我每天都在使用URL,每天和他打交道。但是,在阅读《HTTP权威指南》后,才发现我对URL的理解是不全面的、碎片化的。
1.URL的历史
在因特网的历史上**,统一资源定位符(URL,Uniform Resource Locator)的发明是一个非常基础的步骤。统一资源定位符的语法是一般的,可扩展的。它存在的目的,是使用ASCII代码**的一部分来表示互联网的地址。
2.URL的构成
URL提供了一种定位因特网上任意资源的手段,但这些资源是可以通过各种不同的 scheme(比如HTTP、FTP、SMTP)来访问的,因此URL语法会随 scheme 的不同而有所不同。
这是不是意味着每种不同的 URL scheme 都会有完全不同的语法呢?实际上,不是的。 大部分URL都遵循通用的URL语法,而且不同 URL scheme 的风格和语法都有不少重叠。
大多数 URL scheme 的 URL 语法都建立在这个由 9 部分构成的通用格式上:
几乎没有哪个 URL 中包含了所有这些组件。URL 最重要的3个部分是 scheme、host 和 path。
| 组件 | 描 述 | 默认值 |
|---|---|---|
| Scheme | 访问服务器以获取资源时要使用的某种协议 | 无 |
| User | 某些 Scheme 访问资源时需要的用户名 | 匿名 |
| Password | 用户名后面可能要包含的密码,中间由冒号“:”分割 | |
| Host | 资源宿主服务器的主机名或 IP 地址 | 无 |
| Port | 资源宿主服务器正在监听的端口号.很多方案都有默认端口号(HTTP 的默认端口号为80) | 每个方案特有 |
| Path | 服务器上资源的本地名,由一个斜扛“/”将其与前面的 URL 组件分隔开来(稍后会讲到URL路径可以分为若干个段,每段都可以有其特有的组件) | 无 |
| Param | 某些 Scheme 会用这个组件来指定输入参数,格式为名/值对。 URL中可以包含多个 Param 字段,它们相互之间以及与 Param组件 的其余部分组件之间用分号“;”分隔 | 无 |
| Query | 某些 Scheme 会用这个组件传递参数给服务器,或标识查询条件,用字符“?”将 Query组件 与URL的其余部分分隔开 | 无 |
| Fragment | 一些客户端,不会将frag字段传送给服务器,这个字段是在客户端内部(比如浏览器内部)使用的,通过“#”字符将其与URL的其余组件分割开来 | 无 |
比如,我们来看看 URL: http://vww.joes-hardware.com:80/indcx,html ,其scheme是 HTTP, host是www.joes-hardware.com ,Port是 80,Path为/index.html。
3.URL中组件含义
3.1 scheme -> 使用什么协议
scheme 实际上是规定如何访问指定资源的主要标识符,它会告诉负责解析URL的应用程序应该使用什么协议。在我们这个简单的 HTTP URL 中所使用的 scheme 就是 HTTP。
