JVM 内存区域
JVM 内存区域 主要由**运行时数据区域(Runtime data area)、类加载器子系统(Class Loader Subsystem)和执行引擎(Execution Engine)**组成。
JVM 内存区域有时也被称为 JVM 内存结构或 JVM 架构(architecture)。在本文中,我们遵循在《深入理解Java虚拟机:JVM高级特性与最佳实践》中的描述,称为 JVM 内存区域。
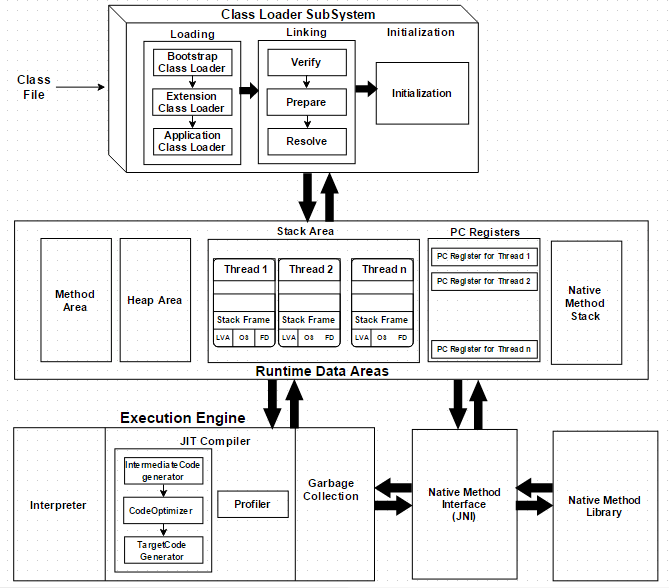
1 运行时数据区(Runtime Data Area)
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的运行时数据区域(Runtime data area)。
运行时数据区域(Runtime data area)包括:
- Java堆(Java Heap)
- 方法区(Method Area)
- Java栈(Java Stack)
- 本地方法栈(Native Method Stack)
- 程序计数器(PC Counters)
Java 堆(Java Heap)
Java 堆(Heap)用于存储动态或临时分配的内存空间。类和数组是在这块区域里创建的。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。Java 堆被是所有线程共享。
Java 堆是垃圾收集器管理的主要区域,因此也被称作GC堆(Garbage Collected Heap)。
从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法(generational garbage collection algorithm),所以 Java 堆还可以细分为:新生代和老年代:再细致一点有:Eden空间、From Survivor、To Survivor空间等。进一步划分的目的是更好地回收内存,或者更快地分配内存。
方法区(Method Area)
方法区与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。
对这块区域进行垃圾回收的主要目标是对常量池的回收和对类的卸载,但是一般比较难实现。
从 JDK 1.8 开始,移除永久代,并把方法区移至元空间,它位于本地内存中,而不是虚拟机内存中。
方法区是一个 JVM 规范,永久代与元空间都是其一种实现方式。在 JDK 1.8 之后,原来永久代的数据被分到了堆和元空间中。元空间存储类的元信息,静态变量和常量池等放入堆中。
运行时常量池(Runtime constant pool)
运行时常量池(Runtime constant pool)是 Java 堆(Heap)的一部分。
Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有常量池信息(用于存放编译期生成的各种字面量和符号引用)
既然运行时常量池是堆的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 异常。
注意,运行时常量池是原本是方法区的一部分,JDK1.7及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。
Java 虚拟机栈(JVM Stacks)
Java 虚拟机栈(JVM Stacks)由一个个**栈帧(Stack Frame)**组成,每个方法被执行时都会创建一个栈帧,而每个栈帧(Stack Frame)中都拥有局部变量表、操作数栈、动态链接、方法出口信息。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
局部变量表主要存放了编译器可知的各种数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
Java 虚拟机栈(JVM Stack)是线程私有的,即每个线程都拥有一个自己的Java 虚拟机栈(JVM Stack)。
本地方法栈(Native Method Stacks)
本地方法栈(Native Method Stacks)和虚拟机栈所发挥的作用非常相似,区别是:虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务的,而本地方法栈则为虚拟机使用到的 Native 方法服务。
本地方法被执行的时候,在本地方法栈也会创建一个栈帧(stack frame),用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。
程序计数器(PC Counters)
**程序计数器(PC Counters)**是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。
字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完。
另外,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
2 类加载器子系统(Class Loader Subsystem)
**类加载器子系统(Class Loader Subsystem)**负责加载程序中的类和接口,并赋予唯一的名字予以标识。
在 Java 中,默认提供的三种类加载器,分别是BootStrapClassLoader(启动类加载器)、ExtClassLoader(扩展类加载器)、AppClassLoader(应用程序类加载器)。
- BootStrapClassLoader(启动类加载器):它由 C++ 实现的,在Java程序中不能显式地获取到。它负责加载存放在
%JAVA_HOME%/jre/lib、%JAVA_HOME%/jre/classes以及-Xbootclasspath参数指定的路径中的类。 - ExtClassLoader(扩展类加载器):它是由sun.misc.Launcher$ExtClassLoader实现,负责加载
