Demo
# Create a 10G big file
$ fallocate -l 10G 10g_file.img
$ mkdir sw_test
$ time cp 10g_file.img sw_test/
cp 10g_file.img sw_test/ 0.08s user 8.18s system 97% cpu 8.459 total
$ du -h 10g_file.img
11G 10g_file.img
$ du -h sw_test
11G sw_test
$ stat 10g_file.img
File: 10g_file.img
Size: 10737418240 Blocks: 20971528 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 524359 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ sw) Gid: ( 1000/ sw)
Access: 2021-10-20 00:05:29.925335381 +0800
Modify: 2021-10-20 00:04:17.067027796 +0800
Change: 2021-10-20 00:04:17.067027796 +0800
Birth: -
$ stat sw_test/10g_file.img
File: sw_test/10g_file.img
Size: 10737418240 Blocks: 20971528 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 2228230 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ sw) Gid: ( 1000/ sw)
Access: 2021-10-20 00:05:29.925335381 +0800
Modify: 2021-10-20 00:05:58.946511217 +0800
Change: 2021-10-20 00:05:58.946511217 +0800
现实的存取场景
例如你到火车站使用寄存服务:
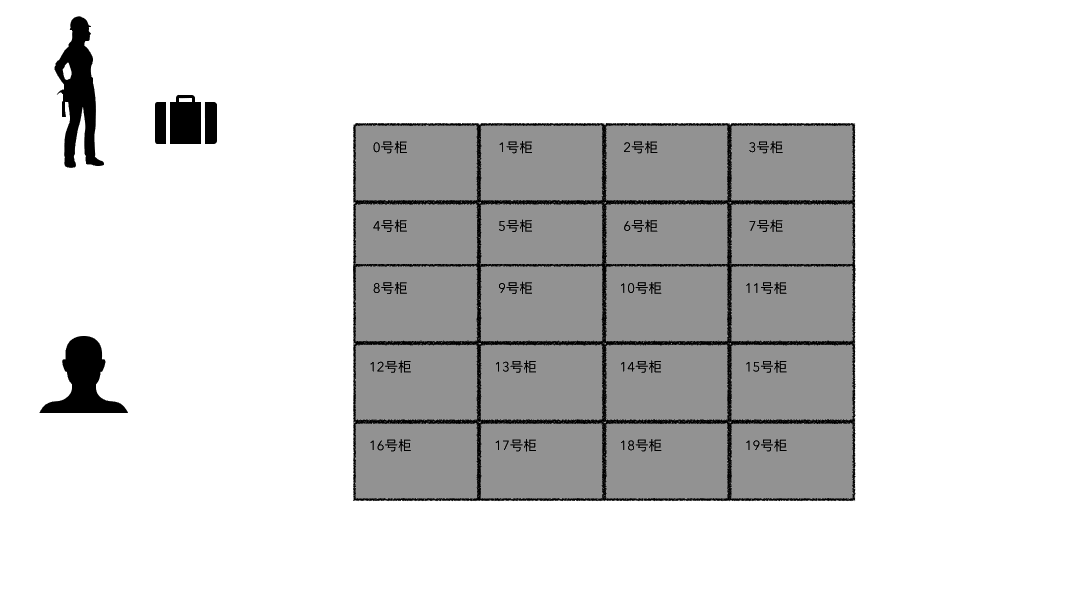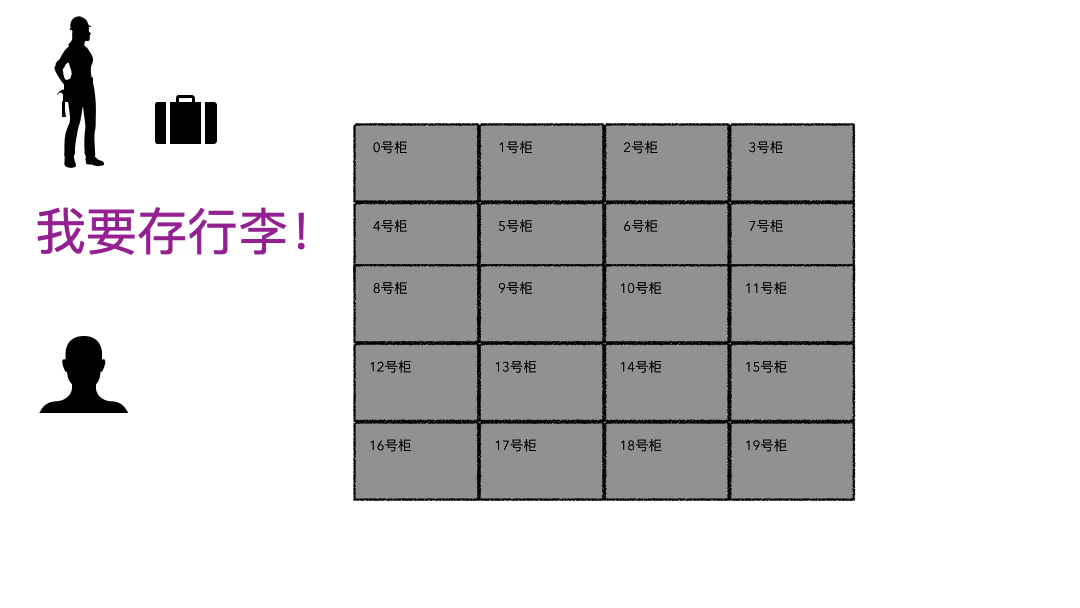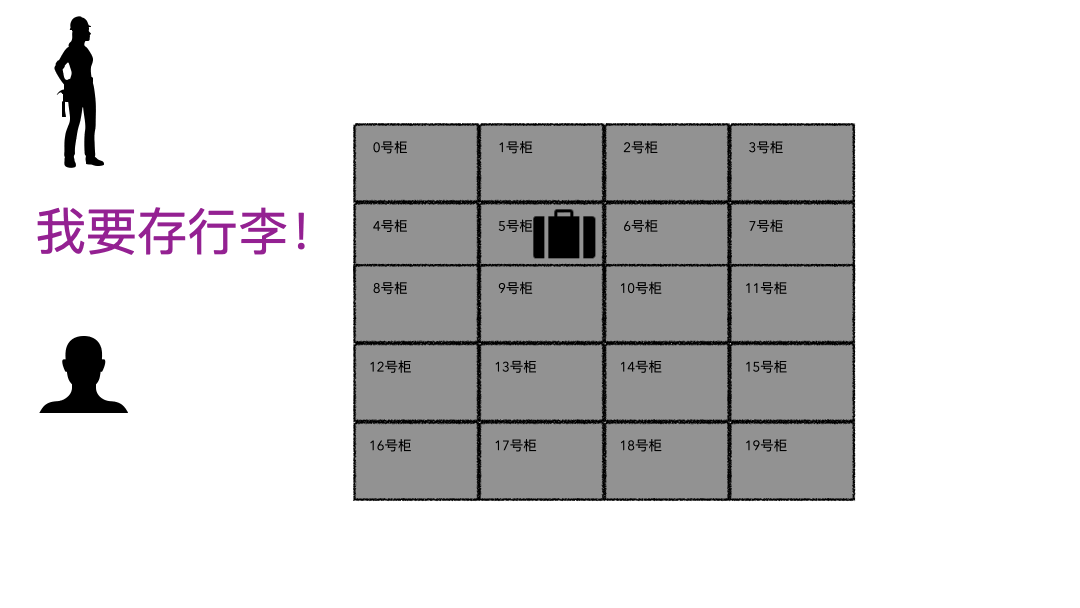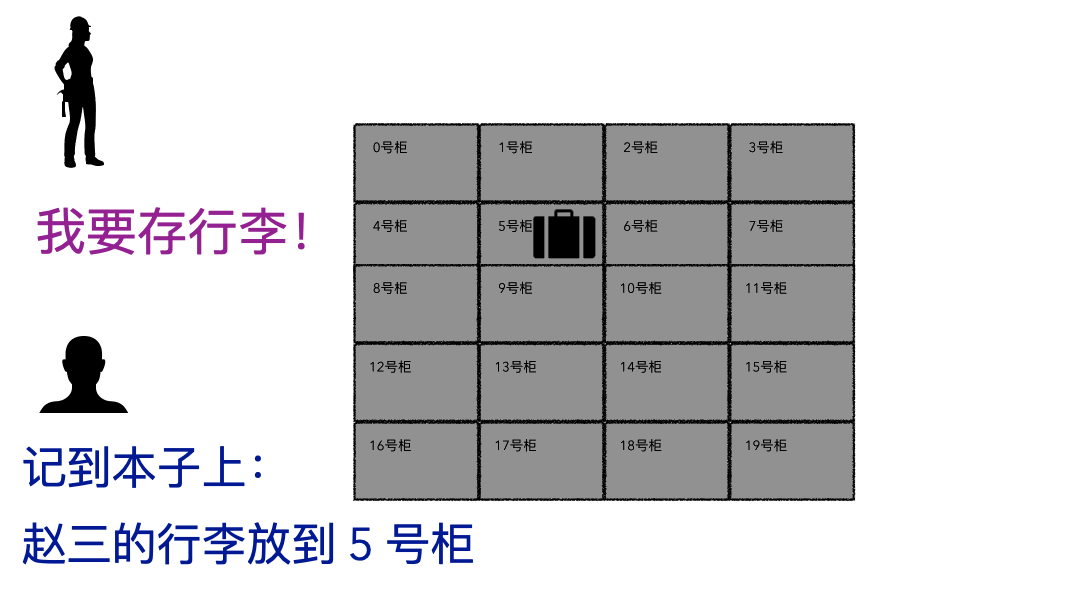
存行李的时候,是不是要登记一些个人信息?对吧,至少自己名字要写上。可能还会给你一个牌子,让你挂手上,这个东西就是为了标示每一个唯一的行李。
