://hbase.apache.org/
- Bigtable: A Distributed Storage System for Structured Data
- https://www.zhihu.com/question/39859266
- https://xie.infoq.cn/article/3f8918d3ef064b7b6b2382e1b
- https://developer.aliyun.com/article/685870