%JAVA_HOME%/jre/lib/ext、路径下的所有classes目录以及java.ext.dirs系统变量指定的路径中类库。 - AppClassLoader(应用程序类加载器):由sun.misc.Launcher$AppClassLoader来实现,它负责加载用户类路径(ClassPath)中的类,开发者可以直接使用该类加载器。一般来说,开发者自定义的类就是由应用程序类加载器加载的。
类加载过程
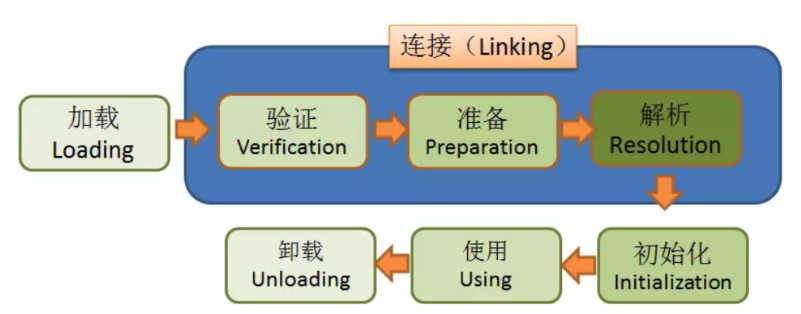
- 加载(Loading):通过一个类的类全局限定名(Fully Qualified Class Name)查找此类字节码文件,并利用字节码文件(.class文件),将这个字节流所代表的静态存储结构转化为方法区(method area)的运行时(runtime)数据结构。
- 链接(Linking):链接是检验类或接口并准备类型和父类接口的过程。链接过程包含三步:校验(Verifying)、准备(Preparing)、解析(Resolutions)。
- 验证(verification):目的在于确保Class文件的字节流中包含信息符合当前虚拟机要求,不会危害虚拟机自身安全。
- 准备(Preparation):分配一个结构用来存储类信息,这个结构中包含了类中定义的成员变量,方法 和接口信息等。
- 为类变量(即在类中由static修饰的字段变量)分配内存并且设置该类变量的初始值即0(如
static int i=5;这里只将 i 初始化为 0,至于 5 的值将在初始化阶段时赋值)。 - 注意,这里不会为实例变量初始化。因为类变量会分配在方法区中,而实例变量是会随着对象一起分配到 Java 堆中。
- 为类变量(即在类中由static修饰的字段变量)分配内存并且设置该类变量的初始值即0(如
- 解析(Resolutions):主要将类的常量池中的符号引用(Symbolic References)替换为直接引用(Direct References)。
- 符号引用(Symbolic References)是一组符号来描述目标,可以是任何字面量;
- 而直接引用(Direct References)就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄。
- 初始化(Initialization):类加载最后阶段,执行静态初始化程序,类把静态变量初始化成指定的值。
- 若该类具有超类,则对其进行初始化,执行静态初始化器和为类变量真正赋值(在准备阶段,只为类的 static 变量赋了系统默认值,而在初始化阶段将会为类变量真正赋值),成员变量也将被初始化。
3 执行引擎(Execution Engine)
通过类加载器加载,被分配到 JVM 的**运行时数据区(Runtime data area)的字节码会被执行引擎(Execution Engine)**执行。
执行引擎以指令为单位读取 Java 字节码。它就像一个 CPU 一样,一条一条地执行机器指令。每个字节码指令都由一个1字节的操作码和附加的操作数组成。执行引擎 取得一个操作码,然后根据操作数来执行任务,完成后就继续执行下一条操作码。
不过 Java 字节码是用一种人类可以读懂的语言编写的,而不是用机器可以直接执行的语言。因此,执行引擎必须把字节码转换成可以直接被 JVM 执行的语言。
字节码可以通过以下两种方式转换成机器语言:
-
解释器(Interpreter)
解释器 一条一条地读取字节码,解释并且执行 字节码指令。因为它一条一条地解释和执行指令,所以它可以很快地解释字节码,但是执行起来会比较慢。这是解释执行的语言的一个缺点。字节码这种“语言”基本来说是解释执行的。
-
即时(Just-In-Time)编译器
即时(Just-In-Time)编译器被引入用来弥补解释器的缺点。执行引擎 首先按照 解释执行 的方式来执行,然后在合适的时候,即时编译器 把 整段字节码 编译成 本地代码。然后,执行引擎就没有必要再去解释执行方法了,它可以直接通过本地代码去执行它。执行本地代码比一条一条进行解释执行的速度快很多。编译后的代码可以执行的很快,因为本地代码是保存在缓存里的。
Java 字节码是解释执行的,但是没有直接在 JVM 宿主执行原生代码快。为了提高性能,Oracle Hotspot 虚拟机会找到执行最频繁的字节码片段并把它们编译成原生机器码。编译出的原生机器码被存储在非堆内存的代码缓存中。
通过这种方法(JIT),Hotspot 虚拟机将权衡下面两种时间消耗:将字节码编译成本地代码需要的额外时间和解释执行字节码消耗更多的时间。
Reference
-
《深入理解Java虚拟机:JVM高级特性与最佳实践》
-
JVM Architecture – Understanding JVM Internals - https://www.javainterviewpoint.com/java-virtual-machine-architecture-in-java/#respond
-
JVM(一)史上最佳入门指南 - https://www.imooc.com/article/272234
-
JVM基础面试题及原理讲解 - http://www.importnew.com/31126.html
-
JVM系列(一) - JVM总体概述 - https://juejin.im/post/5b4de8185188251af86be259
-
Java虚拟机(JVM)概述 - http://www.importnew.com/29224.html
-
可能是把Java内存区域讲的最清楚的一篇文章 - https://juejin.im/post/5b7d69e4e51d4538ca5730cb
-
深入理解JVM类加载机制 - https://juejin.im/post/5a1d5f286fb9a045132a7100
-
Java虚拟机 —— 类的加载机制 - https://juejin.im/post/59c4dd9e5188257e876a1aee
-
Jvm原理入门 - https://leeyuan.cf/2018/02/03/Jvm%E5%8E%9F%E7%90%86%E5%85%A5%E9%97%A8/