取行李的时候,要报自己名字,有牌子的给他牌子,然后工作人员才能去特定的位置找到你的行李
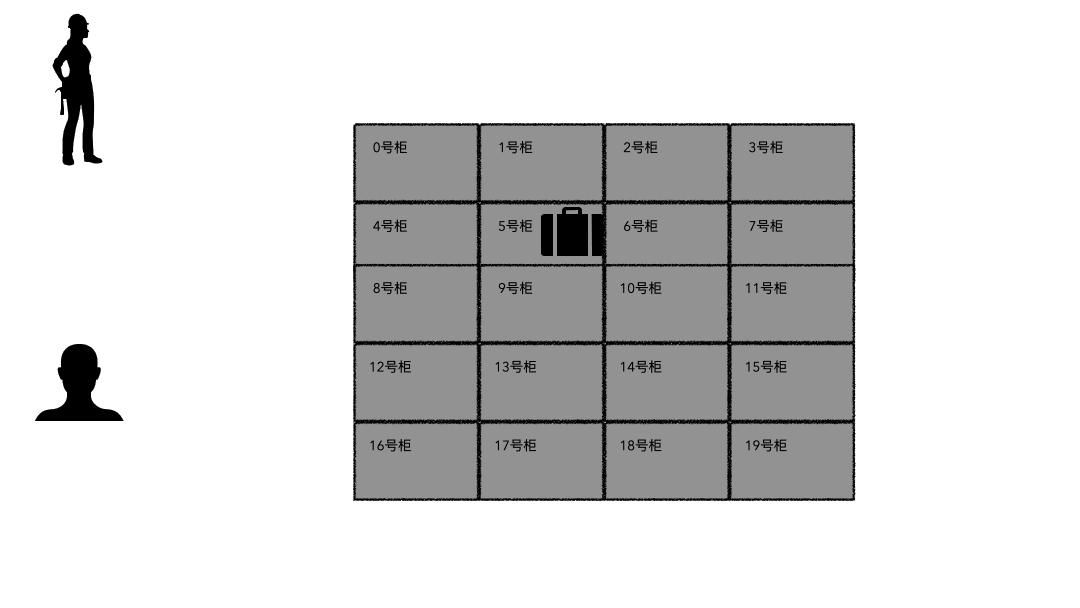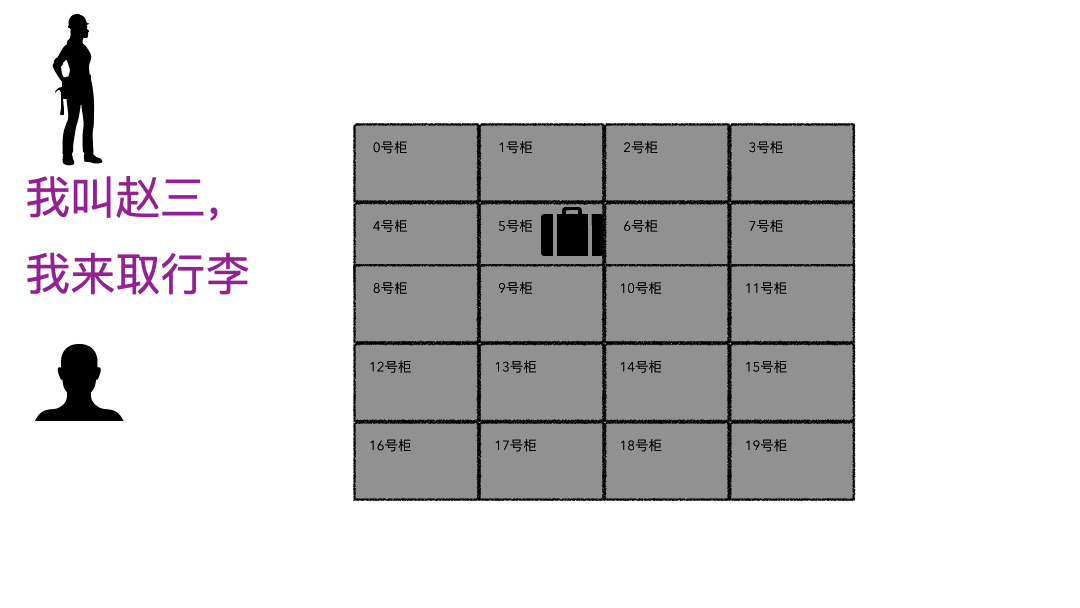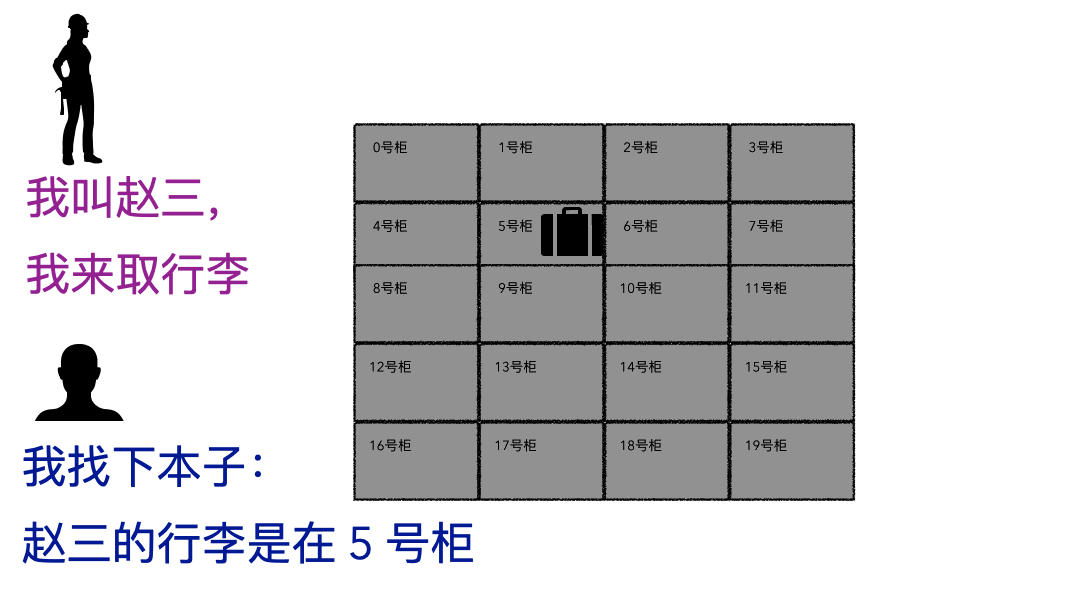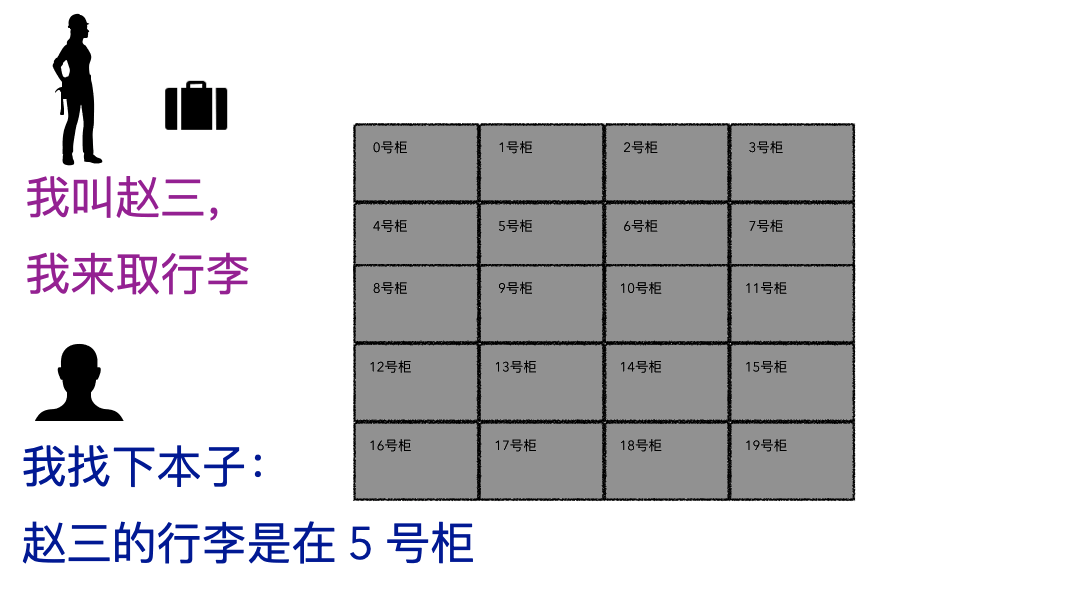
划重点:存的时候必须记录一些关键信息(记录ID、给身份牌),取的时候才能正确定位到。
文件系统
回到我们的文件系统,对比上面的行李存取行为,可以做个简单的类比;
- 登记名字就是在文件系统记录文件名;
- 生成的牌子就是元数据索引;
