定位性能瓶颈
查看操作系统负载
首先,当我们系统有问题的时候,我们不要急于去调查我们代码,这个毫无意义。我们首要需要看的是操作系统的报告。看看操作系统的CPU利用率,看看内存使用率,看看操作系统的IO,还有网络的IO,网络链接数,等等。Windows下的perfmon是一个很不错的工具,Linux下也有很多相关的命令和工具,比如:SystemTap,LatencyTOP,vmstat, sar, iostat, top, tcpdump等等 。通过观察这些数据,我们就可以知道我们的软件的性能基本上出在哪里。比如:
- 先看CPU利用率,如果CPU利用率不高,但是系统的Throughput和Latency上不去了,这说明我们的程序并没有忙于计算,而是忙于别的一些事,比如IO。(另外,CPU的利用率还要看内核态的和用户态的,内核态的一上去了,整个系统的性能就下来了。而对于多核CPU来说,CPU 0 是相当关键的,如果CPU 0的负载高,那么会影响其它核的性能,因为CPU各核间是需要有调度的,这靠CPU0完成)
- 然后,我们可以看一下IO大不大,IO和CPU一般是反着来的,CPU利用率高则IO不大,IO大则CPU就小。关于IO,我们要看三个事,一个是磁盘文件IO,一个是驱动程序的IO(如:网卡),一个是内存换页率。这三个事都会影响系统性能。
- 然后,查看一下网络带宽使用情况,在Linux下,你可以使用iftop, iptraf, ntop, tcpdump这些命令来查看。或是用Wireshark来查看。
- 如果CPU不高,IO不高,内存使用不高,网络带宽使用不高。但是系统的性能上不去。这说明你的程序有问题,比如,你的程序被阻塞了。可能是因为等那个锁,可能是因为等某个资源,或者是在切换上下文。
通过了解操作系统的性能,我们才知道性能的问题,比如:带宽不够,内存不够,TCP缓冲区不够,等等,很多时候,不需要调整程序的,只需要调整一下硬件或操作系统的配置就可以了。
使用Profiler测试
