String 类
概览
String 被声明为 final,因此它不可被继承。
在 Java 8 中,String 内部使用 char 数组存储数据。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}Copy to clipboardErrorCopied
在 Java 9 之后,String 类的实现改用 byte 数组存储字符串,同时使用 coder 来标识使用了哪种编码。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final byte[] value;
/** The identifier of the encoding used to encode the bytes in {@code value}. */
private final byte coder;
}Copy to clipboardErrorCopied
value 数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
String 对象的两种创建方式
String str1 = "abcd";
String str2 = new String("abcd");
String str3 = new String("abcd");
System.out.println(str1 == str2); //false
System.out.println(str1 == str3); //false
System.out.println(str2 == str3); //false
这两种不同的创建 String 对象实例的方法是有差别的:
- 第一种方式是直接指向一个**字符串常量池(String Constant Pool)**中的"abcd"字符串对象的引用;
- 第二种方式是直接在堆(Heap)内存中创建一个新的对象,而这个对象的 value 指向了"abcd"字符串对象。
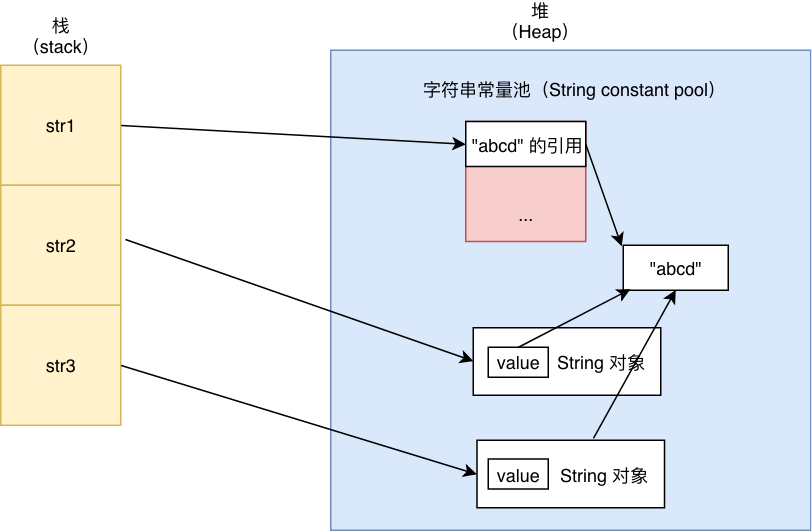
**记住:**只要使用了 new 关键字,便会在堆中创建新的对象。
String类不可变性
String是不可变的、final的。Java在运行时也保存了一个字符串常量池(String Constant Pool),这使得String成为了一个特别的类。
好处:
- 只有当字符串是不可变的,字符串常量池才有可能实现。字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字符串。但如果字符串是可变的,那么String的interning将不能实现(String的interning是指对不同的字符串仅仅只保存一个,即不会保存多个相同的字符串),因为这样的话,如果变量改变了它的值,那么其它指向这个值的变量的值也会一起改变。
- 如果字符串是可变的,那么会引起很严重的安全问题。譬如,数据库的用户名、密码都是以字符串的形式传入来获得数据库的连接,或者在socket编程中,主机名和端口都是以字符串的形式传入。
- 因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子,改变字符串指向的对象的值,造成安全漏洞。 因为字符串是不可变的,所以是多线程安全的,同一个字符串实例可以被多个线程共享。这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的。
- 类加载器要用到字符串,不可变性提供了安全性,以便正确的类被加载。譬如你想加载java.sql.Connection类,而这个值被改成了myhacked.Connection,那么会对你的数据库造成不可知的破坏。
- 因为字符串是不可变的,所以在它创建的时候hashcode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
字符串常量池(String Constant Pool)
设计思想
- 字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能。
- JVM 为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化:
- 为字符串开辟一个字符串常量池,类似于缓存区
- 创建字符串常量时,首先判断字符串常量池是否存在该字符串
- 存在该字符串,返回引用实例,不存在,实例化该字符串并放入池中
- 实现的基础
- 实现该优化的基础是因为字符串是不可变的(ummutable),可以不用担心数据冲突进行共享。
- 运行时实例创建的全局字符串池中有一个哈希表(StringTable),总是为池中每个唯一的字符串对象维护一个引用,这就意味着它们一直引用着字符串常量池中的对象,所以,在常量池中的这些字符串不会被垃圾收集器回收。
字符串池是一个典型的**享元模式(flyweight pattern)**实现。
例子 - 从字符串常量池中获取相应的字符串
String str1 = “hello”;
String str2 = “hello”;
System.out.printl("str1 == str2" : str1 == str2 ) //true
打印的 true 表明 str1 和 str2 均指向同一个堆空间中的对象。
字符串常量池在哪里
字符串常量池中存放的是引用还是对象呢?
