Java 对象头(Java Object Header)
在 HotSpot 虚拟机中,一个对象在内存中存储的布局可以分为三块区域:对象头(Object Header)、实例数据(Instance Data)和对齐填充(Padding)。
当我们在 Java 代码中,使用 new 关键字创建一个对象的时候,JVM 会为这个对象创建一个对应的 instanceOopDesc 对象,这个 instanceOopDesc 对象中包含了对象头(Header)以及实例数据。
instanceOopDesc 对象的结构
class oopDesc {
friend class VMStructs;
friend class JVMCIVMStructs;
private:
// 对象头
volatile markOop _mark;
// 元数据
union _metadata {
// 对应的Klass对象
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
对象头(Object Header)结构
而对象头(Object Header)包括两部分数据:
- Mark Word(标记字段)
- 用于存储对象自身的运行时数据,如哈希码(HashCode)、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等等。它是实现轻量级锁和偏向锁的关键。
- 对应于
instanceOopDesc对象中的 _mark 字段。
- Klass Pointer(类型指针)
- 是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
- 对应于
instanceOopDesc对象中的 _metadata 字段,而 _metadata 字段包含一个普通 _klass 和一个压缩后的 _compressed_klass。
如果这个对象是数组对象的话,还会有一个额外的部分用于存储数组的长度。
Java 对象头长度
在 32 位虚拟机中,Java 对象头一般占有两个机器码( 1 个机器码等于 4 字节,也就是 32 bit),
|--------------------------------------------------------------|
| Object Header (64 bits) |
|------------------------------------|-------------------------|
| Mark Word (32 bits) | Klass Word (32 bits) |
|------------------------------------|-------------------------|
但是如果对象是数组类型,则需要三个机器码(即 96 bit),因为 JVM 可以通过 Java 对象的元数据信息确定 Java 对象的大小,但是无法从数组的元数据来确认数组的大小,所以用一块来记录数组长度。
|---------------------------------------------------------------------------------|
| Object Header (96 bits) |
|--------------------------------|-----------------------|------------------------|
| Mark Word(32bits) | Klass Word(32bits) | array length(32bits) |
|--------------------------------|-----------------------|------------------------|
Mark Word(标记字段)
对 Mark Word(标记字段)的设计方式上,非常像网络协议报文头:将Mark Word(标记字段)划分为多个比特位区间,并在不同的对象状态下赋予比特位不同的含义。
Mark Word(标记字段)在 32 位 JVM 中的长度是32bit,在 64 位 JVM 中长度是64bit。
Mark Word(标记字段)用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等等。
