Kafka 的已提交的消息(committed message)
一句话概括,Kafka 只对已提交的消息(committed message)做有限度的持久化保证。
已提交的消息
什么是已提交的消息?当 Kafka 的若干个 Broker 成功地接收到一条消息并写入到日志文件后,它们会告诉 Producer 这条消息已成功提交(ACK)。此时,这条消息在 Kafka 看来就正式变为“已提交”消息了。
那为什么是若干个 Broker 呢?这取决于你对“已提交”的定义。你可以选择只要有一个 Broker 成功保存该消息就算是已提交,也可以是令所有 Broker 都成功保存该消息才算是已提交。不论哪种情况,Kafka 只对已提交的消息做持久化保证这件事情是不变的。
有限度的持久化保证
也就是说 Kafka 不可能保证在任何情况下都做到不丢失消息。
有限度其实就是说 Kafka 不丢消息是有前提条件的。假如你的消息保存在 N 个 Kafka Broker 上,那么这个前提条件就是这 N 个 Broker 中至少有 1 个存活。只要这个条件成立,Kafka 就能保证你的这条消息永远不会丢失。
可能丢失消息的各个阶段
1. 生产阶段
Broker 逻辑
在Kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到,其中状态有[0,1,all]。
acks=0: 表示Producer发送完消息后不会等待任何Broker的ACK,即发送后就自认为发送一定会成功- 这时如果发生网络抖动, 消息就可能发送失败
acks=1: 表示当Broker集群中的 Leaders 将消息写入到自己的Page Cache后(不会等待 followers进行完写入),才返回ACK给 Producer- 如果leader收到消息,会在成功写入PageCache后,才会返回ACK,此时 Producer 认为消息发送成功
- 即只要 Leader Partition 不 Crash 掉,就可以保证 Leader Partition 不丢数据,但是如果 Leader Partition 异常 Crash 掉了, Follower Partition 还未同步完数据且没有 ACK,这时就会丢数据。
acks=all: 表示当Broker集群中leader和其所有follower都将消息写入到自己的Page Cache后,Follower Partition 才返回ACK给 Producer-
具体来说
- Kafka Broker 对应的 Leader Partition 收到消息后,会先写入 Page Cache
- Follower Partition 拉取 Leader Partition 的消息并保持同 Leader Partition 数据一致,待消息拉取完毕后需要给 Leader Partition 回复 ACK 确认消息。
- 待 Kafka Leader 与 Follower Partition 同步完数据并收到所有 ISR 中的 Replica 副本的 ACK 后,Leader Partition 会给 Producer 回复 ACK 确认消息。
-
消息发送需要等待 ISR(in-sync replicas) 中 Leader Partition 和 Follower Partitions 都确认收到消息才算发送成功,可靠性最高
-
但也不能保证不丢数据,比如当 ISR 中只剩下 Leader Partition 了,这样就变成
acks = 1的情况了。
-
Producer 逻辑
Producer端可能会丢失消息。Kafka Producer通常是异步发送消息的,也就是说如果你调用的是producer.send(msg)这个API,那么它通常会立即返回,但此时这个 function 不会保证消息的发送已成功完成了。可能会出现:网络抖动,导致消息压根就没有发送到Broker端;或者消息本身不合规导致Broker拒绝接收(比如消息太大了,超过了Broker的限制)。
实际上,使用producer.send(msg, callback)接口就能避免这个问题,根据回调,一旦出现消息提交失败的情况,就可以有针对性地进行处理。如果是因为那些瞬时错误,Producer重试就可以了;如果是消息不合规造成的,那么调整消息格式后再次发送。
导致 Producer 端消息没有发送成功有以下原因:
- **网络原因:**由于网络抖动导致数据根本就没发送到 Broker 端。
- **数据原因:**消息体太大超出 Broker 承受范围而导致 Broker 拒收消息。
2. 存储阶段
KafkaBroker 集群接收到数据后,会将数据进行持久化存储到磁盘,为了提高吞吐量和性能,采用的是「异步批量刷盘的策略」,也就是说按照一定的消息量和间隔时间进行刷盘。首先会将数据存储到位于内存的页缓存(Page cache) 中,至于什么时候将 Page cache 中的数据刷盘是由「操作系统」根据自己的策略决定(按照时间或者其他条件),或者调用方显式调用 fsync 命令以进行强制刷盘。如果此时还未进行刷盘(数据仍在 Page Cache中),Broker 就宕机 Crash 掉,且选举了一个落后 Leader Partition 很多的 Follower Partition 成为新的 Leader Partition,那么落后的消息数据就会丢失。
总结来说,刷盘触发条件有三:
- 主动调用
sync或fsync函数 - 可用内存低于阀值
- dirty data时间达到阀值。dirty是 Page cache 的一个标识位,当有数据写入到pageCache时,pagecache被标注为dirty,数据刷盘以后,dirty标志清除。
既然 Broker 端消息存储是通过异步批量刷盘的,那么这里就可能会丢数据的 !!!