字符串常量池存放的是对象引用,而不是对象。在 Java 中,对象都创建在堆内存中。
在 JDK6 以及以前的版本中,字符串的常量池是放在堆的 Perm 区(permanent space)的,Perm 区是一个类静态的区域,主要存储一些加载类的信息,常量池,方法片段等内容,默认大小只有4m,一旦常量池中大量使用 intern 是会直接产生 java.lang.OutOfMemoryError: PermGen space 错误的。
所以在 JDK7 的版本中,字符串常量池已经从 Perm 区移到正常的 Java Heap 区域了
在 HotSpot VM 里,通过一个 StringTable 类来实现**字符串常量池(string constant pool)**的。
StringTable 本质上是一个哈希表,里面存的是字符串字面量的引用(即我们用双引号括起来部分的引用,而不是字符串字面量实例本身),也就是说在堆中的某些字符串实例被这个 StringTable 引用之后,就等同被赋予了”驻留字符串”的身份。这个 StringTable 在每个 HotSpot VM 的实例只有一份,被所有的类共享。
例子 - 堆栈方法区存储字符串:
String str1 = “abc”;
String str2 = “abc”;
String str3 = new String(“abc”);
String str4 = new String(“abc”);
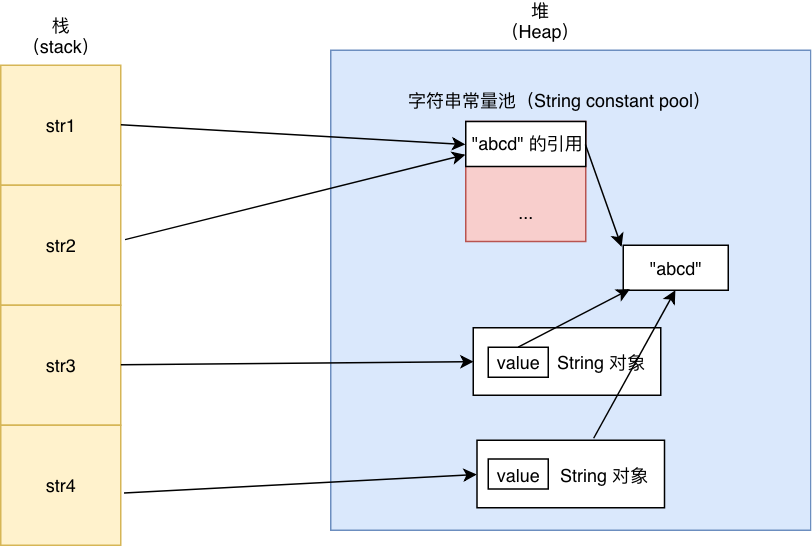
字符串常量池的使用方法
String 类型的常量池比较特殊,它的主要使用方法有两种:
- 直接使用双引号
- String.intern()
直接使用双引号
直接使用双引号声明出来的 String 对象会直接存储在字符串常量池中。
String.intern()
使用 String 提供的 intern 方法。
String.intern() 是一个 Native 方法。
它的作用是:在运行时,如果在字符串常量池中,包含了一个等于此 String 对象内容的字符串,则返回字符串常量池中该字符串的引用;如果没有,则在字符串常量池中创建一个与此 String 内容相同的字符串,并返回字符串常量池中创建的字符串的引用。
String s1 = new String("计算机");
String s2 = new String("计算机").intern();
String s3 = "计算机";
System.out.println(s2);//计算机
System.out.println(s1 == s2);//false,因为一个是堆内存中的String对象,一个是常量池中的String对象
System.out.println(s3 == s2);//true,因为两个都是常量池中的String对象
事实上,在 String s2 = new String("计算机").intern(); 中的 intern是多余的。
因为,就算不用intern,计算机作为一个字面量也会被加载到Class文件的常量池,进而加入到运行时常量池中,为啥还要多此一举呢?
