LinkedHashMap
HashMap是无序的,也就是说,迭代HashMap所得到的元素顺序并不是它们最初放置到HashMap的顺序。HashMap的这一缺点往往会造成诸多不便,因为在有些场景中,我们的确需要用到一个可以保持插入顺序的Map。
庆幸的是,JDK为我们解决了这个问题,它为HashMap提供了一个子类 —— LinkedHashMap。
由于LinkedHashMap是HashMap的子类,所以LinkedHashMap自然会拥有HashMap的所有特性。比如,LinkedHashMap的元素存取过程基本与HashMap基本类似,只是在细节实现上稍有不同。当然,这是由LinkedHashMap本身的特性所决定的,因为它额外维护了一个双向链表用于保持迭代顺序。
虽然LinkedHashMap增加了时间和空间上的开销,但是它通过维护一个额外的双向链表保证了迭代顺序。
特别地,该迭代顺序可以是插入顺序,也可以是访问顺序。因此,根据链表中元素的顺序可以将LinkedHashMap分为:保持插入顺序的LinkedHashMap 和 保持访问顺序的LinkedHashMap,其中LinkedHashMap的默认实现是按插入顺序排序的。
总结来说,HashMap和双向链表合二为一即是LinkedHashMap。所谓LinkedHashMap,其落脚点在HashMap,因此更准确地说,它是一个将所有Entry节点链入一个双向链表的HashMap。
实验
LinkedHashMap有一个参数 accessOrder 决定是否在插入顺序的基础上,再根据访问顺序排序:
public static void main(String[] args) {
Map<String, String> map = new LinkedHashMap<String, String>();
map.put("apple", "苹果");
map.put("watermelon", "西瓜");
map.put("banana", "香蕉");
map.put("peach", "桃子");
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
System.out.println(entry.getKey() + "=" + entry.getValue());
}
System.out.println();
///////////////////////////////////////////////////
map = new LinkedHashMap<String, String>(16,0.75f,true);
map.put("apple", "苹果");
map.put("watermelon", "西瓜");
map.put("banana", "香蕉");
map.put("peach", "桃子");
map.get("banana");
map.get("apple");
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
System.out.println(entry.getKey() + "=" + entry.getValue());
}
}
输出:
apple=苹果
watermelon=西瓜
banana=香蕉
peach=桃子
watermelon=西瓜
