final 的简介
final 可以修饰变量,方法和类,用于表示所修饰的内容一旦赋值之后就不会再被改变,比如 String 类就是一个 final 类型的类。
final 的具体使用场景
final 能够修饰变量,方法和类,也就是 final 使用范围基本涵盖了 Java 每个地方,下面就分别以锁修饰的位置:变量,方法和类分别来说一说。
final 修饰【变量】
在 Java 中变量,可以分为成员变量以及方法局部变量。因此也是按照这种方式依次来说,以避免漏掉任何一个死角。
final 修饰【成员变量】
对于一个 final 变量:
- 如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;
- 如果是引用类型的变量,则在对其初始化之后,便不能再让其指向另一个对象。
通常每个类中的成员变量可以分为类变量(static 修饰的变量)以及实例变量。针对这两种类型的变量赋初值的时机是不同的:
- 类变量可以在声明变量的时候直接赋初值,或者在静态代码块中给类变量赋初值。
- 而实例变量可以在声明变量的时候给实例变量赋初值,或者在非静态初始化块中赋初值,或者也可以在构造器中赋初值。
类变量有两个时机赋初值,而实例变量则可以有三个时机赋初值。
当 final 变量未初始化时,系统不会进行隐式初始化,会出现报错。这样说起来还是比较抽象,下面用具体的代码来演示。
代码涵盖了 final 修饰变量所有的可能情况。

public class Test {
// final 实例变量可以在声明时被赋值
private final int a = 6;
private final int b;
private final int c;
private final int d;
private final static int e;
// final 类变量可以在声明时就被赋值
private final static int f = 1;
{
// final 实例变量可以在初始化块中赋值
b = 1;
}
static {
// final 类变量可以在静态初始化块中被赋值
e = 1;
// final 实例变量不能在静态初始化块中被赋值
b = 2;
}
public Test() {
// final 实例变量可以在构造函数中被赋值
c = 1;
// 在任何位置都不能对已经赋值过的final变量再次赋值
b = 3;
}
}
总结
- 对于 final 修饰的类变量:必须要在声明该类变量时,或静态初始化块中,指定初始值,而且只能在这两个地方中其中一个地方进行指定。
- 对于 final 修饰的实例变量:必要要在声明该实例变量,或非静态初始化块,或构造器中,指定初始值,而且只能在这三个地方任何一个地方进行指定。
- 不能在实例方法中为 final 变量赋值。
- 不能对已经赋值过的 final 变量再次赋值。
final 修饰【局部变量】
final 修饰的局部变量必须由程序员进行显式的初始化。
如果 final 变量未进行初始化,必须进行赋值,而且当且仅有一次赋值机会,这意味着,如果 final 局部变量已经进行了初始化,则就不能再次进行赋值(修改),否则会提示编译错误,
下面用具体的代码演示 final 局部变量的情况:

public void method1() {
final int a;
a = 1;
// 由于上面已经进行了一个赋值,因此这里的赋值操作会提示报错!
a = 2;
}
final 修饰【方法参数】
当一个方法的形参被 final 修饰的时候,这个参数在该方法内不可以被修改。
public class FinalParam {
public void test(final int a ){
//a = 10; 值不可以被修改
}
public void test(final Person p){
//p = new Person("zhangbingxiao"); 引用本身不可以被修改
p.setName("zhangbingxiao"); //引用所指向的对象可以被修改
}
}
对于引用数据类型的修改规则同 final 属性一样。
final 修饰参数在内部类中是非常有用的,在匿名内部类中,为了保持参数的一致性,若所在的方法的形参需要被内部类里面使用时,该形参必须为 final。
修饰不同的数据类型
final 修饰的是基本数据类型和引用类型有区别吗?
