Retention
A key feature of Apache Kafka is that of retention, which is the durable storage of messages for some period of time. Kafka brokers are configured with a default retention setting for topics, either retaining messages for some period of time (e.g., 7 days) or until the partition reaches a certain size in bytes (e.g., 1 GB). Once these limits are reached, messages are expired and deleted. In this way, the retention configuration defines a minimum amount of data available at any time. Individual topics can also be configured with their own retention settings so that messages are stored for only as long as they are useful. For example, a tracking topic might be retained for several days, whereas application metrics might be retained for only a few hours. Topics can also be configured as log compacted, which means that Kafka will retain only the last message produced with a specific key. This can be useful for changelog-type data, where only the last update is interesting.
Disk-Based Retention
Not only can Kafka handle multiple consumers, but durable message retention means that consumers do not always need to work in real time. Messages are written to disk and will be stored with configurable retention rules. These options can be selected on a per-topic basis, allowing for different streams of messages to have different amounts of retention depending on the consumer needs. Durable retention means that if a consumer falls behind, either due to slow processing or a burst in traffic, there is no danger of losing data. It also means that maintenance can be performed on consum‐ers, taking applications offline for a short period of time, with no concern about messages backing up on the producer or getting lost. Consumers can be stopped, and the messages will be retained in Kafka. This allows them to restart and pick up processing messages where they left off with no data loss.
Clearly there are multiple possible message delivery guarantees that could be provided:
- At most once—Messages may be lost but are never redelivered.
- At least once—Messages are never lost but may be redelivered.
- Exactly once—this is what people actually want, each message is delivered once and only once.
It’s worth noting that this breaks down into two problems: the durability guarantees for publishing a message and the guarantees when consuming a message.