scheme 必须以一个字母符号开始,由第一个“:”符号将其与URL的其余部分分隔开来。scheme名是大小写无关的,因此URL“http://www.joes-hardware.com” 和 “HTTP://www.jocs-hardware.conT 是等价的。
3.2 host 与 port -> 域名与端口
要想在因特网上找到资源,应用程序要知道是哪台机器装载了资源,以及在那台机器的什么地方可以找到能对目标资源进行访问的服务器。URL的 host 和 port 提供了这两组信息。
Host 组件标识了因特网上能够访问资源的宿主机器。可以用上述主机名(www.joes-hardware.com),或者IP地址来表示主机名。
比如,下面两个 URL 就指向同一个资源:
-
第一个 URL 是通过主机名
-
第二个是通过 IP 地址指向服务器的
port 标识了服务器正在监听的网络端口。对下层使用了 TCP 协议的 HTTP 来说,默认端口号为80。
3.3 username 和 password -> 用户名与密码
部分服务器都要求输入 username 和 password 才会允许用户访问数据。比如FTP服务器。这里有几个例子:
第一个例子中,没有username和password组件,只有标准的方案、主机和路径。如果某应用程序使用的URL方案要求输入username和password,比如FTP,但用户没有提供,它通常会插入一个默认的用户名和密码。比如,如果向浏览器提供一个FTP URL,但没有指定用户名和密码,它就会插入anonymous (匿名用户)作为你的用户名,并发送一个默认的密码(Internet Explorer会发送IEUser,Netscape Navigator則会发送 mozilla)。
第二个例子中,显示了一个指定为anonymous的用户名。这个用户名与主机组件组合在一起,看起来就像E-mail地址一样。字符“@”将用户和密码组件与URL的其余部分分隔开来。
第三个例子中,指定了用户名(joe)和密码(joespasswd),两者之间由字符“:”分隔。
3.4 path -> 路径
URL的 path 说明了资源位于服务器的什么地方。路径通常很像一个分级的文件系统路径。比如:
这个URL中的 Path 为/seasonal/index-fall.html,很像UNIX文件系统中的文件系统路径。路径是服务器定位资源时所需的信息。可以用字符“/”将HTTP URL的路径组件划分成一些路径段(path segment)(还是与UNIX文件系统中的文件路径类似)。每个路径段都有自己的参数(param)组件。
3.5 param -> 参数
对很多方案来说,只有简单的主机名和到达对象的路径是不够的。除了服务器正在监听的端口,以及是否能够通过用户名和密码访问资源外,很多协议都还需要更多的信息才能工作。
负责解析URL的应用程序需要这些协议参数来访问资源。否则,被请求的服务器可能就不会为请求提供服务,或者更糟糕的是,提供错误的服务。比如,像FTP这样的协议,有两种传输模式,二进制和文本形式。你肯定不希望以文本形式来传送二进制图片,这样的话,二进制图片可能会变得一团糟。