通过上面的例子我们已经看出来,如果 final 修饰的是一个基本数据类型的数据,一旦赋值后就不能再次更改。
那么,如果 final 是引用数据类型了?这个引用对象中的字段能够改变吗?我们同样来看一段代码。
public class Test {
public static void main(String[] args) {
//在声明final实例成员变量时进行赋值
final Person person = new Person(24, 170);
//对final修饰的引用数据类型person中的字段进行更改
person.age = 22;
// 输出了 Person{age=22, height=170}
System.out.println(person.toString());
}
}
class Person {
public int age;
public int height;
public Person(int age, int height) {
this.age = age;
this.height = height;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", height=" + height +
'}';
}
}
通过这个实验,我们就可以看出来:
- 当 final 修饰基本数据类型变量时,不能对基本数据类型变量重新赋值,因此这个基本数据类型变量的值不能被改变。
- 而对于引用类型变量而言,它仅仅保存的是一个引用,final 只保证这个引用类型变量所引用的地址不会发生改变,即一直引用这个对象,但这个对象中的属性是可以(多次)修改的。
宏变量
由于被 final 修饰后带来的不可更改性,被 final 修饰的变量,就可能成为一个 “宏变量”,即是一个常量。
所谓 "可能",是指,如果在编译期间能知道它的确切值,则编译器会把它当做编译期常量使用。也就是说在用到该 final 变量的地方,相当于直接访问的这个常量,不需要在运行时确定。这种和 C 语言中的宏替换有点像。
例子
我们通过一个例子来看看 final 变量和普通变量到底有何区别。
public class Test {
public static void main(String[] args) {
String a = "hello2";
final String b = "hello";
String d = "hello";
String c = b + 2;
String e = d + 2;
System.out.println((a == c));
System.out.println((a == e));
}
}
结果
true
false
分析
这里面就是 final 变量和普通变量的区别了,当 final 变量是基本数据类型以及 String 类型时,如果在编译期间能知道它的确切值,则编译器会把它当做编译期常量使用。
也就是说在用到该 final 变量的地方,相当于直接访问的这个常量,不需要直到运行时才确定。这种和 C 语言中的宏替换有点像。
在上面的一段代码中,由于变量 b 被 final 修饰,因此会被当做编译器常量,所以在使用到 b 的地方会直接将变量 b 替换为它的 值。而对于变量 d 的访问却需要在运行时(runtime)通过链接来进行。
不过要注意,只有在编译期间能确切知道 final 变量值的情况下,编译器才会进行这样的优化,比如下面的这段代码就不会进行优化:
public class Test {
public static void main(String[] args) {
String a = "hello2";
final String b = getHello();
String c = b + 2;
System.out.println((a == c));
}
public static String getHello() {
return "hello";
}
}
这段代码的输出结果为 false。
final 变量命名规范
按照 Java 代码惯例,final 变量就是常量,而且通常常量名要大写:
private final int COUNT = 10;
Final 修饰【方法】
不能重写(overwrite) final 方法
当父类的方法被 final 修饰的时候,子类不能重写(overwrite)父类的该 final 方法。
使用 final 修饰方法的目的在于把方法的实现锁定,以防止任何继承该类的类修改这个方法的实现。
比如在 Object 中,getClass () 方法就是 final 的,我们就不能在其任何子类中重写该方法,但是 hashCode () 方法就不是被 final 所修饰的,我们就可以重写 hashCode () 方法。
注:类的 private 方法会隐式地被指定为 final 方法。
例子
我们还是来写一个例子来加深一下理解:
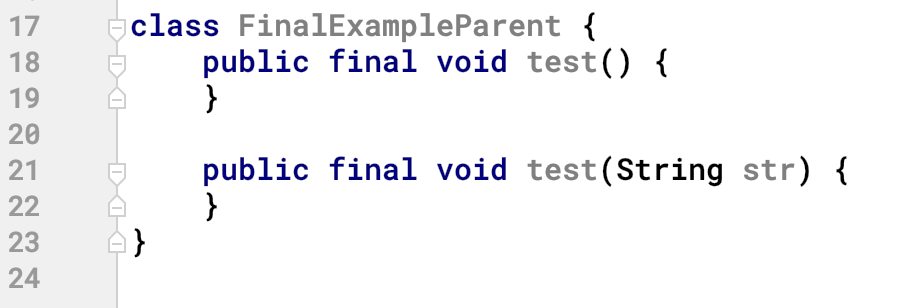
先定义一个父类,里面有一个 final 修饰的方法 test ()。
public class FinalExampleParent {
public final void test() {
}
}
然后 FinalExample 继承该父类,当重写 test () 方法时报错,如下图:

通过这个现象我们就可以看出来被 final 修饰的方法不能够被子类所重写(overwrite)。
可以重载(overload) final 方法
上面的代码没有任何编译错误。
因此,可以得出结论:被 final 修饰的方法是可以重载(overload)的。
Final 修饰【类】
当一个类被 final 修饰时,该类不能被继承。
子类继承往往可以重写父类的方法和改变父类属性,会带来一定的安全隐患。因此,当一个类不希望被继承时,就可以使用 final 修饰。
例子
当一个类继承一个被 final 修饰的类时,就会报错,如下图:

不变类
不变类的意思是创建该类的实例后,该实例变量是不可改变的。
不可变类有很多好处,譬如它们的对象是只读的,可以在多线程环境下安全的共享,不用额外的同步开销等等。
声明一个不可变类,需要满足以下条件:
- 使用 private 和 final 修饰符来修饰该类的所有成员变量
- 提供带参的构造器用于初始化类的成员变量;
- 仅为该类的成员变量提供 getter 方法,不提供 setter 方法,因为普通方法无法修改 fina 修饰的成员变量;
- 在 getter 方法中,不要直接返回对象本身,而是克隆对象,并返回对象的拷贝;
- 通过构造器初始化所有成员时,进行深拷贝(deep copy);
- 如果有必要就重写 Object 类 的 hashCode () 和 equals () 方法,应该保证用 equals () 判断相同的两个对象其 Hashcode 值也是相等的。