peach=桃子
banana=香蕉
apple=苹果
底层实现
在LinkedHashMapMap中,所有put进来的Entry都保存在一个哈希表中,但由于它又额外定义了一个以head为头结点的双向链表,因此对于每次put进来Entry,除了将其保存到哈希表中对应的位置上之外,还会将其插入到双向链表的尾部。
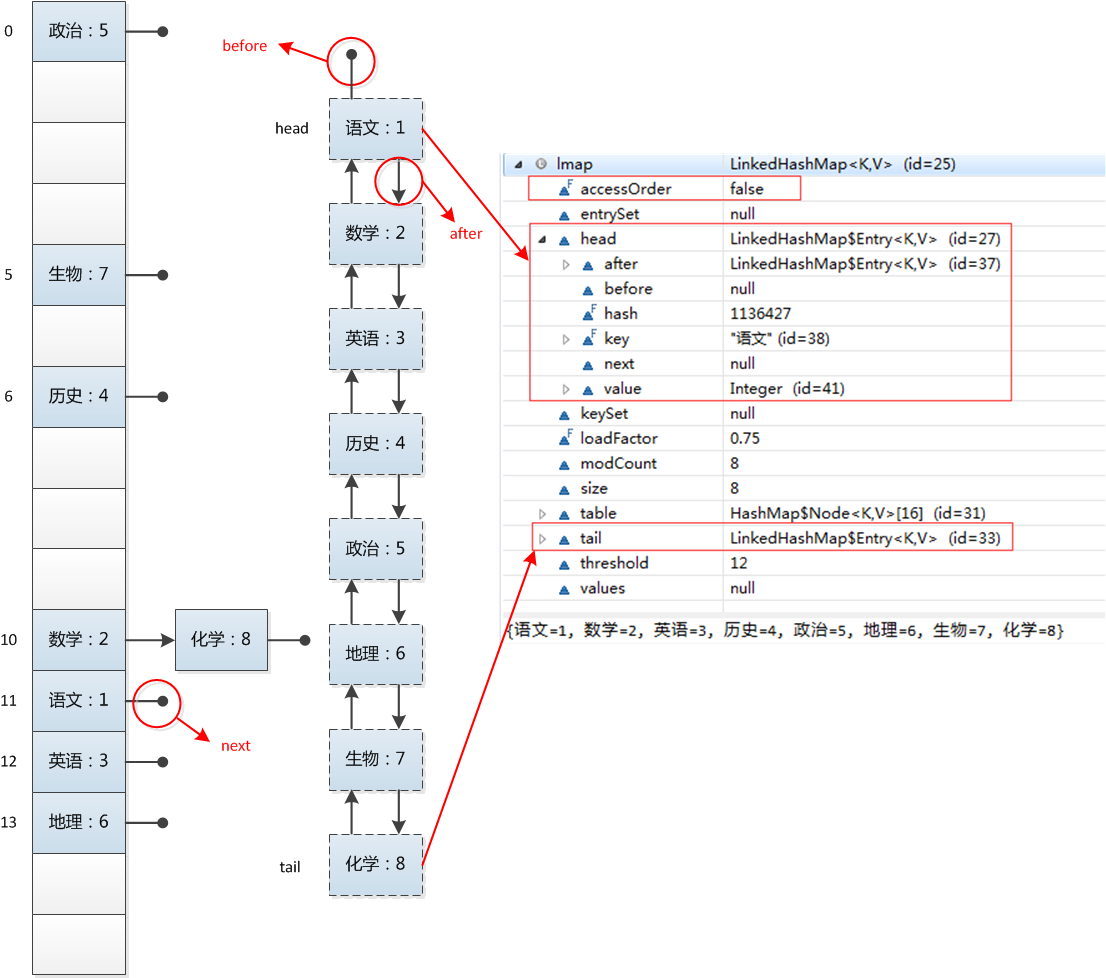
三个重点实现的函数
在HashMap中提到了下面的定义:
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
LinkedHashMap继承于HashMap,因此也重新实现了这3个函数,顾名思义这三个函数的作用分别是:节点访问后、节点插入后、节点移除后做一些事情。
afterNodeAccess函数
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// 如果定义了accessOrder,那么就保证最近访问节点放到最后
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
就是说在进行put之后就算是对节点的访问了,那么这个时候就会更新链表,把最近访问的放到最后,保证链表。
afterNodeInsertion函数
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// 如果定义了移除规则,则执行相应的溢出
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
如果用户定义了removeEldestEntry的规则,那么便可以执行相应的移除操作。
afterNodeRemoval函数
void afterNodeRemoval(Node<K,V> e) { // unlink
// 从链表中移除节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
这个函数是在移除节点后调用的,就是将节点从双向链表中删除。
我们从上面3个函数看出来,基本上都是为了保证双向链表中的节点次序或者双向链表容量所做的一些额外的事情,目的就是保持双向链表中节点的顺序要从eldest到youngest。
put和get函数
put函数在LinkedHashMap中未重新实现,只是实现了afterNodeAccess和afterNodeInsertion两个回调函数。get函数则重新实现并加入了afterNodeAccess来保证访问顺序,下面是get函数的具体实现:
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
Reference
- Map 综述(二):彻头彻尾理解 LinkedHashMap - https://blog.csdn.net/justloveyou_/article/details/71713781
- Java集合系列之LinkedHashMap - https://juejin.im/post/5a4b433b6fb9a0451705916f
- Java LinkedHashMap工作原理及实现 - https://yikun.github.io/2015/04/02/Java-LinkedHashMap工作原理及实现/