Produce
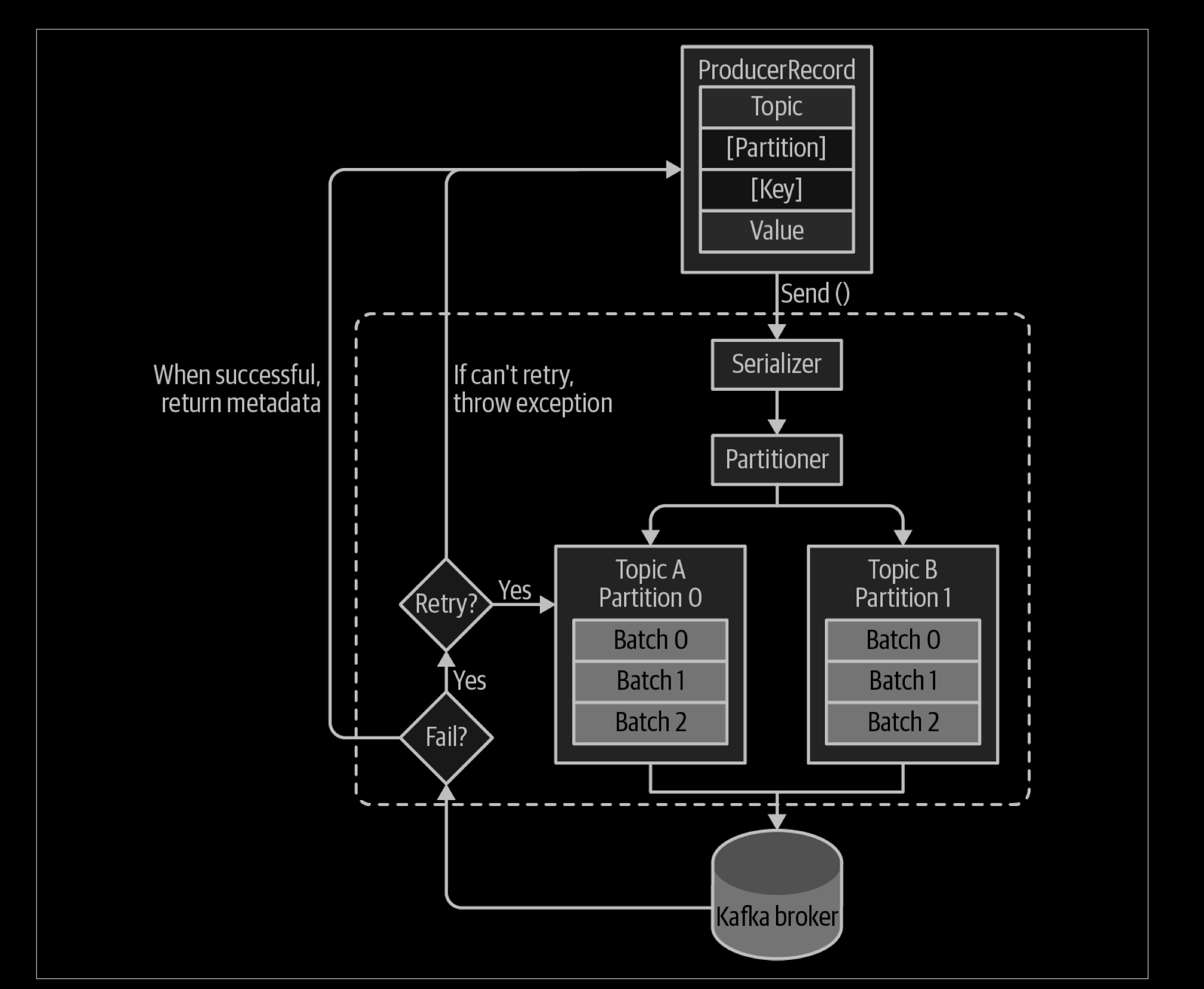
We start producing messages to Kafka by creating a ProducerRecord, which must include the topic we want to send the record to and a value. Optionally, we can also specify a key, a partition, a timestamp, and/or a collection of headers. Once we send the ProducerRecord, the first thing the producer will do is serialize the key and value objects to byte arrays so they can be sent over the network.
