Components
Topic:Kafka将消息种子(Feed)分门别类, 每一类的消息称之为 Topic。
Partition: 一个 topic 可以被分为若干个分区(partition),同一个 topic 中的不同分区可以不在一个 broker上。即通过部署在多个 broker 上,来实现 kafka 的伸缩性,单一 topic 中的一个partition可以被保证有序,但是无法保证 topic 中所有的分区有序。
- A topic could have multiple partitions.
- Each partition is a single log file where records are written to it in an append-only fashion.
- 一个非常大的 Topic 可以分布到多个 Broker 上,一个 Topic 可以分为多个 Partition 进行存储,每个 Partition 是一个有序的队列。
- 一个broker可能同时是一个partition的leader,另一个partition的follower。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
- 每个partition有一个leader,零或多个follower。Leader处理此partition的所有的读写请求而follower被动的复制数据。如果leader当机,其它的一个follower会被推举为新的leader。
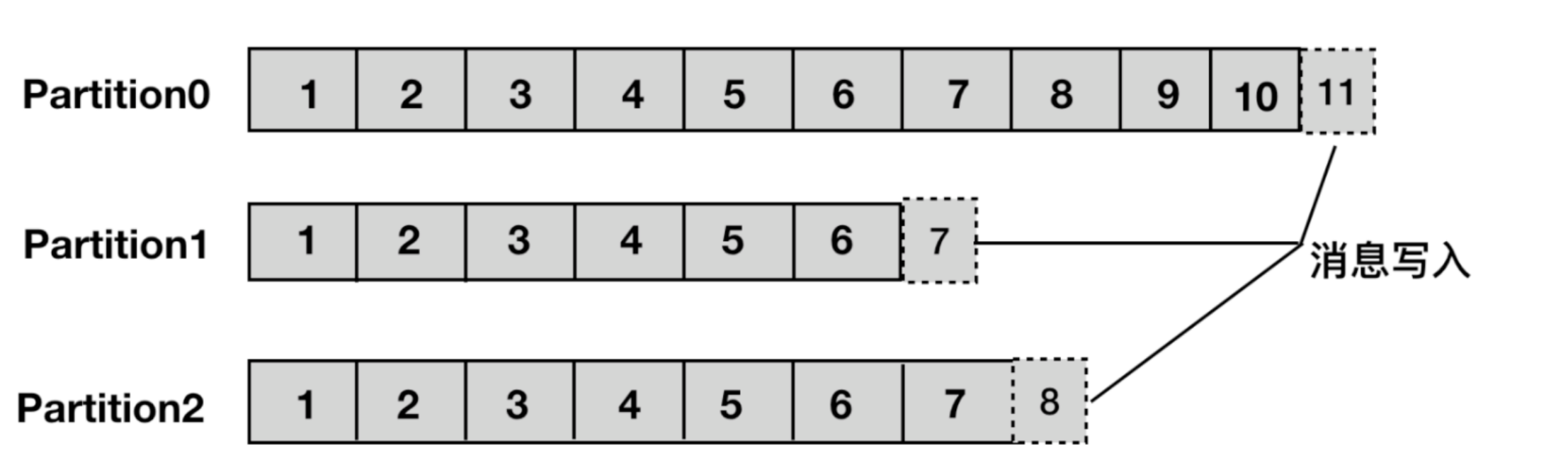
Producer: 发布消息的对象称之为 Topic Producer
Consumer: 订阅消息并处理发布的消息的种子的对象称之为 Topic Consumers
Consumer Group:生产者与消费者的关系就如同餐厅中的厨师和顾客之间的关系一样,一个厨师对应多个顾客,也就是一个生产者对应多个消费者,消费者群组(Consumer Group)指的就是由一个或多个消费者组成的群体。
- 一个topic下的一条消息只会由一个消费者组中的一个消费者消费,而不会被这个消费者组中的其他消费者也同时消费
- 处于不同消费者组的消费者可以同时消费同一个topic中的同一消息
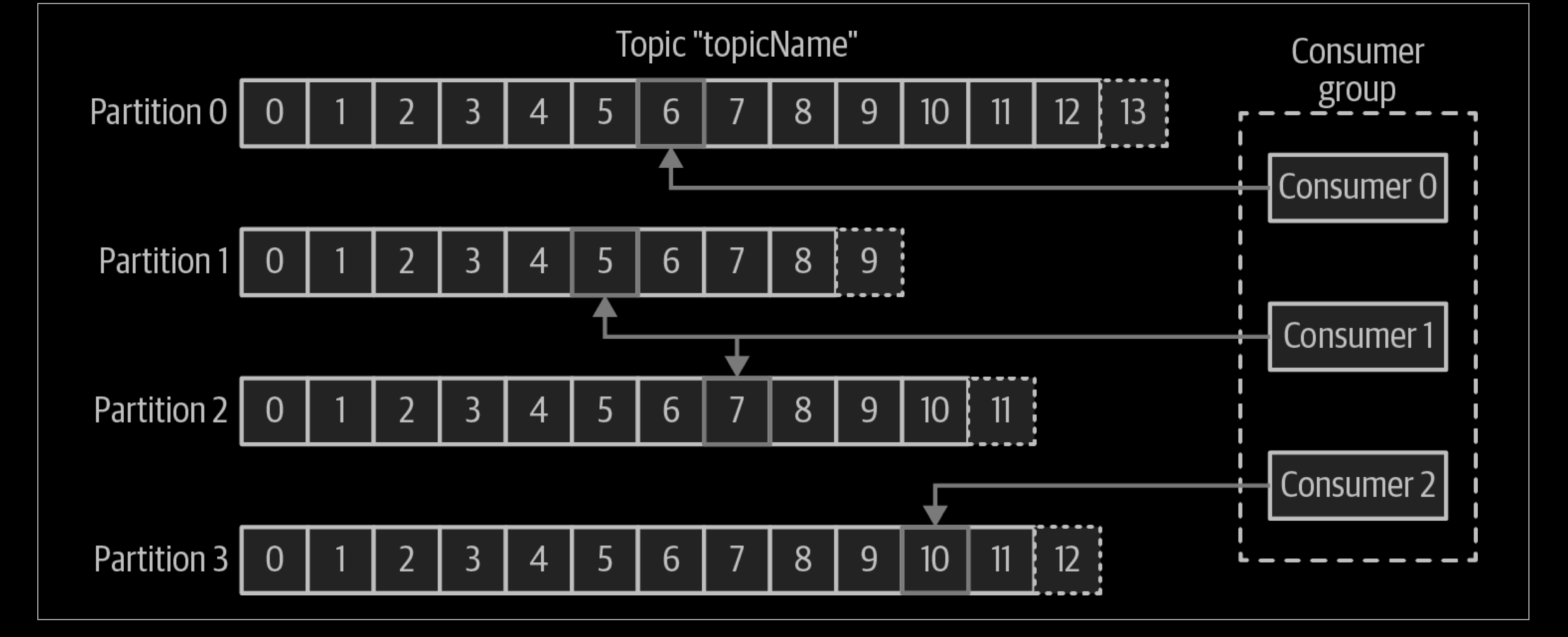
Broker:已发布的消息保存在一组 Server中,这一组服务器被称为一个Kafka集群。集群中的每一个 Kafka Server都是一个 Broker。消费者可以订阅一个或多个 topic ,并从Broker拉数据,从而消费这些已发布的消息。
Rebalance:消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅 topic 分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
Replica:Kafka 中消息的备份又叫做 副本(Replica),为实现数据备份的功能,保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kafka 仍然能够继续工作,为此Kafka提供了副本机制,一个 Topic 的每个 Partition 都有若干个副本,一个 Leader 副本和若干个 Follower 副本。
Leader: 每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
Follower: Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