接下来,我们需要使用性能检测工具,也就是使用某个Profiler来差看一下我们程序的运行性能。如:Java的JProfiler/TPTP/CodePro Profiler,GNU的gprof,IBM的PurifyPlus,Intel的VTune,AMD的CodeAnalyst,还有Linux下的OProfile/perf,后面两个可以让你对你的代码优化到CPU的微指令级别,如果你关心CPU的L1/L2的缓存调优,那么你需要考虑一下使用VTune。 使用这些Profiler工具,可以让你程序中各个模块函数甚至指令的很多东西,如:运行的时间 ,调用的次数,CPU的利用率,等等。这些东西对我们来说非常有用。
我们重点观察运行时间最多,调用次数最多的那些函数和指令。这里注意一下,对于调用次数多但是时间很短的函数,你可能只需要轻微优化一下,你的性能就上去了(比如:某函数一秒种被调用100万次,你想想如果你让这个函数提高0.01毫秒的时间 ,这会给你带来多大的性能)
使用Profiler有个问题我们需要注意一下,因为Profiler会让你的程序运行的性能变低,像PurifyPlus这样的工具会在你的代码中插入很多代码,会导致你的程序运行效率变低,从而没发测试出在高吞吐量下的系统的性能,对此,一般有两个方法来定位系统瓶颈:
1)在你的代码中自己做统计,使用微秒级的计时器和函数调用计算器,每隔10秒把统计log到文件中。
2)分段注释你的代码块,让一些函数空转,做Hard Code的Mock,然后再测试一下系统的Throughput和Latency是否有质的变化,如果有,那么被注释的函数就是性能瓶颈,再在这个函数体内注释代码,直到找到最耗性能的语句。
最后再说一点,对于性能测试,不同的Throughput会出现不同的测试结果,不同的测试数据也会有不同的测试结果。所以,用于性能测试的数据非常重要,性能测试中,我们需要观测试不同Throughput的结果。
监测工具
sar - 找出系统瓶颈的利器
sar是System Activity Reporter(系统活动情况报告)的缩写。sar工具将对系统当前的状态进行取样,然后通过计算数据和比例来表达系统的当前运行状态。它的特点是可以连续对系统取样,获得大量的取样数据;取样数据和分析的结果都可以存入文件,所需的负载很小。sar是目前Linux上最为全面的系统性能分析工具之一,可以从14个大方面对系统的活动进行报告,包括文件的读写情况、系统调用的使用情况、串口、CPU效率、内存使用状况、进程活动及IPC有关的活动等,使用也是较为复杂。