Next, if we didn’t explicitly specify a partition, the data is sent to a partitioner. The partitioner will choose a partition for us, usually based on the ProducerRecord key. Once a partition is selected, the producer knows which topic and partition the record will go to. It then adds the record to a batch of records that will also be sent to the same topic and partition. A separate thread is responsible for sending those batches of records to the appropriate Kafka brokers.
When the broker receives the messages, it sends back a response. If the messages were successfully written to Kafka, it will return a RecordMetadata object with the topic, partition, and the offset of the record within the partition. If the broker failed to write the messages, it will return an error. When the producer receives an error, it may retry sending the message a few more times before giving up and returning an error.
Synchronous send
Technically, Kafka producer is always asynchronous—we send a message and the send() method returns a Future object. However, we use get() to wait on the Future and see if the send() was successful or not before sending the next record.
Sending a message synchronously is simple but still allows the producer to catch exceptions when Kafka responds to the produce request with an error, or when send retries were exhausted. The main trade-off involved is performance. Depending on how busy the Kafka cluster is, brokers can take anywhere from 2 ms to a few seconds to respond to produce requests.
If you send messages synchronously, the sending thread will spend this time waiting and doing nothing else, not even sending additional messages. This leads to very poor performance, and as a result, synchronous sends are usually not used in production applications (but are very common in code examples).
Asynchronous send
Suppose the network round-trip time between our application and the Kafka cluster is 10 ms. If we wait for a reply after sending each message, sending 100 messages will take around 1 second.
- On the other hand, if we just send all our messages and not wait for any replies, then sending 100 messages will barely take any time at all. In most cases, we really don’t need a reply—Kafka sends back the topic, partition, and offset of the record after it was written, which is usually not required by the sending app.
- On the other hand, we do need to know when we failed to send a message completely so we can throw an exception, log an error, or perhaps write the message to an “errors” file for later analysis.
To send messages asynchronously and still handle error scenarios, the producer supports adding a callback when sending a record.
It is not recommended to perform a blocking operation within the callback. Instead, you should use another thread to perform any blocking operation concurrently.
acks
The acks parameter controls how many partition replicas must receive the record before the producer can consider the write successful. By default, Kafka will respond that the record was written successfully after the leader received the record (release 3.0 of Apache Kafka is expected to change this default). This option has a significant impact on the durability of written messages, and depending on your use case, the default may not be the best choice.
acks=0: The producer will not wait for a reply from the broker before assuming the message was sent successfully. This means that if something goes wrong and the broker does not receive the message, the producer will not know about it, and the message will be lost. However, because the producer is not waiting for any response from the server, it can send messages as fast as the network will support, so this setting can be used to achieve very high throughput.acks=1: The producer will receive a success response from the broker the moment the leader replica receives the message. If the message can’t be written to the leader (e.g., if the leader crashed and a new leader was not elected yet), the producer will receive an error response and can retry sending the message, avoiding potential loss of data. The message can still get lost if the leader crashes and the latest messages were not yet replicated to the new leader.- 如果leader收到消息,会在成功写入PageCache后,才会返回ACK,此时 Producer 认为消息发送成功
- 等待多少个 Leaders 将消息写入到自己的Page Cache后,才返回ACK给 Producer
- 即只要 Leader Partition 不 Crash 掉,就可以保证 Leader Partition 不丢数据,但是如果 Leader Partition 异常 Crash 掉了, Follower Partition 还未同步完数据且没有 ACK,这时就会丢数据。
acks=all: 表示当Broker集群中leader和其所有follower都将消息写入到自己的Page Cache后,Follower 才返回ACK给 Producer- 具体来说
- Kafka Broker 对应的 Leader Partition 收到消息后,会先写入 Page Cache
- Follower Partition 拉取 Leader Partition 的消息并保持同 Leader Partition 数据一致,待消息拉取完毕后需要给 Leader Partition 回复 ACK 确认消息。
- 当 Leader 收到所有in-sync replicas (ISR)的 ACK 后,Leader Partition 会给 Producer 回复 ACK 确认消息。
- Leader当然也是ISR中的一员
- 但也不能保证不丢数据,比如当 ISR 中只剩下 Leader Partition 了,这样就变成
acks = 1的情况了。
- 具体来说
Load Balance
The producer sends data directly to the broker that is the leader for the partition without any intervening routing tier. To help the producer do this all Kafka nodes can answer a request for metadata about which servers are alive and where the leaders for the partitions of a topic are at any given time to allow the producer to appropriately direct its requests.