例子
public final class FinalClassExample {
private final int id;
private final String name;
private final HashMap testMap;
public int getId() {
return id;
}
public String getName() {
return name;
}
/**
* 可变对象的访问方法
*/
public HashMap getTestMap() {
//return testMap;
return (HashMap) testMap.clone();
}
/**
* 实现深拷贝(deep copy)的构造器
*/
public FinalClassExample(int i, String n, HashMap hm) {
System.out.println("Performing Deep Copy for Object initialization");
this.id = i;
this.name = n;
HashMap tempMap = new HashMap();
String key;
Iterator it = hm.keySet().iterator();
while (it.hasNext()) {
key = it.next();
tempMap.put(key, hm.get(key));
}
this.testMap = tempMap;
}
/**
* 实现浅拷贝(shallow copy)的构造器
*/
/**
public FinalClassExample(int i, String n, HashMap hm){
System.out.println("Performing Shallow Copy for Object initialization");
this.id=i;
this.name=n;
this.testMap=hm;
}
*/
/**
* 测试浅拷贝的结果
* 为了创建不可变类,要使用深拷贝
*
* @param args
*/
public static void main(String[] args) {
HashMap h1 = new HashMap();
h1.put("1", "first");
h1.put("2", "second");
String s = "original";
int i = 10;
FinalClassExample ce = new FinalClassExample(i, s, h1);
//Lets see whether its copy by field or reference
System.out.println(s == ce.getName());
System.out.println(h1 == ce.getTestMap());
//print the ce values
System.out.println("ce id:" + ce.getId());
System.out.println("ce name:" + ce.getName());
System.out.println("ce testMap:" + ce.getTestMap());
//change the local variable values
i = 20;
s = "modified";
h1.put("3", "third");
//print the values again
System.out.println("ce id after local variable change:" + ce.getId());
System.out.println("ce name after local variable change:" + ce.getName());
System.out.println("ce testMap after local variable change:" + ce.getTestMap());
HashMap hmTest = ce.getTestMap();
hmTest.put("4", "new");
System.out.println("ce testMap after changing variable from accessor methods:" + ce.getTestMap());
}
}
输出
Performing Deep Copy for Object initialization
true
false
ce id:10
ce name:original
ce testMap:{2=second, 1=first}
ce id after local variable change:10
ce name after local variable change:original
ce testMap after local variable change:{2=second, 1=first}
ce testMap after changing variable from accessor methods:{2=second, 1=first}
现在我们注释掉深拷贝的构造器,取消对浅拷贝构造器的注释。也对 getTestMap () 方法中的返回语句取消注释,返回实际的对象引用。然后再一次执行代码。
Performing Shallow Copy for Object initialization
true
true
ce id:10
ce name:original
ce testMap:{2=second, 1=first}
ce id after local variable change:10
ce name after local variable change:original
ce testMap after local variable change:{3=third, 2=second, 1=first}
ce testMap after changing variable from accessor methods:{3=third, 2=second, 1=first, 4=new}
从输出可以看出,HashMap 的值被更改了,因为构造器实现的是浅拷贝,而且在 getter 方法中返回的是原本对象的引用。
JDK 中提供的八个包装类和 String 类都是不可变类,我们来看看 String 的实现。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
/**
* Class String is special cased within the Serialization Stream Protocol.