- 由于 Kafka 中并没有提供「同步刷盘」的方式,所以说从单个 Broker 来看还是很有可能丢失数据的。
- kafka 通过「**多 Partition (分区)多 Replica(副本)机制」**已经可以最大限度的保证数据不丢失,如果数据已经写入 PageCache 中但是还没来得及刷写到磁盘,此时如果所在 Broker 突然宕机挂掉或者停电,极端情况还是会造成数据丢失。
配置参数
在 Kafka 中,可以通过以下参数调节刷盘的行为:
flush.messages
This setting allows specifying an interval at which we will force an fsync of data written to the log. For example if this was set to 1 we would fsync after every message; if it were 5 we would fsync after every five messages. In general we recommend you not set this and use replication for durability and allow the operating system’s background flush capabilities as it is more efficient. This setting can be overridden on a per-topic basis (see the per-topic configuration section).
| Type: | long |
|---|---|
| Default: | 9223372036854775807 |
| Valid Values: | [1,…] |
| Server Default Property: | log.flush.interval.messages |
| Importance: | medium |
flush.ms
This setting allows specifying a time interval at which we will force an fsync of data written to the log. For example if this was set to 1000 we would fsync after 1000 ms had passed. In general we recommend you not set this and use replication for durability and allow the operating system’s background flush capabilities as it is more efficient.
| Type: | long |
|---|---|
| Default: | 9223372036854775807 |
| Valid Values: | [0,…] |
| Server Default Property: | log.flush.interval.ms |
| Importance: | medium |
3. 消费阶段
Broker 逻辑
Consumer有个”位移“(offset)的概念,表示Consumer当前消费到topic分区的哪个位置。下次继续消费的时候,会接着上次的offset进行消费。如图:
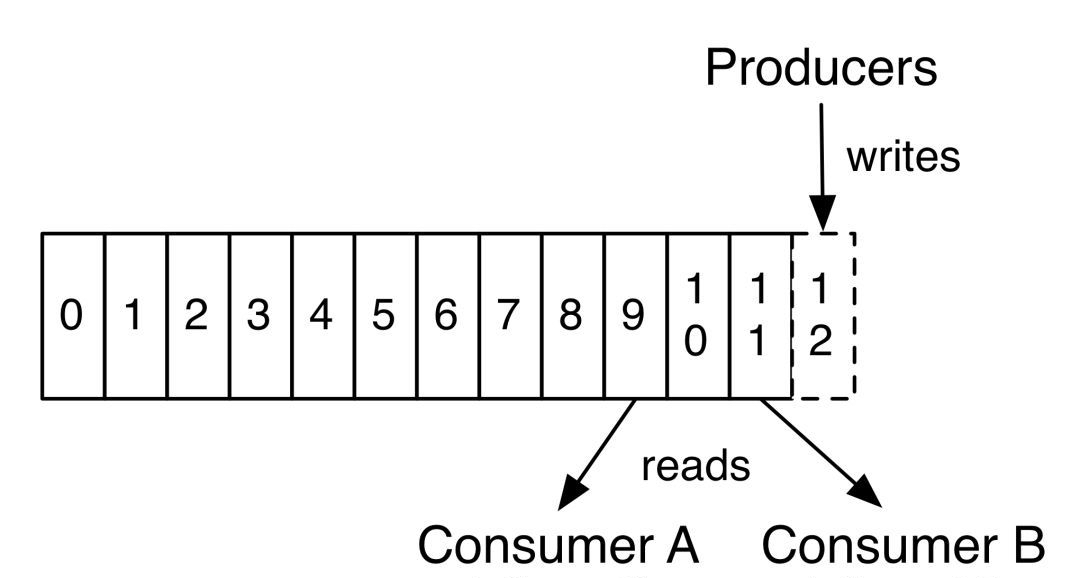
而offset的信息在Kafka0.8版本之前保存在Zookeeper中,在0.8版本之后保存到topic中,即使消费者在运行过程中挂掉了,再次启动的时候会找到offset的值,找到之前消费消息的位置,接着消费,由于 offset的信息写入的时候并不是每条消息消费完成后都写入的,所以这种情况有可能会造成重复消费,但是不会丢失消息。
Consumer 逻辑
拉取消息后「先提交 Offset,后处理消息」,如果此时处理消息的时候异常宕机,由于 Offset 已经提交了,待 Consumer 重启后,会从之前已提交的 Offset 下一个位置重新开始消费, 之前未处理完成的消息不会被再次处理,对于该 Consumer 来说消息就丢失了。
拉取消息后「先处理消息,在进行提交 Offset」, 如果此时在提交之前发生异常宕机,由于没有提交成功 Offset, 待下次 Consumer 重启后还会从上次的 Offset 重新拉取消息,不会出现消息丢失的情况, 但是会出现重复消费的情况,这里只能业务自己保证幂等性。
Reference
- https://kafka.apache.org/documentation/
- https://docs.confluent.io/platform/current/installation/configuration/topic-configs.html#flush-messages
- https://mp.weixin.qq.com/s?__biz=Mzg3MTcxMDgxNA==&mid=2247490489&idx=1&sn=17817f6d9837ad6a8823362d5ed38687&chksm=cefb3288f98cbb9edeb568e51127c25caa90da6dd064936560a851a9c9e5b865bb49ca04312d&scene=178&cur_album_id=2147575846151290880#rd
- https://book.itheima.net/study/1269935677353533441/1268384446134919169/1272783286749372418
- https://juejin.cn/post/7102243362471673892
- https://zhuanlan.zhihu.com/p/307480336