sar是查看操作系统报告指标的各种工具中,最为普遍和方便的;它有两种用法;
- 追溯过去的统计数据(默认)
- 周期性的查看当前数据
查看 CPU 使用
如果CPU利用率不高,但是系统的Throughput和Latency上不去了,这说明我们的程序并没有忙于计算,而是忙于别的一些事,比如IO。(另外,CPU的利用率还要看内核态的和用户态的,内核态的一上去了,整个系统的性能就下来了。而对于多核CPU来说,CPU 0 是相当关键的,如果CPU 0的负载高,那么会影响其它核的性能,因为CPU各核间是需要有调度的,这靠CPU0完成)
top
$ top
查看已经被使用的内存比例、暂用内存较多的进程。
iostat -C
$ iostat -c 1
Linux xx-generic (xx.com) 11/22/20 _x86_64_ (48 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
8.17 0.00 0.88 0.01 0.00 90.94
avg-cpu: %user %nice %system %iowait %steal %idle
2.99 0.00 1.24 0.00 0.00 95.77
avg-cpu: %user %nice %system %iowait %steal %idle
5.75 0.00 1.00 0.00 0.00 93.25
sar
sar -u
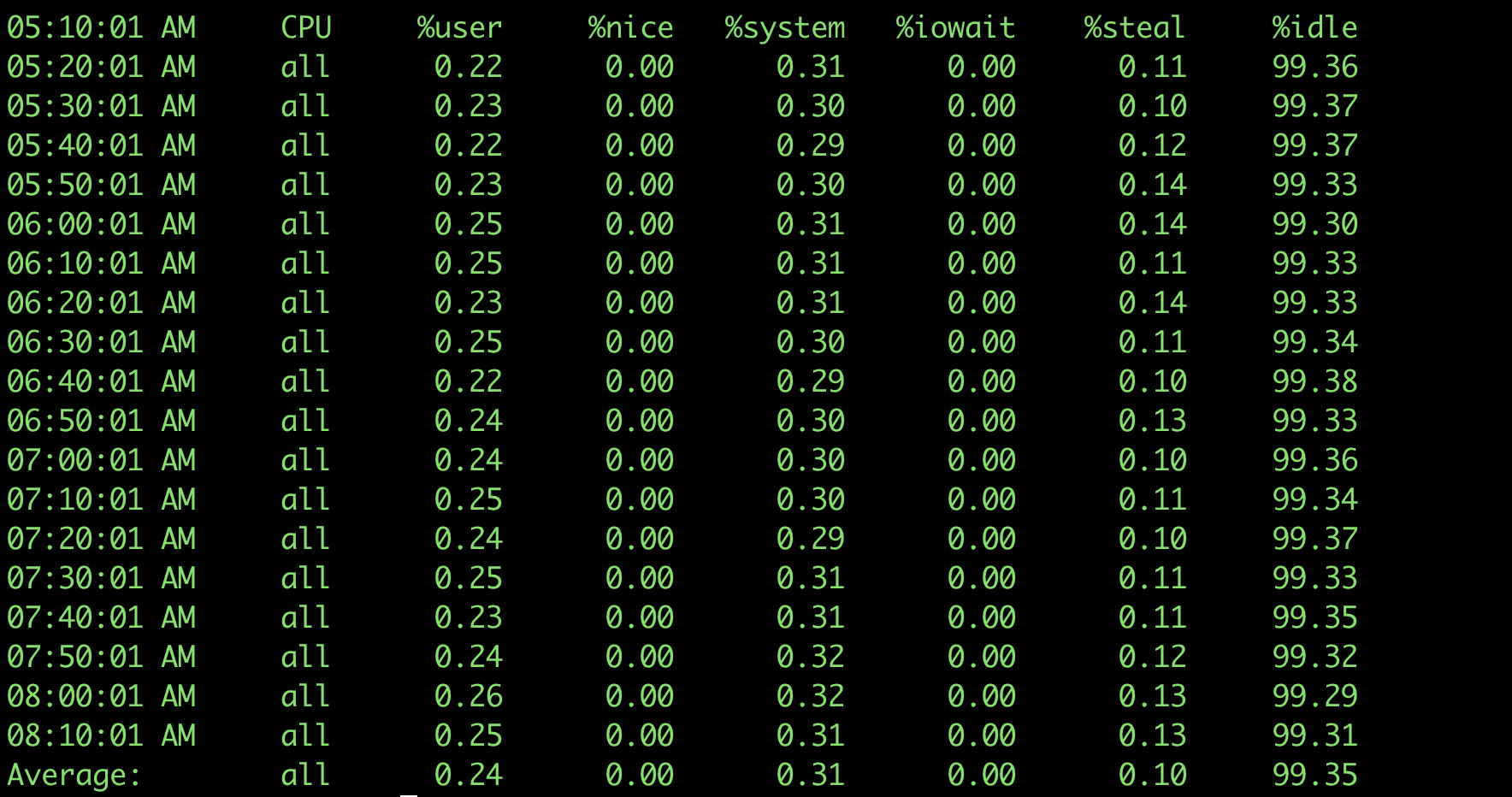
可以看到这台机器使用了虚拟化技术,有相应的时间消耗; 各列的指标分别是:
- %user 用户模式下消耗的CPU时间的比例;
- %nice 通过nice改变了进程调度优先级的进程,在用户模式下消耗的CPU时间的比例
- %system 系统模式下消耗的CPU时间的比例;
- %iowait CPU等待磁盘I/O导致空闲状态消耗的时间比例;
- %steal 利用Xen等操作系统虚拟化技术,等待其它虚拟CPU计算占用的时间比例;
- %idle CPU空闲时间比例;