Java 中几种常量池的区分
Class 文件常量池(constant pool)
我们都知道,Class 文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池表(constant pool table)。
常量池表(constant pool table)用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References)。
字面量(Literal)
在计算机科学中,字面量(literal)是用于表达源代码中一个固定值的表示法(notation)。几乎所有计算机编程语言都具有对基本值的字面量表示,诸如:整数、浮点数以及字符串;而有很多也对布尔类型和字符类型的值也支持字面量表示;还有一些甚至对枚举类型的元素以及像数组、记录和对象等复合类型的值也支持字面量表示法。
说简单点,字面量就是指由字母、数字等构成的字符串或者常量数值(声明为 final 的常量值)。
符号引用(Symbolic References)
**符号引用(Symbolic References)**是一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可(符号引用是相对于直接引用来说,直接引用一般是指向方法区的本地指针,相对偏移量或是一个能间接定位到目标的句柄)。一般包括下面三类常量:
- 类和接口的全限定名:例如对于String这个类,它的全限定名就是java/lang/String。
- 字段的名称和描述符:所谓字段就是类或者接口中声明的变量,包括类级别变量(static)和实例级的变量。
- 方法的名称和描述符:所谓描述符就相当于方法的参数类型+返回值类型。
通过javap命令可以查看一个指定Class文件的常量池内容:
对于程序:
class Meal {
public Meal() {
String a = "test1";
String b = "test2";
String c = "test3";
}
}
执行 javap 可以得到以下内容:
$ javap -v Meal
Warning: Binary file Meal contains com.concretepage.lang.Meal
Classfile /Users/weishi/Desktop/不常用/JavaTest/out/production/JavaTest/com/concretepage/lang/Meal.class
Last modified 10-Jul-2019; size 402 bytes
MD5 checksum 7cc2182c557c8f788f22799de50f8792
Compiled from "Test.java"
class com.concretepage.lang.Meal
minor version: 0
major version: 52
flags: ACC_SUPER
Constant pool:
#1 = Methodref #6.#20 // java/lang/Object."<init>":()V
#2 = String #21 // test1
#3 = String #22 // test2
#4 = String #23 // test3
#5 = Class #24 // com/concretepage/lang/Meal
#6 = Class #25 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 LocalVariableTable
#12 = Utf8 this
#13 = Utf8 Lcom/concretepage/lang/Meal;
#14 = Utf8 a
#15 = Utf8 Ljava/lang/String;
#16 = Utf8 b
#17 = Utf8 c
#18 = Utf8 SourceFile
#19 = Utf8 Test.java
#20 = NameAndType #7:#8 // "<init>":()V
#21 = Utf8 test1
#22 = Utf8 test2
#23 = Utf8 test3
#24 = Utf8 com/concretepage/lang/Meal
#25 = Utf8 java/lang/Object
...
SourceFile: "Test.java"
运行时常量池(Runtime constant pool)
运行时常量池(runtime constant pool),又称为动态常量池 ,是 JVM 在完成加载类之后,将 Class 文件中常量池载入到内存中,并保存在方法区中。
也就是说,运行时常量池中的常量,直接来源于或基于各个 Class 文件中的 Class 文件常量池。
运行时常量池与 Class 文件常量池区别
- JVM 对 Class文件中每一部分的格式都有严格的要求,每一个字节用于存储那种数据都必须符合规范上的要求才会被虚拟机认可、装载和执行;但运行时常量池没有这些限制,除了保存Class文件中描述的符号引用,还会把翻译出来的直接引用也存储在运行时常量区。
- 相较于Class文件常量池,运行时常量池更具动态性,在运行期间也可以将新的变量放入常量池中,而不是一定要在编译时确定的常量才能放入。最主要的运用便是 String 类的 intern() 方法。
总结
- 字符串常量池(String Constant Pool)在每个VM中只有一份,存放的是字符串常量的引用值。
- Class 文件常量池是在编译的时候每个 Class 都有的,在编译阶段,存放的是常量的符号引用。
- 运行时常量池是在类加载完成之后,将每个 Class 文件常量池中的符号引用值转存到运行时常量池中,也就是说,运行时常量池只有一个。
特殊讨论
问题1 - JVM 对字符串拼接的优化
你知道下面的代码,会创建几个字符串对象,在字符串常量池中保存几个引用么?