*
* A String instance is written into an ObjectOutputStream according to
* <a href="{@docRoot}/../platform/serialization/spec/output.html">
* Object Serialization Specification, Section 6.2, "Stream Elements"</a>
*/
private static final ObjectStreamField[] serialPersistentFields =
new ObjectStreamField[0];
...
}
可以看出 String 的 value 就是 final 修饰的,上述其他几条性质也是吻合的。
多线程中 final 变量的可见性(visibility)问题
背景
在 Java 内存模型中,我们知道 Java 内存模型为了能让处理器和编译器底层发挥他们的最大优势,对底层的约束就很少。
也就是说针对底层来说,Java 内存模型就是一弱内存数据模型。同时,处理器和编译为了性能优化会对指令序列有编译器和处理器重排序。
那么,在多线程情况下,final 会进行怎样的重排序(reordering)?会导致线程安全的问题吗?
下面,就来看看 final 域的可见性(visibility)问题。可见性(visibility)问题是指,当一个线程修改了一个变量的值后,另一个线程是否能够感知到这个修改。
final 域为基本类型
例子
先看一段示例性的代码:
public class FinalDemo {
private int a; //普通域
private final int b; //final域
private static volatile FinalDemo finalDemo;
public FinalDemo() {
a = 1; // 1. 写普通域
b = 2; // 2. 写final域
}
public static void writer() {
finalDemo = new FinalDemo();
}
public static void reader() {
if (finalDemo != null){
FinalDemo demo = finalDemo; // 3.读对象引用
int a = demo.a; //4.读普通域
int b = demo.b; //5.读final域
}
}
}
假设线程 A 已经执行完 writer () 方法后,线程 B 才开始执行 reader () 方法。
注意,这里我们假设 "线程 A 先执行 writer () 方法,在线程 A 执行完之后,线程 B 开始执行 reader () 方法",而(在实践中)如果只是将这两个方法分别传入两个 Thread 对象,这两个线程的先后执行顺序是完全未知的。
因此,在进行以下讨论时,我们暂且认为假设的执行顺序已经得到了保障。
规则
禁止将 final 域的写操作,重排序到构造函数之外。这个规则的实现主要包含了两个方面:
- JMM 禁止编译器把 final 域的写操作重排序到构造函数之外;
- 编译器会在 final 域的写操作之后,构造函数 return 之前,插入一个 storestore 屏障。这个屏障可以禁止处理器把 final 域的写操作,重排序到构造函数之外。
例子分析
由于 a,b 之间没有数据依赖性,普通域(普通变量)a 可能会被重排序到构造函数之外,线程 B 就有可能读到普通变量 a 初始化之前的值(零值),这样就可能出现错误。而对于 final 域变量 b,根据重排序规则,会禁止 final 修饰的变量 b 重排序到构造函数之外(意味着变量 b 能够在 FinalDemo 对象实例的构造函数执行完成前被赋值),因而线程 B 就能够读到 final 变量初始化后的值。
因此,final 域写操作的重排序规则可以确保:在对象引用为任意线程可见之前,对象的 final 域已经被正确初始化过了,而普通域就不具有这个保障。
final 域为引用类型
针对类型为引用数据类型的 final 域的写操作,针对编译器和处理器重排序增加了这样的约束:在构造函数内,对一个 final 修饰的成员域的写入,与随后在构造函数之外把这个被构造的对象的引用赋给一个引用变量,这两个操作是不能被重排序的。
注意这里的约束是被 “增加” 的,也就说,前面对 final 基本数据类型的重排序规则在这里还是适用。这句话是比较拗口的,下面结合实例来看。
例子
public class FinalReferenceDemo {
final int[] arrays;
public FinalReferenceDemo() {
arrays = new int[1]; //语句1
arrays[0] = 1; //语句2
}