Many systems claim to provide “exactly once” delivery semantics, but it is important to read the fine print, most of these claims are misleading (i.e. they don’t translate to the case where consumers or producers can fail, cases where there are multiple consumer processes, or cases where data written to disk can be lost).
Storage
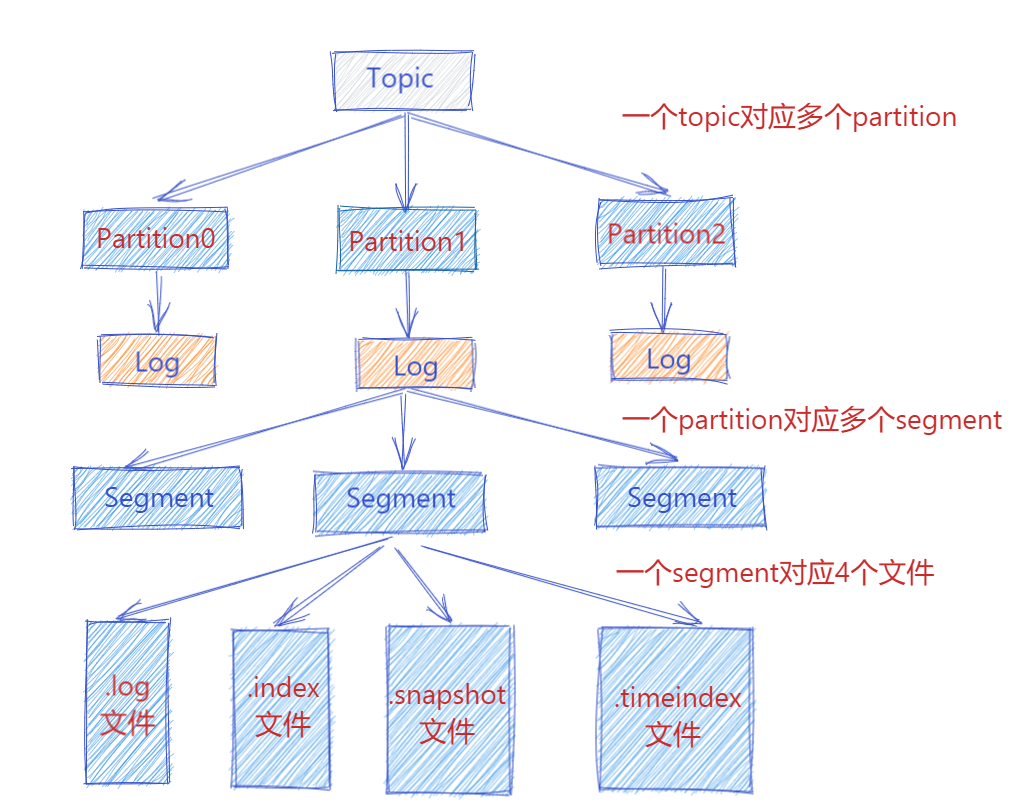
此时 Producer 端生产的消息会不断追加到 log 文件末尾,这样文件就会越来越大, 为了防止 log 文件过大导致数据定位效率低下,那么Kafka 采取了分片和索引机制。它将每个 Partition 分为多个 Segment,每个 Segment 对应4个文件:“.index” 索引文件, “.log” 数据文件, “.snapshot” 快照文件, “.timeindex” 时间索引文件。这些文件都位于同一文件夹下面,该文件夹的命名规则为:topic 名称-分区号。例如, heartbeat心跳上报服务 这个 topic 有三个分区,则其对应的文件夹为 heartbeat-0,heartbeat-1,heartbeat-2这样。
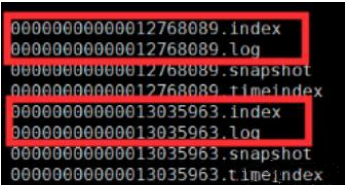
index, log, snapshot, timeindex 文件以当前 Segment 的第一条消息的 Offset 命名。其中 “.index” 文件存储大量的索引信息,“.log” 文件存储大量的数据,索引文件中的元数据指向对应数据文件中 Message 的物理偏移量。
下图为index 文件和 log 文件的结构示意图:
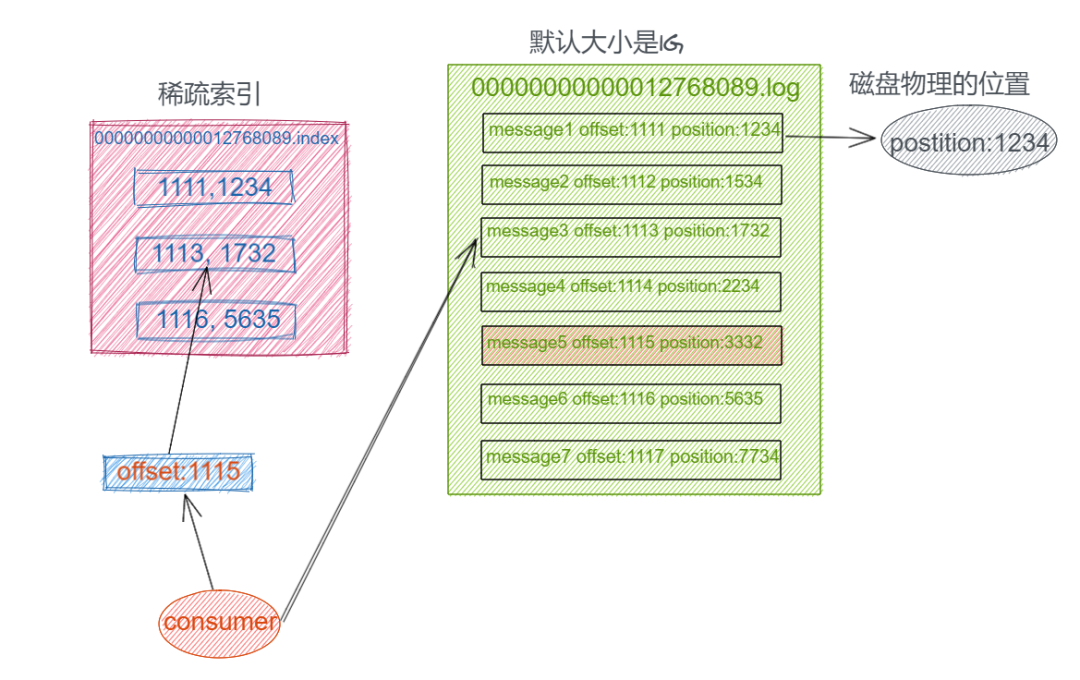
Physical Storage
The other inefficiency is in byte copying. At low message rates this is not an issue, but under load the impact is significant. To avoid this we employ a standardized binary message format that is shared by the producer, the broker, and the consumer (so data chunks can be transferred without modification between them).
The message log maintained by the broker is itself just a directory of files, each populated by a sequence of message sets that have been written to disk in the same format used by the producer and consumer. Maintaining this common format allows optimization of the most important operation: network transfer of persistent log chunks. Modern unix operating systems offer a highly optimized code path for transferring data out of pagecache to a socket; in Linux this is done with the sendfile system call.
When configuring Kafka, the administrator defines a list of directories in which the partitions will be stored—this is the log.dirs parameter (not to be confused with the location in which Kafka stores its error log, which is configured in the log4j.properties file). The usual configuration includes a directory for each mount point that Kafka will use.
# If we produce one msg
$ kafka-console-producer --broker-list 192.168.18.129:9092 --topic aaa_bbb_topic --producer-property acks=all
>111
# at broker
$ pwd
/home/sw/kafka/logs
$ cat aaa_bbb_topic-0/00000000000000000000.log
;�]\~��l~��l��������������111%
Reference
- Kafka The definition Guide
- https://kafka.apache.org/documentation/