- 你的行李就是文件;
- 寄存室就是磁盘(容纳东西的物理空间);
- 管理员整套运行机制就是文件系统;
上面的对应并不是非常严谨,仅仅是帮助大家理解文件系统而已,让大家知道其实文件系统是非常朴实的一个东西,思想都来源于生活。
空间管理
现在思考文件系统是怎么管理空间的?
如果,一个连续的大磁盘空间给你使用,你会怎么使用这段空间呢?
直观的一个想法,我把进来的数据就完整的放进去。

这种方式非常容易实现,属于眼前最简单,以后最麻烦的方式。因为会造成很多空洞,明明还有很多空间位置,但是由于整个太大,形状不合适(数据大小),哪里都放不下。因为你要放一个完整的空间。
怎么改进?有人会想,既然整个放不进去,那就剁碎了呗。这里塞一点,那里塞一点,就塞进去了。
对,思路完全正确。改进的方式就是切分,把空间按照一定粒度切分。每个小粒度的物理块命名为 Block,每个 Block 一般是 4K 大小,用户数据存到文件系统里来自然也是要切分,存储到磁盘上各个角落。
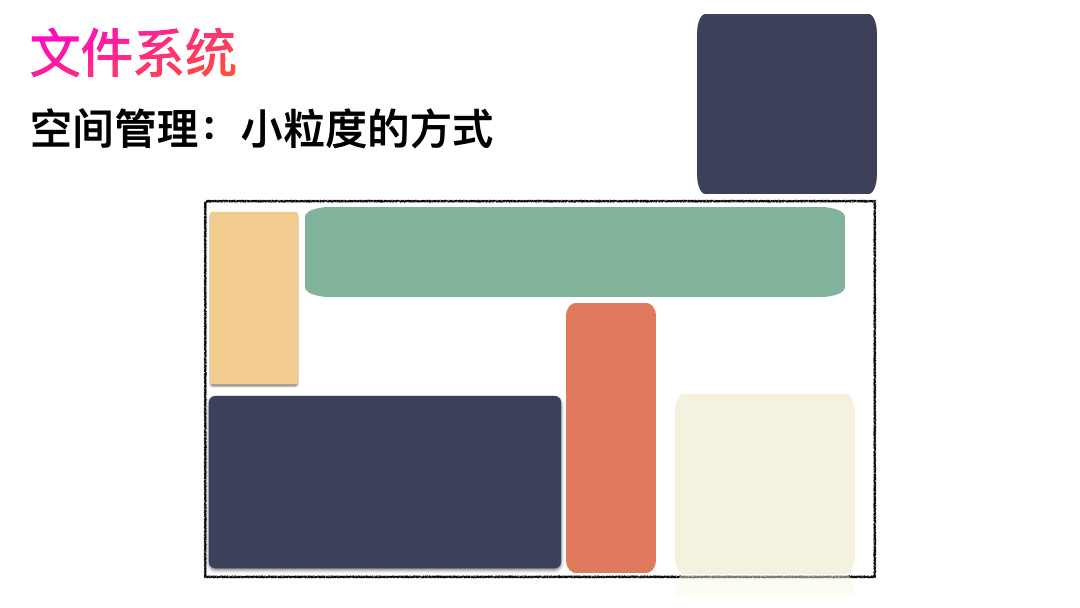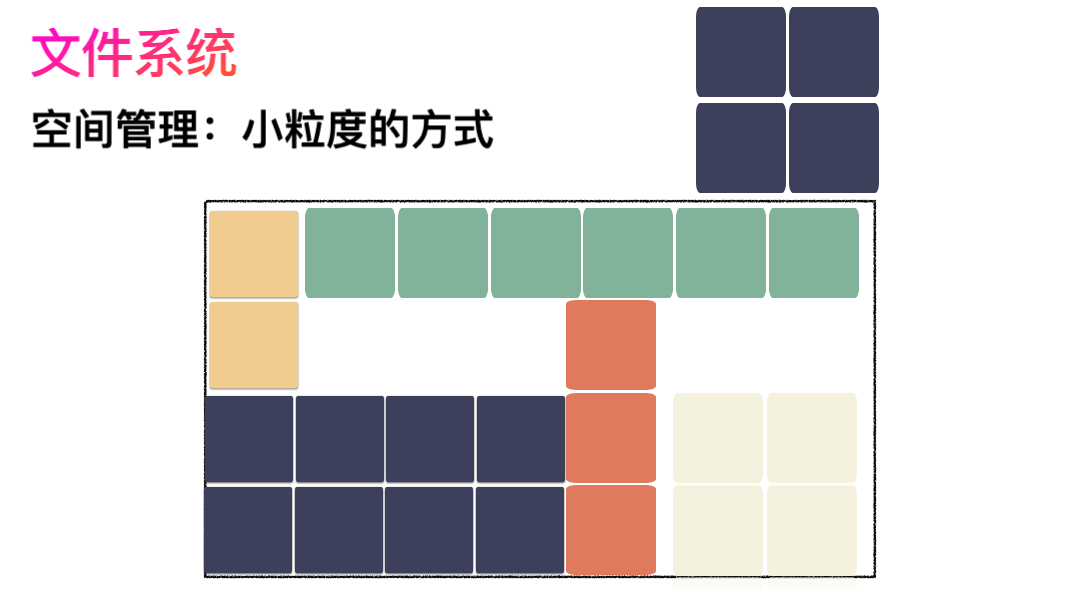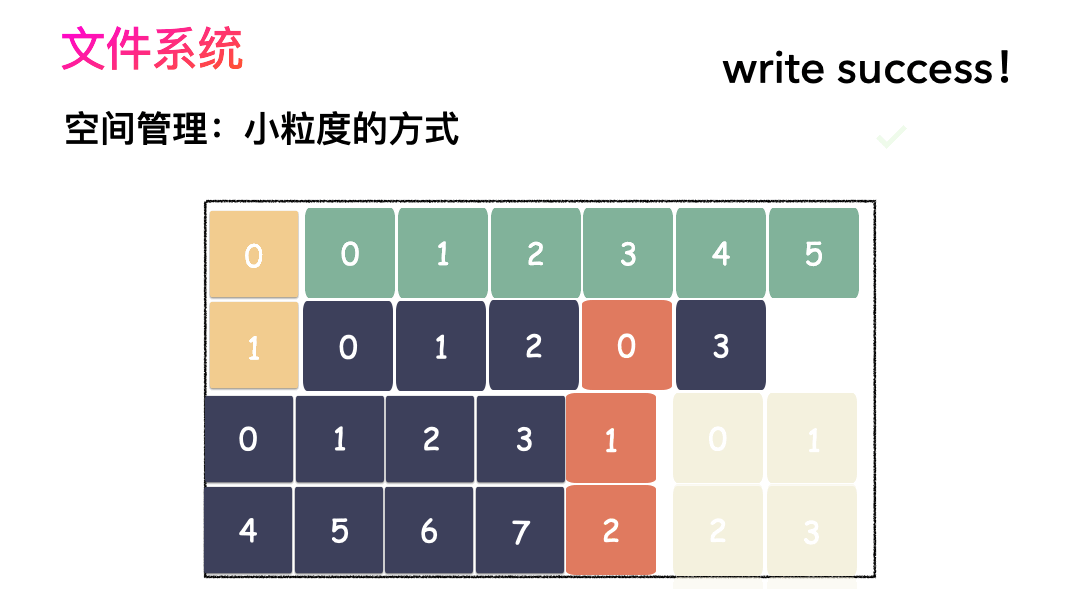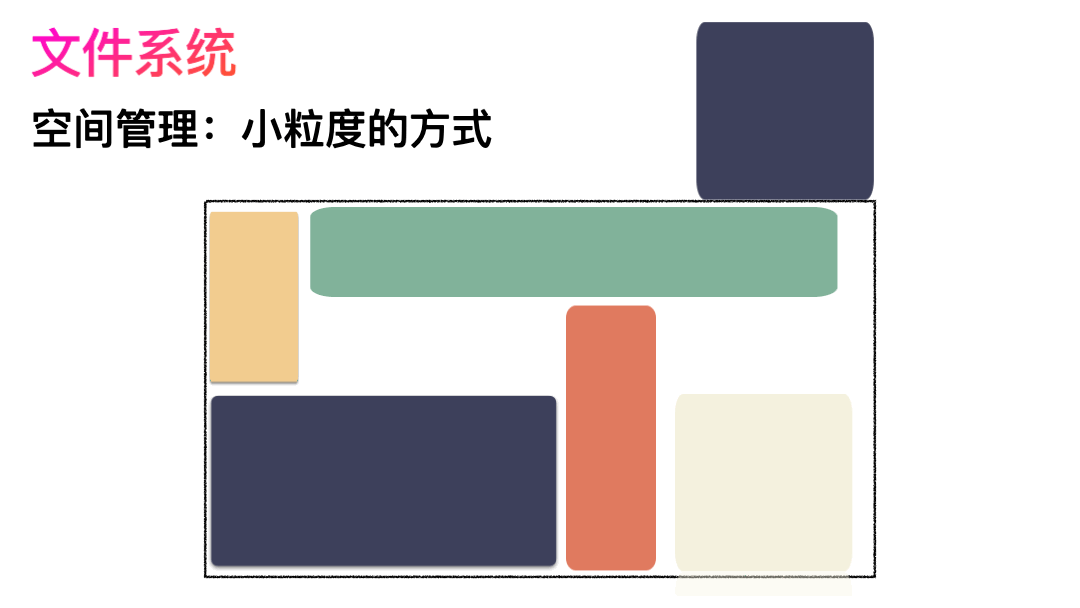
图示标号表示这个完整对象的 Block 的序号,用来复原对象用的。