}
public class Demo{
private volatile FinalReferenceDemo finalReferenceDemo;
public void writerOne() {
finalReferenceDemo = new FinalReferenceDemo(); //语句3
}
public void writerTwo() {
this.finalReferenceDemo.arrays[0] = 2; //语句4
}
public void reader() {
if (this.finalReferenceDemo != null) { //语句5
int temp = finalReferenceDemo.arrays[0]; //语句6
}
}
}
假设线程 A 先执行 wirterOne () 方法;线程 A 执行完后,线程 B 执行 writerTwo () 方法,然后线程 C 执行 reader () 方法。
注意,这里我们的假设 "线程 A 先执行 wirterOne () 方法;线程 A 执行完后,线程 B 执行 writerTwo () 方法,然后线程 C 执行 reader () 方法" 是讨论这个问题的前提。
而事实上,在上面的代码中,并没有任何机制保障这个假设。因而,在进行以下讨论时,我们暂且认为假设的执行顺序已经得到了保障。
分析
由于,对于 final 域的写操作,会被禁止重排序到这个域对应类的构造方法之后,因此,线程 A 在执行完语句 3 后(语句 3 中包括了语句 1 和语句 2),语句 1 和语句 2 的执行对所有线程均可见。
但是,对于线程 B 中执行的语句 4,JMM 不保证其可见性。也就是说,线程 C 的 temp 变量可能为 2,也可能为 1。
final 的实现原理
上面我们提到过,对于对 final 域的写操作,重排序规则会要求编译器在进行对 final 域的写操作之后,构造函数返回前插入一个 Store 屏障,以保证对 final 域的写操作(对其他线程)的可见性。
类似地,对 final 域的读操作,重排序规则也会要求编译器在对 final 域的读操作前插入一个 Load 屏障。
为什么 final 引用不能从构造函数中 “溢出”
这里还有一个比较有意思的问题:上面对 final 域写重排序规则,可以确保我们在使用一个对象引用的时候,该对象的 final 域已经在构造函数中被初始化过了。但是这里其实是有一个前提条件的,也就是:在构造函数,不能让这个被构造的对象被其他线程可见,也就是说该对象引用不能在构造函数中 “逸出”。以下面的例子来说:
public class FinalReferenceEscapeDemo {
private final int a;
private FinalReferenceEscapeDemo referenceDemo;
public FinalReferenceEscapeDemo() {
a = 1; //语句1
referenceDemo = this; //语句2
}
public void writer() {
this.referenceDemo = new FinalReferenceEscapeDemo();
}
public void reader() {
if (this.referenceDemo != null) { //语句3
int temp = this.referenceDemo.a; //语句4
}
}
}
假设一个线程 A 先执行 writer () 方法,在线程 A 执行完成后,线程 B 开始执行 reader () 方法。
因为构造函数中操作语句 1 和语句 2 之间没有数据依赖性,因此,语句 1 和语句 2 可以被重排序。
如果先执行了语句 2(而还未执行语句 1),这个时候引用变量 referenceDemo 不为 null,但是 a 的值仍为 0。
因此,在线程 B 中,语句 3 中的 if 条件能够被满足。但是获取到的 temp 变量却为 0。
总结,引用对象 “this” 逸出,该代码依然存在线程安全的问题。
Reference
- 《The Art of Java Concurrency Programming》
- 你以为你真的了解 final 吗? - https://juejin.im/post/5ae9b82c6fb9a07ac3634941
- 浅析 Java 中的 final 关键字 - https://www.cnblogs.com/dolphin0520/p/3736238.html
- 如何写一个不可变类? - http://www.importnew.com/7535.html
- 重新认识 java(七) - final 关键字 - https://juejin.im/entry/58affd238d6d810058554a5c