出现背景
1 线程不安全的HashMap
因为多线程环境下,使用Hashmap进行put操作会引起死循环(infinite loop),导致CPU利用率接近100%(【Java】集合类 - HashMap 的并发问题),所以在并发情况下不能使用HashMap。
2 效率低下的HashTable容器
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。
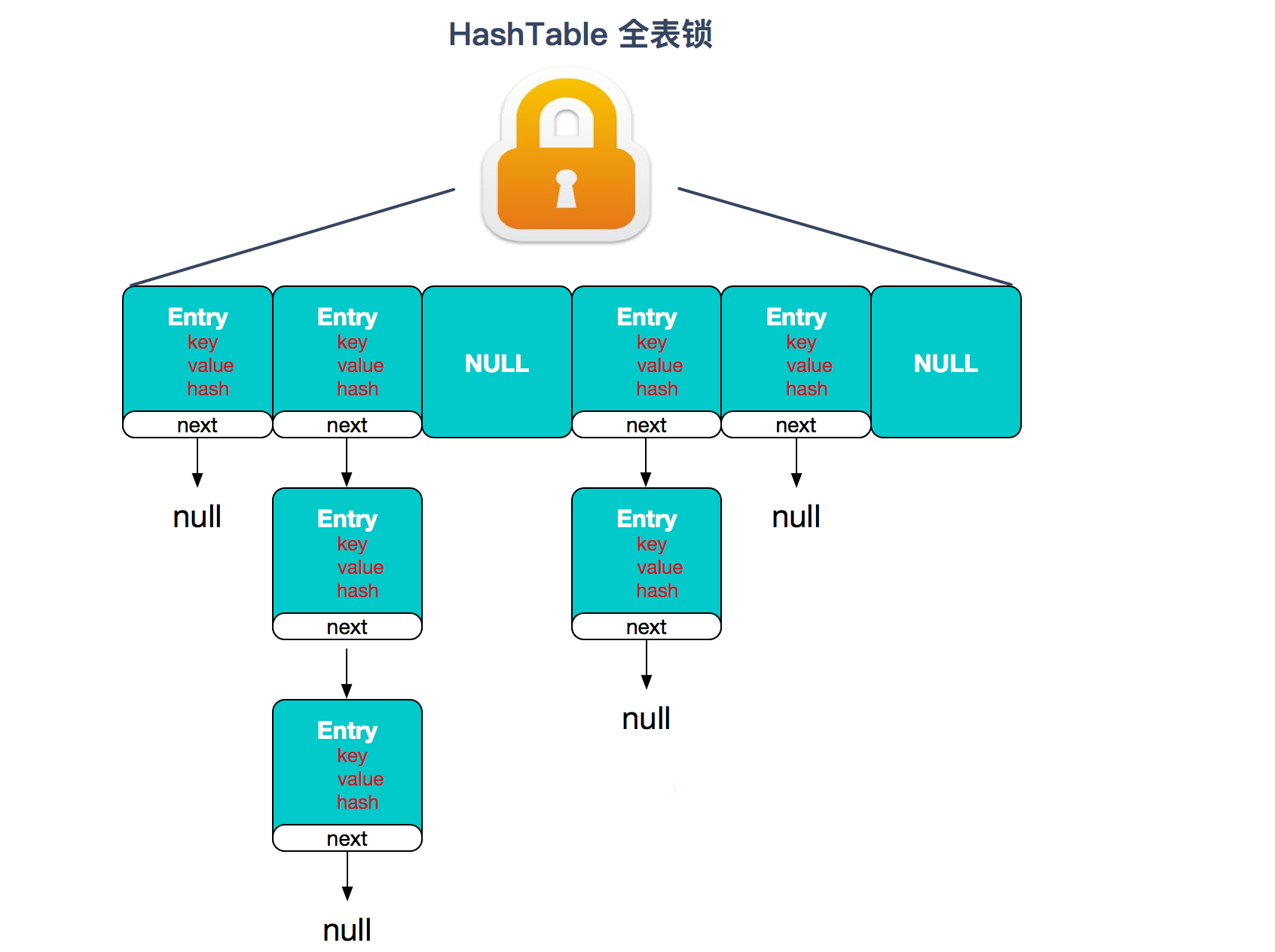
因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
对于Hashtable而言,synchronized是针对整张Hash表的,即每次锁住整张表让线程独占。相当于所有线程进行读写时都去竞争一把锁,导致效率非常低下。
3 ConcurrentHashMap的锁分段技术
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程都必须竞争同一把锁。
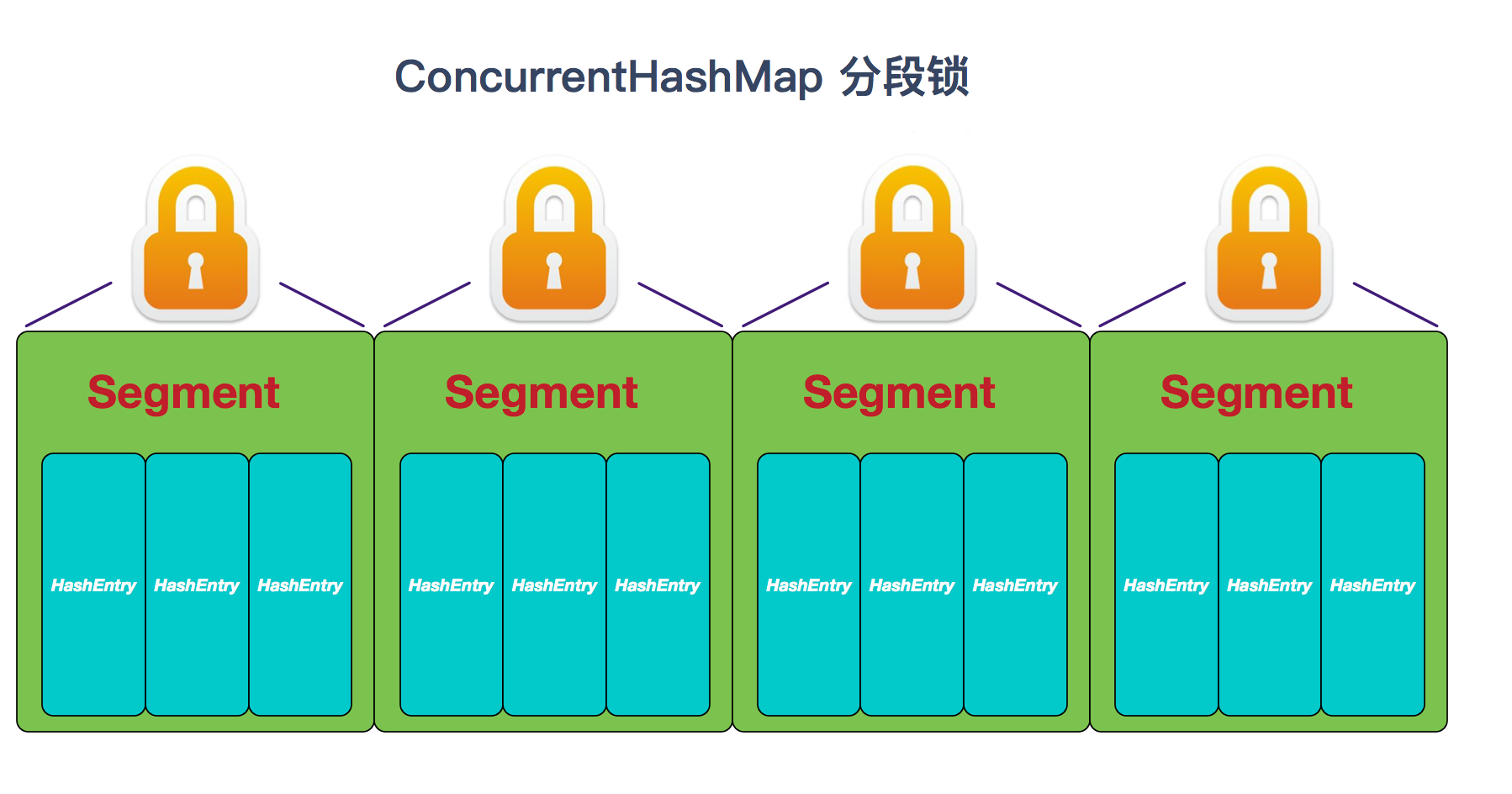
那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。