The client controls which partition it publishes messages to. This can be done at random, implementing a kind of random load balancing, or it can be done by some semantic partitioning function. We expose the interface for semantic partitioning by allowing the user to specify a key to partition by and using this to hash to a partition (there is also an option to override the partition function if need be). For example if the key chosen was a user id then all data for a given user would be sent to the same partition. This in turn will allow consumers to make locality assumptions about their consumption. This style of partitioning is explicitly designed to allow locality-sensitive processing in consumers.
Partition
生产者往某个Topic上发布消息。生产者也负责选择发布到这此Topic上的哪一个partition。最简单的方式从partition列表中轮流选择。也可以根据某种算法依照权重选择partition。开发者负责如何选择partition的算法。
Producer 逻辑
初始化
Kafka Producer 初始化流程如下:
1)、设置分区器(partitioner), 分区器是支持自定义的 2)、设置重试时间(retryBackoffMs)默认100ms 3)、设置序列化器(Serializer) 4)、设置拦截器(interceptors) 5)、初始化集群元数据(metadata),刚开始空的 6)、设置最大的消息为多大(maxRequestSize), 默认最大1M, 生产环境可以提高到10M 7)、设置缓存大小(totalMemorySize) 默认是32M 8)、设置压缩格式(compressionType) 9)、初始化RecordAccumulator也就是缓冲区指定为32M 10)、定时更新(metadata.update) 11)、创建NetworkClient 12)、创建Sender线程 13)、KafkaThread将Sender设置为守护线程并启动
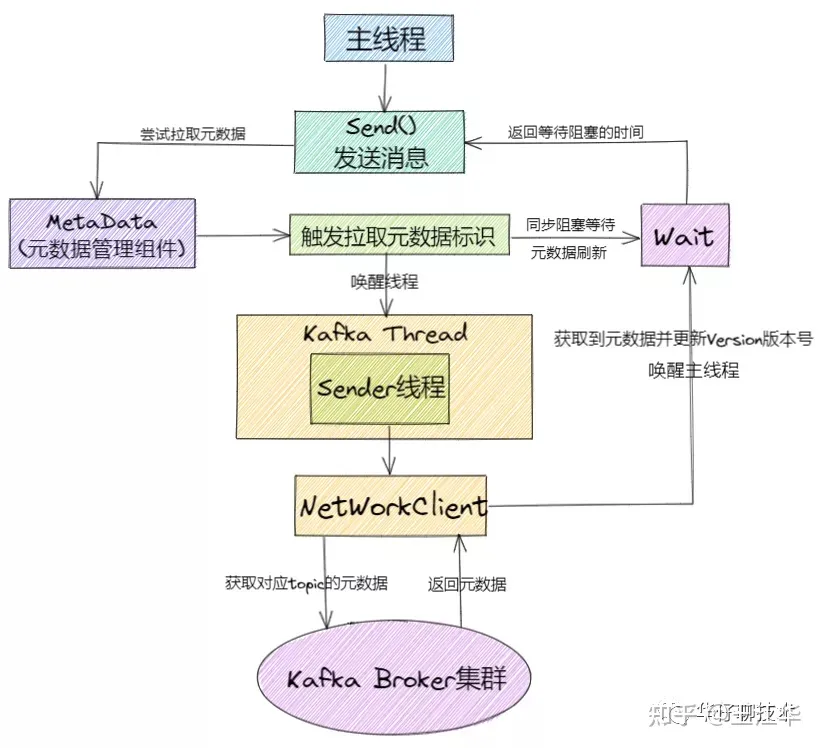
Kafka Producer 拉取元数据流程如下:
1)、主线程调用send()尝试拉取元数据 2)、元数据组件触发拉取元数据信息的标识并同步wait元数据的刷新 3)、唤醒 KafkaThread Sender 线程并 wait 等待拉取完成 4)、KafkaThread Sender 线程通过NetWorkClient 从kafka Broker 集群拉取元数据 5)、kafka Broker 集群给NetWorkClient返回元数据响应 6)、拉取到元数据以后,更新version版本号到 MetaData组件,并唤醒主线程 7)、主线程继续往下执行
Producer之发送流程
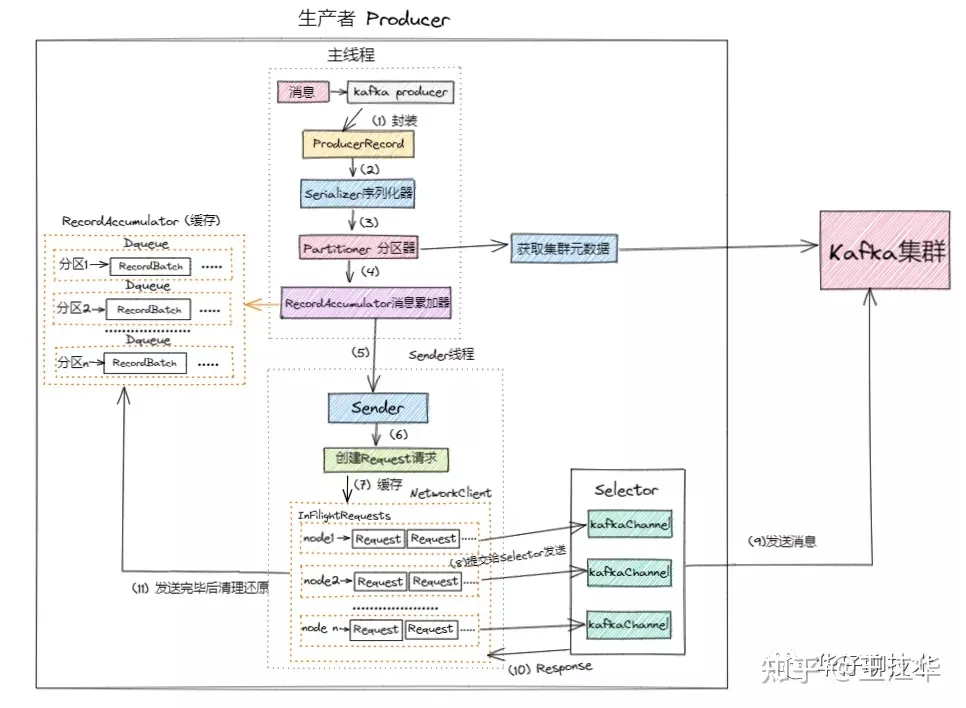
Kafka Producer 发送消息流程如下:
1)、进行 Kafka Producer 初始化,加载默认配置以及设置的配置参数,开启网络线程; 2)、执行拦截器逻辑,预处理消息, 封装 Producer Record 3)、调用Serializer.serialize()方法进行消息的key/value序列化 4)、调用partition()选择合适的分区策略,给消息体 Producer Record 分配要发送的 topic 分区号 5)、从 Kafka Broker 集群获取集群元数据metadata 6)、将消息缓存到RecordAccumulator收集器中, 最后判断是否要发送。这个加入消息收集器,首先得从 Deque 里找到自己的目标分区,如果没有就新建一个批量消息 Deque 加进入 7)、如果达到发送阈值,唤醒Sender线程,实例化 NetWorkClient 将 batch record 转换成 request client 的发送消息体, 并将待发送的数据按 【Broker Id <=> List】的数据进行归类 8)、与服务端不同的 Broker 建立网络连接,将对应 Broker 待发送的消息 List 发送出去。 9)、批次发送的条件为:缓冲区数据大小达到 batch.size 或者 linger.ms 达到上限,哪个先达到就算哪个