为了向应用程序提供它们所需的输入参数,以便正确地与服务器进行交互,URL中有一个参数组件。这个组件就是URL中的名值对列表,由字符“;”将其与URL的其余部分(以及各名值对)分隔开来。在每个param组内部,用字符“=”来区分key和value。它们为应用程序提供了访问资源所需的所有附加信息。比如:
在这个例子中,有一个参数typc=d,参数名为type,值为d。
如前所述,HTTP URL的路径组件可以分成若干路径段。每段都可以有自己的参数。比如:
这个例子就有两个路径段,hammers和index.html。hammers路径段(sale=false)有参数sale,其值为 false。index.html段(graphics=true)有参数 graphics,其值为 true。
3.6 quiery(quirystring) -> 查询条件
很多资源,比如数据库服务,都是可以通过提问题或进行査询来缩小所请求资源类型范围的。
假设Joe的五金商店在数据库中维护着一个未售货物的淸单,并可以对淸单进行査询,以判断产品是否有货,那就可以用下列URL来査询Web数据库网关,看看编号为12731的条目是否有货:
除了有些不合规则的字符需要特别处理之外(某些字符需要URL编码),对査询组件的格式没什么要求。按照常规,很多服务器都希望査询字符串以一系列“名/值”对的形式出现,名值对之间用字符“&”分隔:
在这个例子中,査询组件有两个名/值对:item=12731和color=blue。
3.7 frag -> 片段
有些资源类型,比如HTML,除了资源级之外,还可以做进一步的划分。比如,对一个带有章节的大型文本文档来说,资源的URL会指向整个文本文档,但我们更期望的是,提供一种方式使能够指向到资源中某些章节或位置。
为了引用部分资源或资源的一个片段,URL支持使用片段(frag)组件来表示一个资源内部的片段。比如,URL可以指向HTML文档中一个特定的图片或小节。
片段在URL的最右边,最前面以一个字符‘#’将其与其他组件区分。比如:
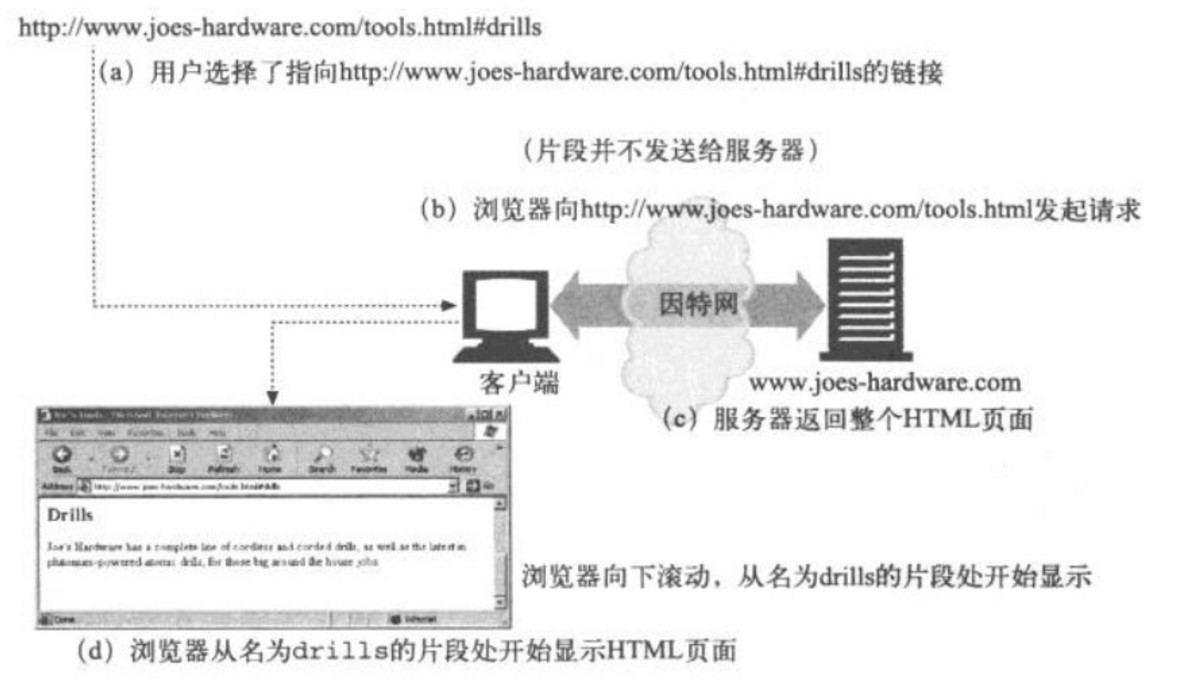
在这个例子中,片段drills引用了五金商店Web服务器上页面/tools.html中的一个部分。这部分的名字叫做drills。
HTTP服务器通常只处理在URL中除 Frag 以外的元素,因此客户端也不能将 Frag 组件传送给服务器(参考下图)。但是,浏览器会记录下此前的Frag值,当从服务器获得了整个资源之后,浏览器会把该Frag值填充到URL中,并根据 Frag 来显示你感兴趣的那部分资源。
4.理解URL构成的意义
在日常开发中,我们可能会碰到以下需求:
-
从一个URL中提取出host
-
从一个URL中提取出querystring中的所有元素
我们可以根据URL格式的定义,从://后,可能包含[User:Password@] ,也可能不包含,所以可以以URL字符串中是否包含“@”字符做为判断是否包含[User:Password@] ,如果包含那“@”之后就是host(当然还要考虑host后的param和querystring),具体思路就不展开了。当然,你也可以用正则表达式来提取,但是你仍然需要参考URL的标准格式定义。
更全面与详细的URL定义与约定,你可以查询RFC。
5.URL、URN、URI 区别
5.1 定义