即首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。 另外,ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,不用对整个ConcurrentHashMap加锁。
ConcurrentHashMap的内部结构
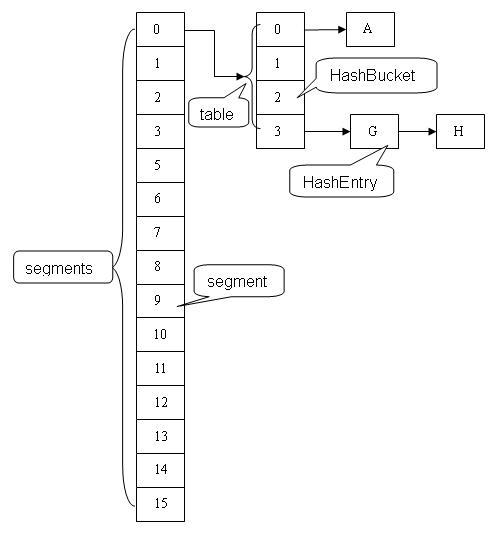
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。
Segment继承了ReentrantLock,所以它就是一种可重入锁(Reentrant Lock)。在ConcurrentHashMap,一个Segment就是一个子哈希表,Segment里维护了一个HashEntry数组,并发环境下,对于不同Segment的数据进行操作是不用考虑锁竞争的。
一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
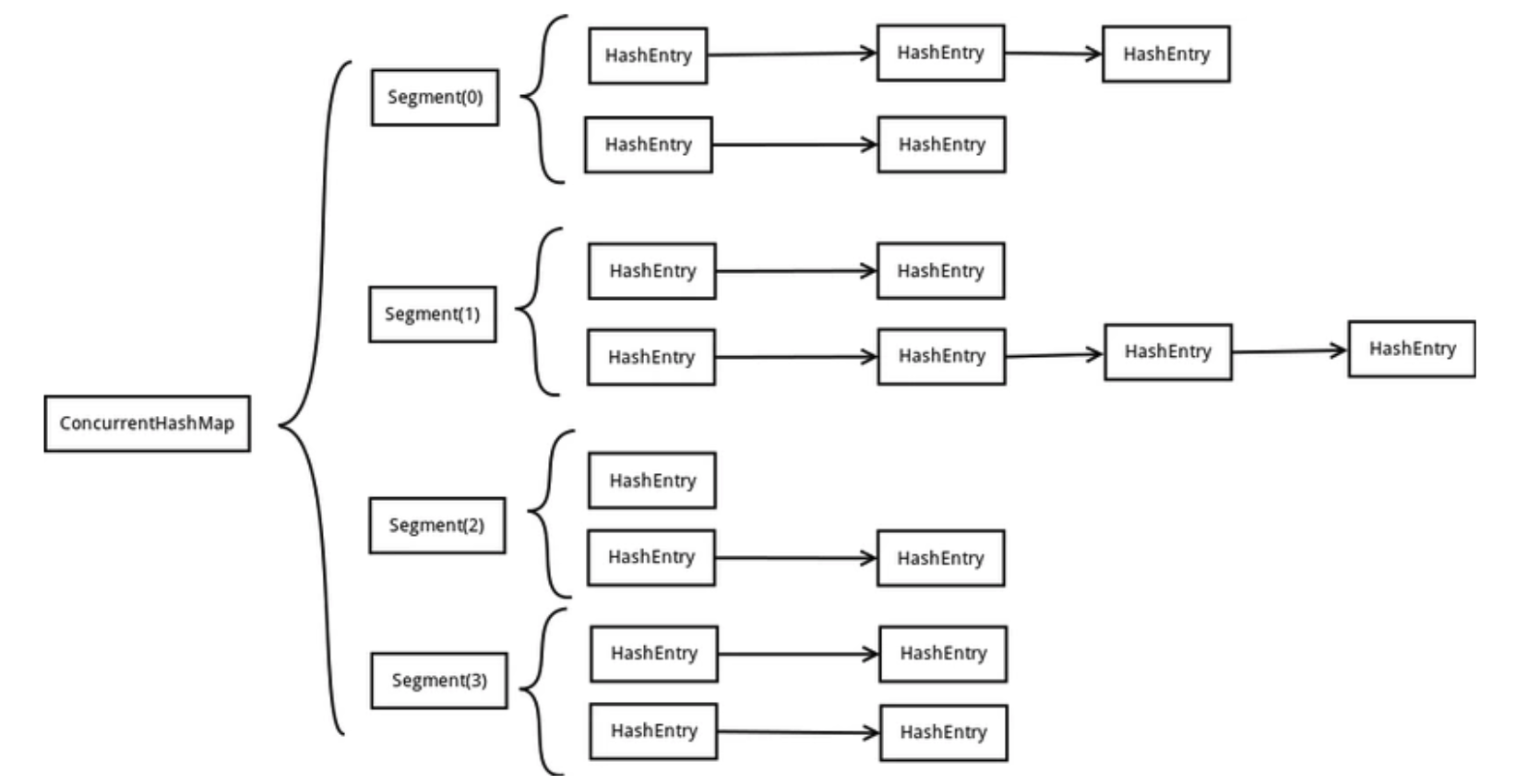
从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部。
因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,
这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上),所以,通过这一种结构,ConcurrentHashMap的并发能力可以大大的提高。
JDK 1.8中的实现改进
JDK 1.7中ConcurrentHashMap最主要采用segment,多线程竞争会先锁住segment,在其put操作中会先定位segment位置,再定位segment中具体桶位置。
在 JDK 1.8中,抛弃了Segment分段锁机制,利用Node数组+CAS+Synchronized来保证并发更新的安全,底层采用数组+链表+红黑树的存储结构。
Reference
- 站在巨人肩膀上看源码-ConcurrentHashMap - https://segmentfault.com/a/1190000015221462
- ConcurrentHashMap实现原理及源码分析 - https://www.cnblogs.com/chengxiao/p/6842045.htmls
- 探索 ConcurrentHashMap 高并发性的实现机制 - https://www.ibm.com/developerworks/cn/java/java-lo-concurrenthashmap/index.html