对象头信息是与对象自身定义的数据无关的额外存储成本,但是考虑到虚拟机的空间效率,Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据,它会根据对象的状态复用自己的存储空间,也就是说,Mark Word会随着程序的运行发生变化,变化状态如下(32位虚拟机):
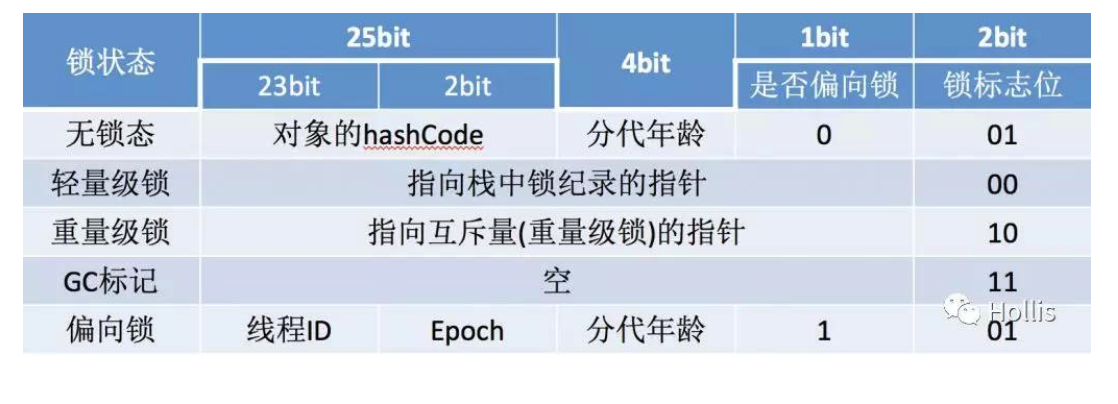
锁的状态
锁的状态总共有四种:无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁(但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级)。JDK 1.6中默认是开启偏向锁和轻量级锁的,我们也可以通过-XX:-UseBiasedLocking来禁用偏向锁。
JVM一般是这样使用锁和 Mark Word 的:
1,当一个对象没有被当成锁时,这就是一个普通的对象,Mark Word记录对象的HashCode,锁标志位是01,是否偏向锁那一位是0。
2,当对象被当做同步锁,并有一个线程A抢到了锁时,锁标志位还是01,但是否偏向锁那一位改成1,前23bit记录抢到锁的线程id,表示进入偏向锁状态。
3,当线程A再次试图来获得锁时,JVM发现同步锁对象的标志位是01,是否偏向锁是1,也就是偏向状态,Mark Word中记录的线程id就是线程A自己的id,表示线程A已经获得了这个偏向锁,可以执行同步锁的代码。
4,当线程B试图获得这个锁时,JVM发现同步锁处于偏向状态,但是Mark Word中的线程id记录的不是B,那么线程B会先用CAS操作试图获得锁,这里的获得锁操作是有可能成功的,因为线程A一般不会自动释放偏向锁。如果抢锁成功,就把Mark Word里的线程id改为线程B的id,代表线程B获得了这个偏向锁,可以执行同步锁代码。如果抢锁失败,则继续执行步骤5。
5,偏向锁状态抢锁失败,代表当前锁有一定的竞争,偏向锁将升级为轻量级锁。JVM会在当前线程的线程栈中开辟一块单独的空间,里面保存指向对象锁Mark Word的指针,同时在对象锁Mark Word中保存指向这片空间的指针。上述两个保存操作都是CAS操作,如果保存成功,代表线程抢到了同步锁,就把Mark Word中的锁标志位改成00,可以执行同步锁代码。如果保存失败,表示抢锁失败,竞争太激烈,继续执行步骤6。
6,轻量级锁抢锁失败,JVM会使用自旋锁,自旋锁不是一个锁状态,只是代表不断的重试,尝试抢锁。从JDK1.7开始,自旋锁默认启用,自旋次数由JVM决定。如果抢锁成功则执行同步锁代码,如果失败则继续执行步骤7。
7,自旋锁重试之后如果抢锁依然失败,同步锁会升级至重量级锁,锁标志位改为10。在这个状态下,未抢到锁的线程都会被阻塞。
Klass Pointer(类型指针)
对象头(Header)的另外一部分是类型指针,即是对象指向它的类的元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。并不是所有的虚拟机实现都必须在对象数据上保留类型指针,换句话说查找对象的元数据信息并不一定要经过对象本身。另外,如果对象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是从数组的元数据中无法确定数组的大小。
Reference
- 深入理解多线程(三)—— Java的对象头 - https://juejin.im/post/5b7b712951882542e32a956a
- 【JVM源码探秘】Java对象模型之对象头 - https://hunterzhao.io/post/2018/02/25/hotspot-explore-java-object-header/
- 【深入理解多线程】Java的对象头(三) - https://blog.csdn.net/w372426096/article/details/80079408
- 【Java对象解析】不得不了解的对象头 - https://blog.csdn.net/zhoufanyang_china/article/details/54601311
- Java的对象头和对象组成详解 - https://blog.csdn.net/lkforce/article/details/81128115
- Java对象头详解 - https://www.jianshu.com/p/3d38cba67f8b