Consumer Offset: an integer value that continually increases—is another piece of metadata that Kafka adds to each message as it is produced.
- Each message in a given partition has a unique offset, and the following message has a greater offset (though not necessarily monotonically greater).
- By storing the next possible offset for each partition, typically in Kafka itself, a consumer can stop and restart without losing its place.
Offset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。
Kafka Controller Broker:其实就是一个 Kafka 集群中一台 Broker,它除了具有普通Broker 的消息发送、消费、同步功能之外,还需承担一些额外的工作。Kafka 使用公平竞选的方式来确定 Controller ,最先在 ZooKeeper 成功创建临时节点 /controller 的Broker会成为 Controller ,一般而言,Kafka集群中第一台启动的 Broker 会成为Controller,并将自身 Broker 编号等信息写入ZooKeeper临时节点/controller。
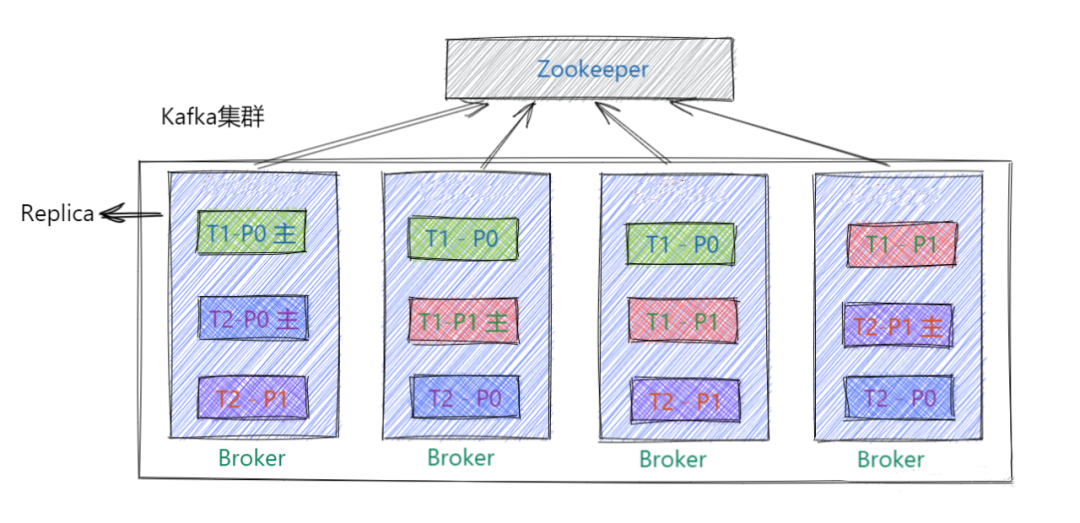
工作流程
Kafka集群会将消息流存储在 Topic 的中,每条记录会由一个Key、一个Value和一个时间戳组成。
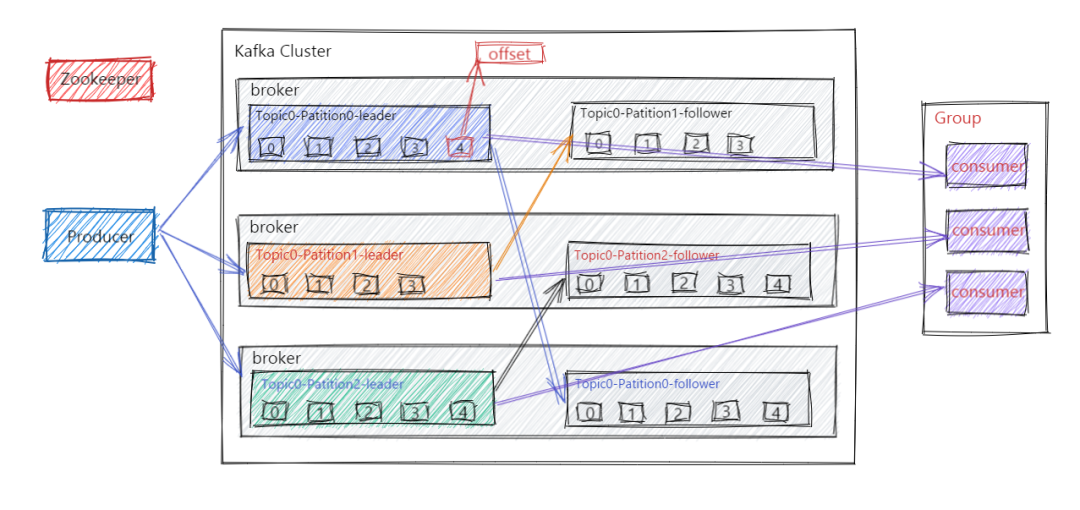
Kafka 中消息是以 Topic 进行分类的,生产者生产消息,消费者消费消息,读取和消费的都是同一个 Topic。但是Topic 是逻辑上的概念, Partition 是物理上的概念,每个 Partition 对应一个 log 文件,该 log 文件中存储的就是 Producer 生产的数据。Producer 端生产的数据会不断顺序追加到该 log 文件末尾,并且每条数据都会记录有自己的 Offset。而消费者组中的每个消费者,也都会实时记录当前自己消费到了哪个 Offset,方便在崩溃恢复时,可以继续从上次的 Offset 位置消费。
Kafka的保证(Guarantees)
- 生产者发送到一个特定的Topic的一个特定partition上的消息将会按照它们发送的顺序依次加入
- 消费者收到的消息也是此顺序
- 如果一个Topic配置了复制因子(replication factor)为N, 那么可以在最多N-1个 brokers down掉时,仍不丢失任何已经successfully produced的消息
Kafka APIs
In addition to command line tooling for management and administration tasks, Kafka has five core APIs for Java and Scala:
- The Admin API to manage and inspect topics, brokers, and other Kafka objects.
- The Producer API to publish (write) a stream of events to one or more Kafka topics.