String test = "a" + "b" + "c";
分析
答案是只创建了一个对象,在字符串常量池中也只保存一个引用。我们使用 javap 反编译看一下即可得知。
public static void main(java.lang.String[]);
Code:
0: ldc #2 // String abc
2: astore_1
3: return
实际上,在编译期间,JVM 已经将这三个字面量合成了一个。这样做实际上是一种优化,避免了创建多余的字符串对象,也没有发生字符串拼接问题。
问题2 - 转换为 StringBuilder 对象
在 Java 中,唯一被重载的运算符就是用于 String 的“+”与“+=”。除此之外,Java 不允许程序员重载其他的运算符。
我们来看一个例子:
String a = "abc";
String b = "mongo";
String info = a + b + 47;
由于 String 对象是不可变的,从表面上看上述的代码过程中可能会是这样工作的:
"abc" + "mongo"会创建一个新的 String 对象,其 value 为abcmongo;"abcmongo" + "47"也会创建一个新的 String 对象 ,其值为abcmongo47;、- info 指向最终生成的 String 对象。
但是,这样的处理方式会生成大量的需要被进行垃圾回收的中间对象,性能相当糟糕。
分析
我们使用 javap 看看上面代码对应的汇编代码,以了解 JVM 到底是如何进行处理的:
public static void main(java.lang.String[]);
Code:
0: ldc #2 // String abc
2: astore_1
3: ldc #3 // String mongo
5: astore_2
6: new #4 // class java/lang/StringBuilder
9: dup
10: invokespecial #5 // Method java/lang/StringBuilder."<init>":()V
13: aload_1
14: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
17: aload_2
18: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
21: bipush 47
23: invokevirtual #7 // Method java/lang/StringBuilder.append:(I)Ljava/lang/StringBuilder;
26: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
29: astore_3
30: return
}
可以看到,编译器自动引入了 StringBuilder 类。
编译器先创建了一个 StringBuilder 对象,并 3 次调用 StringBuilder.append() 方法,最后调用 toString() 生成 abcmongo47,从而避免中间对象的性能损耗。
问题3 - 连接表达式 “+” 使用后相等问题
- 使用“+”连接多个字符串,且每个字符串都是字面量时,在编译阶段,就会进行字符串的连接,并将最终连接完成产生的 String 对象放入字符串常量池中。
- 使用“+”连接多个字符串,如果任何一个字符串是字符串引用(而不是字面值),则所产生的新 String 对象不会被放入到字符串池中。
String str1 = "str";
String str2 = "ing";
String str3 = "str" + "ing";
String str4 = str1 + str2;
String str5 = "string";
System.out.println(str3 == str4);//false
System.out.println(str3 == str5);//true
前面已经提到了,在编译阶段,String str3 = "str" + "ing"; 的写法会直接被优化为 String str3 = "string"; 。
因此 str3 和 str5 没有区别。
但存在一些特例:
特例1
public static final String A = "ab"; // 常量A
public static final String B = "cd"; // 常量B
public static void main(String[] args) {
String s = A + B; // 将两个常量用+连接对s进行初始化
String t = "abcd";
System.out.println(s == t);//true
}
A 和 B 都是常量,值是固定的,因此的值也是固定的,它在类被编译时就已经确定了。也就是说:String s = A + B; 等价于 String s = "ab" + "cd" 。
特例2
public static final String A; // 常量A
public static final String B; // 常量B
static {
A = "ab";
B = "cd";
}
public static void main(String[] args) {
// 将两个常量用+连接对s进行初始化
String s = A + B;
String t = "abcd";
System.out.println(s == t);//false
}