Producer 内存池设计
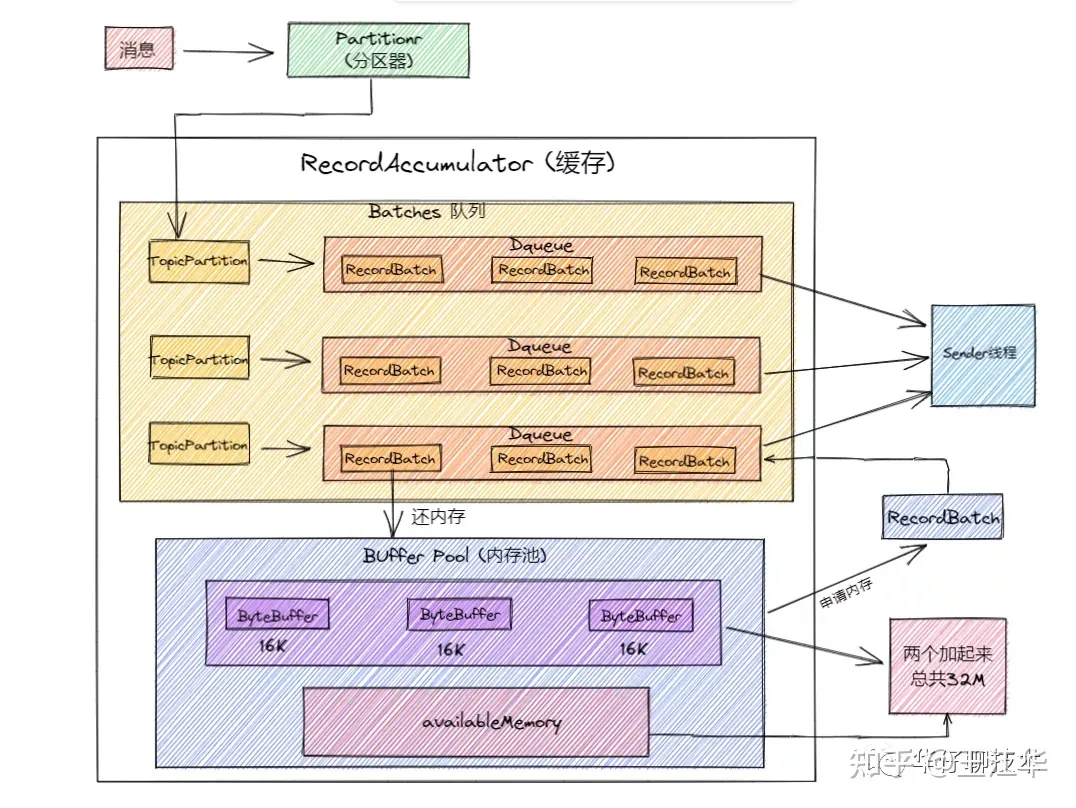
内存池, 可以将其类比为连接池(DB, Redis),主要是避免不必要的创建连接的开销, 这样内存池可以对 RecordBatch 做到反复利用, 防止引起Full GC问题。那我们看看 Kafka 内存池是怎么设计的:
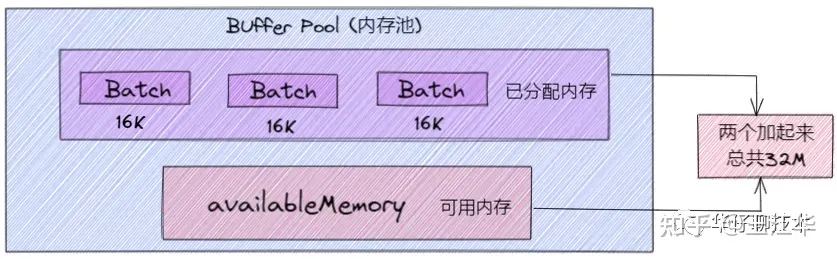
Kafka 内存设计有两部分,下面的粉色的是可用的内存(未分配的内存,初始的时候是 32M),上面紫色的是已经被分配了的内存,每个小 Batch 是 16K,然后这一个个的 Batch 就可以被反复利用,不需要每次都申请内存, 两部分加起来是 32M。
申请内存的过程
从上图 Producer 发送流程的第6步中可以看到会把消息放入 accumulator中, 即调用 accumulator.append() 追加, 然后把消息封装成一个个Batch 进行发送, 然后去申请内存(free.allocate())
(1)如果申请的内存大小超过了整个缓存池的大小,则抛异常出来
(2)对整个方法加锁:
this.lock.lock();
(3)如果申请的大小是每个 recordBatch 的大小(16K),并且已分配内存不为空,则直接取出来一个返回。
(4)如果整个内存池大小比要申请的内存大小大 (this.availableMemory + freeListSize >= size),则直接从可用内存(即上图粉色的区域)申请一块内存。并且可用内存要去掉申请的那一块内存。
还有其他一些条件判断 这里就不一 一赘述了, 后续会在源码篇章进行详细分析。
释放内存
释放内存的过程相对很简单了,如果释放的是一个批次的大小(16K),则直接加到已分配内存里面; 如果没有,则把内存放到可用内存里面,这部分内存等待虚拟机(JVM)垃圾回收。
这里大家可能会有个疑问即为什么释放了一个 Batch 大小(16K)内存的时候,才放到已分配内存里面。如果我想释放个 1M 的内存,为什么不能往已分配内存里面呢?