- The Consumer API to subscribe to (read) one or more topics and to process the stream of events produced to them.
- The Kafka Streams API to implement stream processing applications and microservices. It provides higher-level functions to process event streams, including transformations, stateful operations like aggregations and joins, windowing, processing based on event-time, and more. Input is read from one or more topics in order to generate output to one or more topics, effectively transforming the input streams to output streams.
- The Kafka Connect API to build and run reusable data import/export connectors that consume (read) or produce (write) streams of events from and to external systems and applications so they can integrate with Kafka. For example, a connector to a relational database like PostgreSQL might capture every change to a set of tables. However, in practice, you typically don’t need to implement your own connectors because the Kafka community already provides hundreds of ready-to-use connectors.
User Case
- Commit Log
- Event Sourcing
- Stream Processing
- Log Aggregation
- Metrics
- Website Activity Tracking
Reference
- Kafka The definition Guide
- https://kafka.apache.org/documentation/
- https://kafka.apache.org/uses
- https://colobu.com/2014/08/06/kafka-quickstart/
- https://docs.confluent.io/platform/current/clients/producer.html
- https://mp.weixin.qq.com/s?__biz=Mzg3MTcxMDgxNA==&mid=2247488841&idx=1&sn=2ea884012493403ab45b450271708fc8&chksm=cefb3c78f98cb56e4580cf8529bc8510df121786a8bf341a8660037cdb4f4cbb4925dc7fa616&scene=178&cur_album_id=2147575846151290880#rd