URN(Uniform Resource Name):唯一标识一个实体的标识符,但不给出实体的位置。 URI(Uniform Resource Identifier):是一个紧凑的字符串用来标示抽象或物理资源的标识符。 URL(Uniform Resource Locator):除了确定一个资源外,还提供一种定位该资源的标识符。
5.2 关系
以下这种图足以概括三者的关系:
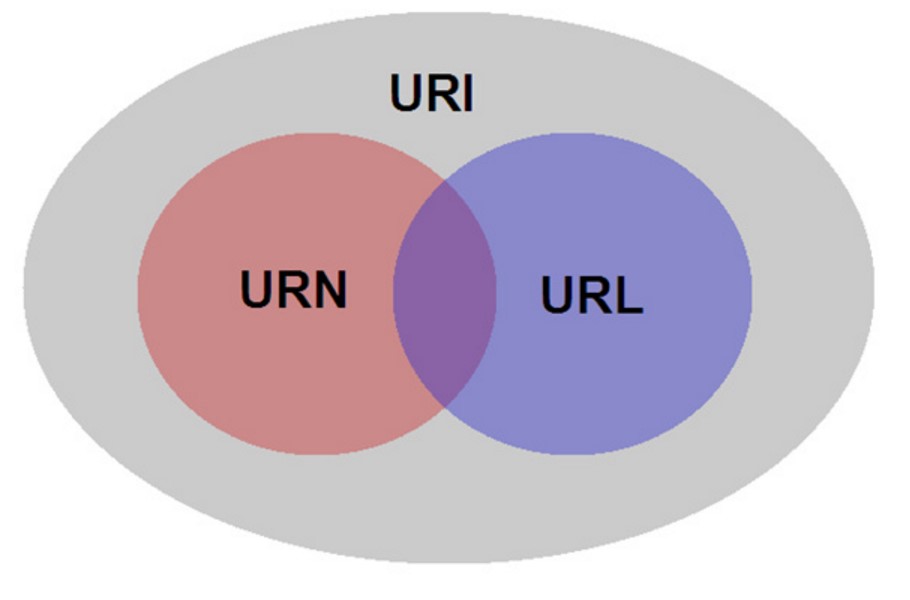
概括的来说,URL 和 URN 都是 URI,但是 URI 不一定是 URL 或者 URN。
具体来说:
URL是URI的一种,不仅标识了Web 资源,还指定了操作或者获取方式,同时指出了主要访问机制和网络位置。一个恰当的比喻,一个人的住址是一个URL,通过这个URL你可以准确找到这个人(根据URL可以准确获取到某个 Web 资源)。
URN是URI的一种,用特定命名空间的名字标识资源。可以用URN来唯一标识一个实体,可以在不知道其网络位置及访问方式的情况下讨论资源。一个恰当的比喻,书籍的ISBN码或产品在系统内的序列号是一个URN,尽管没有告诉你用什么方式或者到什么地方去找到目标,但是你有足够的信息来检索到它。
5.3 注意
我们经常使用的URI不是严格技术意义上的URL。例如,你需要的文件在files.hp.com。 这是 URI,但不是 URL,因为未指定确定的 scheme、port 及 path。
因此你去http://files.hp.com 和[ftp://files.hp.com](ftp://files.hp.com/),可能得到完全不同的内容。
所以,用 URI 吧,这样你通常技术上是正确的,URL可不一定。最后“URL”这个术语正在被弃用。
6.URL编码
6.1 产生URL编码的原因
(1) 使URL中可存在其他语言的字符
默认的计算机系统字符集通常都倾向于以英语为中心。从历史上来看,很多计算机应用程序使用的都是US-ASCII字符集。US-ASCII使用7位二进制码来表示英文打字机提供的大多数按键和少数用于文本格式和硬件通知的不可打印控制字符。
由于US-ASCII的历史悠久,所以其可移植性很好。但是,虽然美国用户使用起来很便捷,它却并不支持有其他语言的字符存在。这意味着,在URL中不能包含除其他语言的字符,例如中文。
因此,需要设立一种转义机制,用US-ASCII字符集的有限子集对任意字符值进行编码,从而实现在URL中可以包含全世界范围内各种各样的语言。
(2)使URL中存在的某些字符不存在歧义
例如在URL中存在 query 字符串,query 字符串中存在key=value这样的参数对,键值对之间以“&”符号分隔,例如a=a1&b=b1&c=c1&d=d1。
但是如果某个参数对的value中包括了“=”或“&”字符等具有特殊含义的字符,就会产生歧义(比如,query 字符串为:a=a&1 & b=b1 & c=c1 & d=d1,我们原本期望a=a&1,而实际上去被理解成了a=a),这就会造成服务器在解析整个 query 字符串时出错。
因此,对于一些有特殊含义的字符,我们需要进行转义。
6.2 哪些字符需要编码
那么问题来了,哪些字符需要编码?且如何编码?