A 和 B 虽然被定义为常量,但是它们都没有在编译阶段被赋值。在运算出 s 的值之前,他们何时被赋值,以及被赋予什么样的值,都是个变数。
因此 A 和 B 在被赋值之前,性质类似于一个变量。那么 s 就不能在编译期被确定,而只能在运行时被创建了。
8种基本类型的包装类和常量池
Java 基本类型的包装类的大部分都实现了常量池技术,即 Byte、Short、Integer、Long、Character、Boolean;这 5 种包装类默认创建了数值为整数且范围为 [-128,127] 的相应类型的缓存数据,但是超出此范围仍然会创建新的对象。
两种浮点数类型的包装类 Float、Double 并没有实现常量池技术。
例子1
Integer i1 = 33;
Integer i2 = 33;
System.out.println(i1 == i2);// 输出true
Integer i11 = 333;
Integer i22 = 333;
System.out.println(i11 == i22);// 输出false
Double i3 = 1.2;
Double i4 = 1.2;
System.out.println(i3 == i4);// 输出false
Integer 缓存源代码:
/**
*此方法将始终缓存-128到127(包括端点)范围内的值,并可以缓存此范围之外的其他值。
*/
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
应用场景:
Integer i1=40;:Java 在编译的时候会直接将代码封装成Integer i1=Integer.valueOf(40);从而使用常量池中的对象。Integer i1 = new Integer(40);:这种情况下会创建新的对象。
Integer i1 = 40;
Integer i2 = new Integer(40);
System.out.println(i1==i2); //输出false
例子2
Integer 比较(==)更丰富的一个例子:
Integer i1 = 40;
Integer i2 = 40;
Integer i3 = 0;
Integer i4 = new Integer(40);
Integer i5 = new Integer(40);
Integer i6 = new Integer(0);
System.out.println("i1=i2 " + (i1 == i2)); //true
System.out.println("i1=i2+i3 " + (i1 == i2 + i3)); //true
System.out.println("i1=i4 " + (i1 == i4)); //false
System.out.println("i4=i5 " + (i4 == i5)); //false
System.out.println("i4=i5+i6 " + (i4 == i5 + i6)); //true
System.out.println("40=i5+i6 " + (40 == i5 + i6)); //true
解释
对于语句 i4 == i5 + i6,由于 + 这个操作符不适用于 Integer 对象。
因此,首先 i5 和 i6 进行自动拆箱操作,进行数值相加。
然后,由于 Integer 对象无法与数值进行直接比较,所以将 i4 自动拆箱转为int 值 40。
最终这条语句转为40 == 40进行数值比较。
Reference
- 《Thinking in Java》
- JVM基础面试题及原理讲解 - http://www.importnew.com/31126.html
- String:字符串常量池 - https://segmentfault.com/a/1190000009888357
- Java中几种常量池的区分 - http://tangxman.github.io/2015/07/27/the-difference-of-java-string-pool/
- java用这样的方式生成字符串:String str = “Hello”,到底有没有在堆中创建对象? - https://www.zhihu.com/question/29884421
- 可能是把Java内存区域讲的最清楚的一篇文章 - https://juejin.im/post/5b7d69e4e51d4538ca5730cb#heading-17
- 深入解析String#intern - https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.htmls
- Java中的字符串常量池 - https://droidyue.com/blog/2014/12/21/string-literal-pool-in-java/
- Java常量池理解与总结 - https://www.jianshu.com/p/c7f47de2ee80
- 常量池之字符串常量池String.intern() - https://cloud.tencent.com/developer/article/1129475
- 为什么String类是不可变的? - http://www.importnew.com/7440.html
- 我终于搞清楚了和String有关的那点事儿。 - https://www.hollischuang.com/archives/2517
- 好好说说Java中的常量池之Class常量池 - https://juejin.im/post/5bd7c0f8e51d457abd7430c6