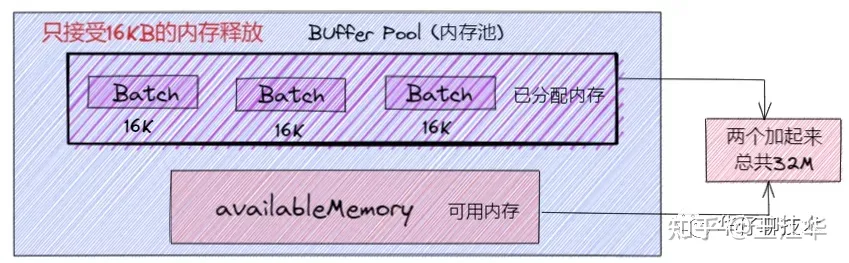
假设我们往已分配内存里释放了个 1M 的内存, 然后发送消息的时候是有条件限制的,要么是许多消息把 Batch 撑满了(16KB)发送出去,要么是一个 Batch 累积消息到一定的时间了,就会立马发出去。那么此时如果是一个 1M 的内存 Batch,才攒了几条消息,或者还不到1M, 等待时间到了,就把这个 1M 的内存批次发送出去了。这样内存的使用率是会非常低的。所以这里控制已分配内存必须是 16K 的,每个 Batch 的大小必须一致,这样才能充分利用内存空间。
磁盘存储设计
待KafkaRequestHandler处理完请求返回 Response的同时会将消息追加到磁盘, 这里会涉及到磁盘存储的部分, 可以先看下 <Kafka 三高架构设计> 中的顺序写磁盘和零拷贝部分。
1)、LoggerManager对象:这是日志管理器, 主要管理Log对象, 以及LogSegment日志分段对象。 2)、Log对象: 每个 replica 会对应一个 log 对象,log 对象是管理当前分区的一个单位,它会包含这个分区的所有 segment 文件(包括对应的 offset 索引和时间戳索引文件),它会提供一些增删查的方法。 3)、日志写入: 在 Log 中一个重要的方法就是日志的写入方法。Server 将每个分区的消息追加到日志中时,是以 segment 为单位的,当 segment 的大小到达阈值大小之后,会滚动新建一个日志分段(segment)保存新的消息,而分区的消息总是追加到最新的日志分段中。 4)、日志分段: 在 Log 的 append() 方法中,会调用 maybeRoll() 方法来判断是否需要进行相应日志分段操作, 如果需要会对日志进行分段存储。 5)、offset 索引文件: 在 Kafka 的索引文件中有这样的特点,主要采用绝对偏移量+相对偏移量 的方式进行存储的,每个 segment 最开始绝对偏移量也是其基准偏移量, 另外数据文件每隔一定的大小创建一个索引条目,而不是每条消息会创建索引条目,通过 index.interval.bytes 来配置,默认是 4096,也就是4KB。 6)、LogSegment 写入: 真正的日志写入,还是在 LogSegment 的 append() 方法中完成的,LogSegment 会跟 Kafka 最底层的文件通道、mmap 打交道, 利用OS Cache和零拷贝技术,基于磁盘顺序写的方式来进行落盘的, 即将数据追加到文件的末尾,实现高效存储。 7)、存储机制: 可以先看下 中的存储机制部分, 存储格式如上图所示。
Reference
- Kafka The definition Guide
- https://kafka.apache.org/documentation/
- https://zhuanlan.zhihu.com/p/459610418