RFC3986文档规定,URL中只允许包含英文字母(a-z or A-Z)、数字(0-9)、-_.~4个特殊字符以及所有保留字符。
RFC3986文档对URL的编解码问题做出了详细的建议,指出了哪些字符需要被编码才不会引起URL语义的转变,以及对为什么这些字符需要编码做出了相应的解释。
为了避幵安全字符集表示法带来的限制,人们设计了一种编码机制,用来在URL中表示各种不安全的字符。这种编码机制就是通过一种“转义”表示法来表示非US-ASCII字符集中可表示的大小写字母和数字、不安全字符和保留字符,这种转义表示法包含一个百分号(%),后面跟着两个表示字符ASCII码的十六进制数,所以通常 URL 编码又称为百分号编码。
接下来我们来明确,哪些字符需要编码:
(1)保留字符
如第3节 URL中组件含义中描述到,URL由若干组件组成,有一些字符是用于分隔不同URL组件(:/@;?#)。如:“//”用于分隔 scheme 和 host,“:”用于区分 host 和 port,等等。还有一些字符用于在特定组件中起到分隔作用,我们统称这些字符为保留字符。比如“;”**在 param 组件中分隔各个元素,“&”在 query组件中分隔各个元素。
RFC3986中指定了以下字符为保留字符:
| ! | * | ' | ( | ) | : | ; | @ | & |
|---|---|---|---|---|---|---|---|---|
| = | + | $ | , | / | ? | # | [ | ] |
**当普通数据中包括上述特殊字符时,需要对其进行URL编码,否则就会歧义。**例如上面的例子,我们本希望表达URL 的 query 组件为:a=a&1&b=b1&c=c1&d=d1,但是这是错误的!而正确的方式应该是将a&1进行URL编码,为:a=a%261&b=b1&c=c1&d=d1。
(2)不安全字符
还有一些字符,当他们直接放在 URL中的时候,可能会引起解析程序的歧义。这些字符被视为不安全字符。
对于不安全字符,我们需要将其进行URL编码后才能放置在 URL 中。
| 空格 | URL 在传输的过程,或者用户在排版的过程,或者文本处理程序在处理 URL 的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉 |
|---|---|
| 引号以及<> | 引号和尖括号通常用于在普通文本中起到分隔 URL 的作用 |
| # | 通常用于表示书签或者锚点 |
| % | 百分号本身用作对不安全字符进行编码时使用的特殊字符,因此本身需要编码 |
| {}^[]`~ | 某一些网关或者传输代理会篡改这些字符 |
需要记住:
-
合法字符出现在URL中时,对其编码和不编码都是一样的。比如“a”,无论是http://www.111.com/list?query=a,还是http://www.111.com/list?query=%62 都是一样的。
-
但是,如果
保留字符或不安全字符出现在 URL 的普通数据中,且未对其进行 URL 编码,则会产生歧义。 -
因此,一个经过 URL 编码的 URL,只有普通英文字符、数字和保留字符存在。
6.3 如何编码
我们来讨论一下如何进行 URL编码:
对于ASCII字符集中的字符,用不用百分号表示均可。比如,http://www.111.com/list?query=a,和http://www.111.com/list?query=%62 均是正确的。
对于不存在于ASCII字符集中的字符,需要用ASCII字符集的超集(比如UTF-8)来表示,且再加上“%”。 例如“Url编码”,使用UTF-8编码得到的字节是0x55 0x72 0x6C 0xE7 0xBC 0x96 0xE7 0xA0 0x81,由于前三个字节存在于ASCII字符集中,因此这三个字节可以用“Url”直接表示。最终经过URL编码则为“Url%E7%BC%96%E7%A0%81” ./当然,如果你用"%55%72%6C%E7%BC%96%E7%A0%81”也是可以的。
需要强调的是,URL编码是一种通过“转义”表示法来表示非US-ASCII字符集中字符的编码机制,但URL编码本身其实未定义“如何用US-ASCII字符集来表示非US-ASCII字符集中字符”。
举个例子,我希望对大大傻进行URL编码,我既可以用UTF-8的方式,也可以用GB2312的方式(当然也还可以用别的)。
- 如果用UTF-8的编码方式,进行URL编码后是
%e5%a4%a7%e5%a4%a7%e5%82%bb(“大”对应的UTF8编码是0xE5 0xA4 0xA7,“傻”对应的UTF8编码是0xE5 0x82 0xBB) - 如果用GB2312的编码方式,进行URL编码后是
%b4%f3%b4%f3%c9%b5(“大”对应的GB2312编码是0xB4 0xF3,“傻”对应的GB2312编码是0xC9 0xB5)
可以发现,URL编码本质只是一种使用%来转义非US-ASCII字符集中字符的机制,但是具体使用不同的编码方式进行URL编码,得到的结果是不同的。
但是,有时我们会默认URL编码中的编码方式是UTF-8,而不去显式的约定(因为,这也是URL编码的最佳实践编码方式)。