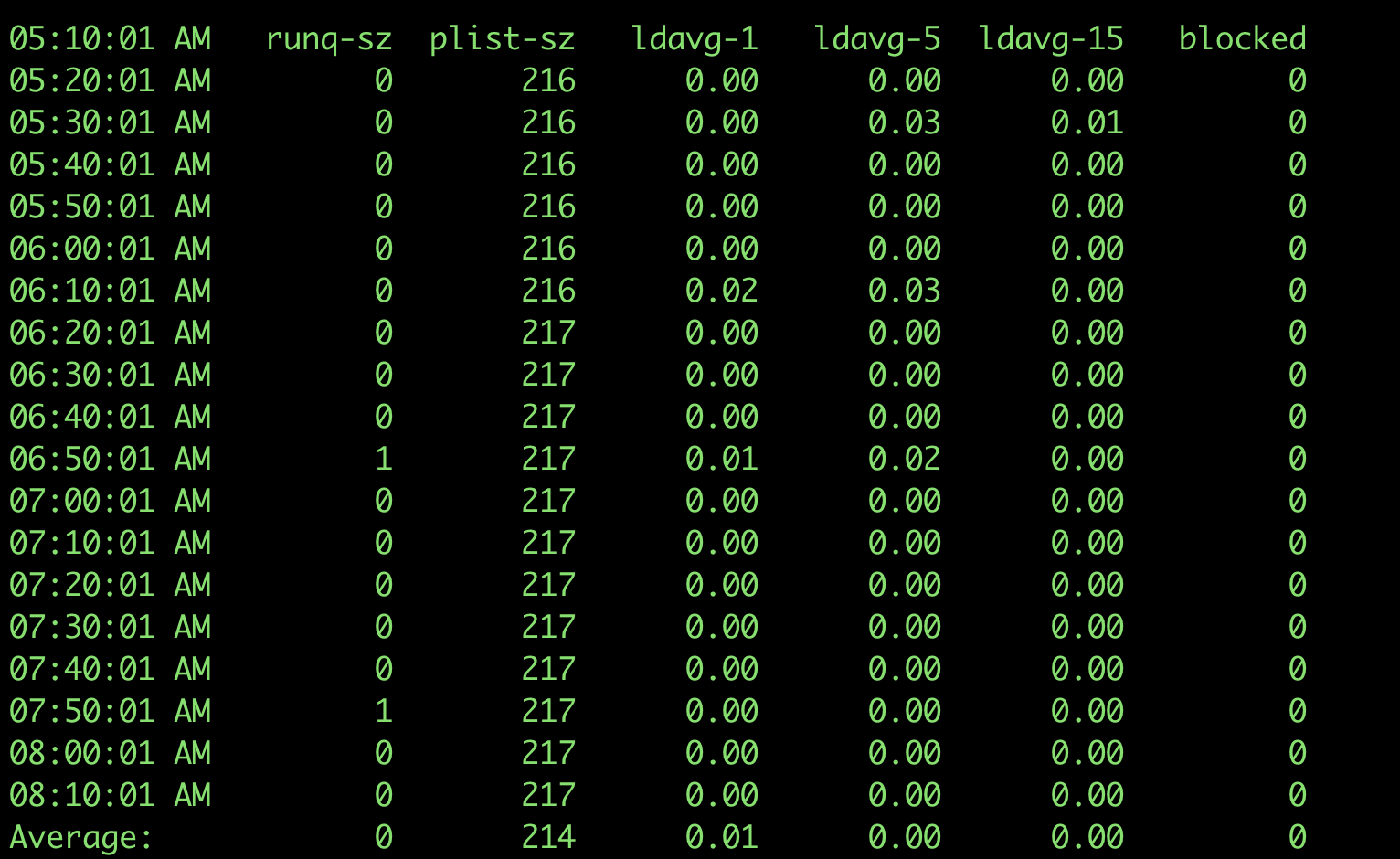
查看进程负载 - sar -q
sar -q: 查看平均负载,即查看运行队列中的进程数、系统上的进程大小、平均负载等;与其它命令相比,它能查看各项指标随时间变化的情况;
- runq-sz:运行队列的长度(等待运行的进程数)
- plist-sz:进程列表中进程(processes)和线程(threads)的数量
- ldavg-1:最后1分钟的系统平均负载 ldavg-5:过去5分钟的系统平均负载
- ldavg-15:过去15分钟的系统平均负载
Memory
Refer to https://swsmile.info/post/linux-performance-memory/
I/O
Refer to https://swsmile.info/post/linux-performance-io/.
Reference
- https://www.opsdash.com/blog/disk-monitoring-linux.html
- https://linuxtools-rst.readthedocs.io/zh_CN/latest/tool/sar.html
- https://linuxtools-rst.readthedocs.io/zh_CN/latest/tool/iostat.html
- https://linuxtools-rst.readthedocs.io/zh_CN/latest/tool/vmstat.html
- https://www.infoq.cn/article/linux-networking-performance-analytics
- Big List Of 20 Common Bottlenecks- http://highscalability.com/blog/2012/5/16/big-list-of-20-common-bottlenecks.html
- https://coolshell.cn/articles/7490.html
- https://coolshell.cn/articles/17381.html