随之而来又有一个问题:你光会切成块还不行,取文件数据的时候,还得把它们给组合起来才行。
所以,要有一个表记录文件对应所有 Block 的位置,这个表被文件系统称为inode。
写文件的流程是这样的:
- 先写数据:数据先按照 Block 粒度存储到磁盘的各个位置;
- 再写元数据:然后把 Block 所在的各个位置保存起来,即inode(我用一本书来表示);
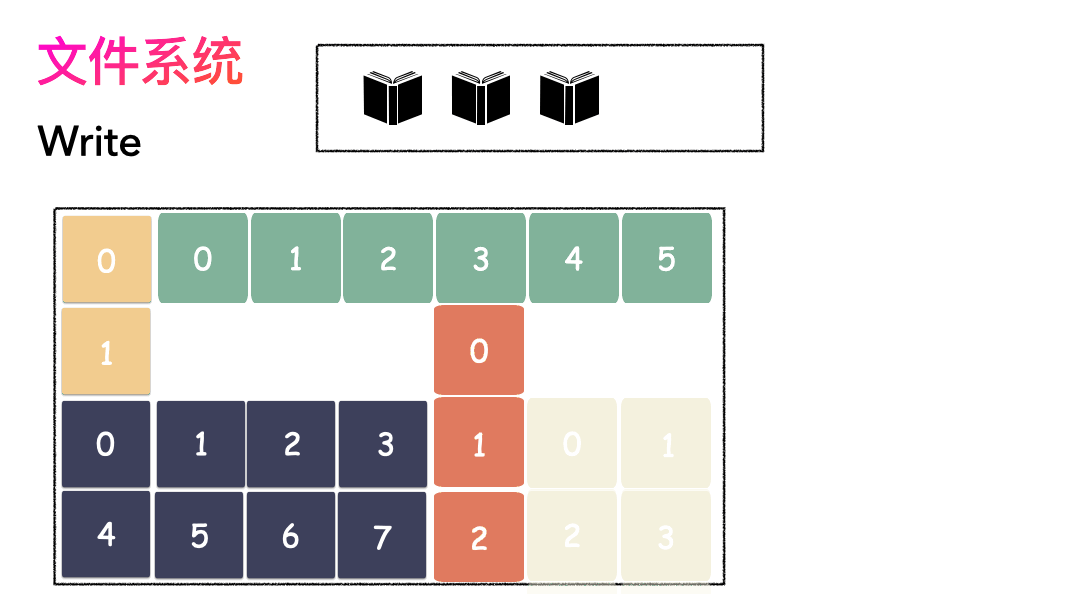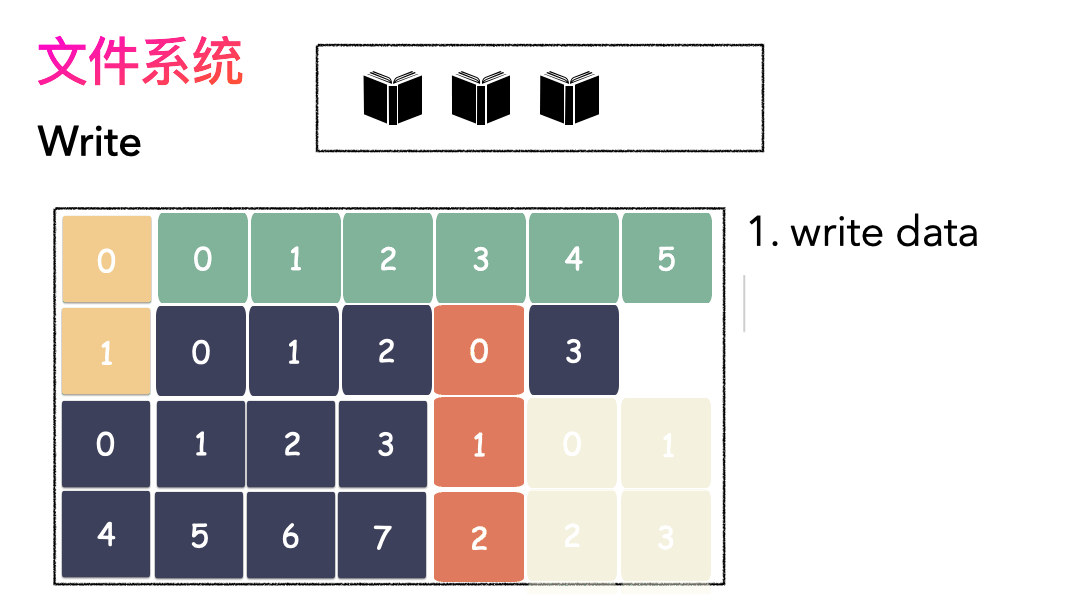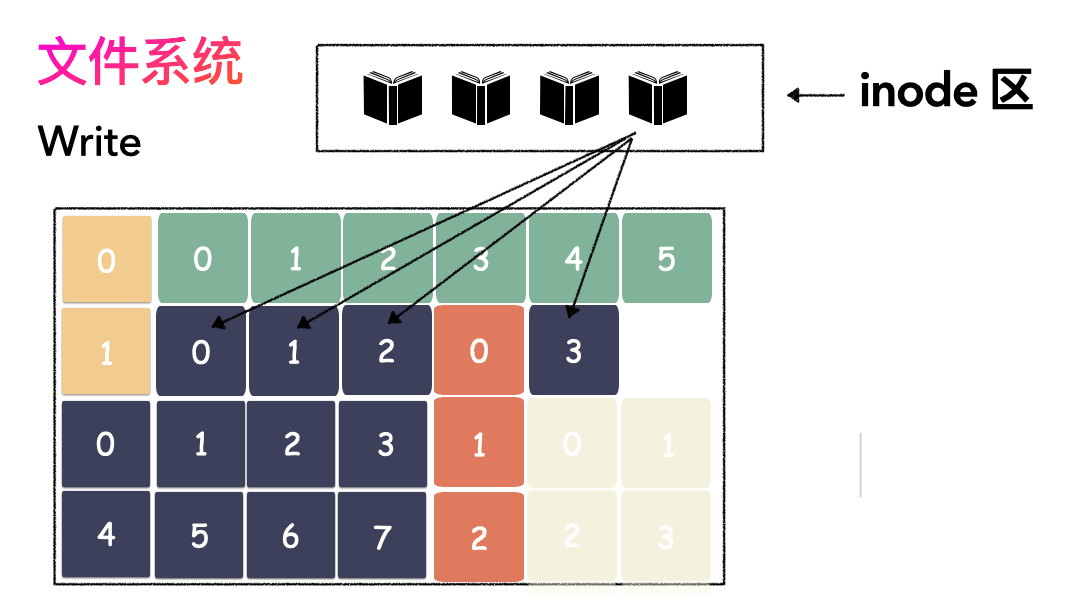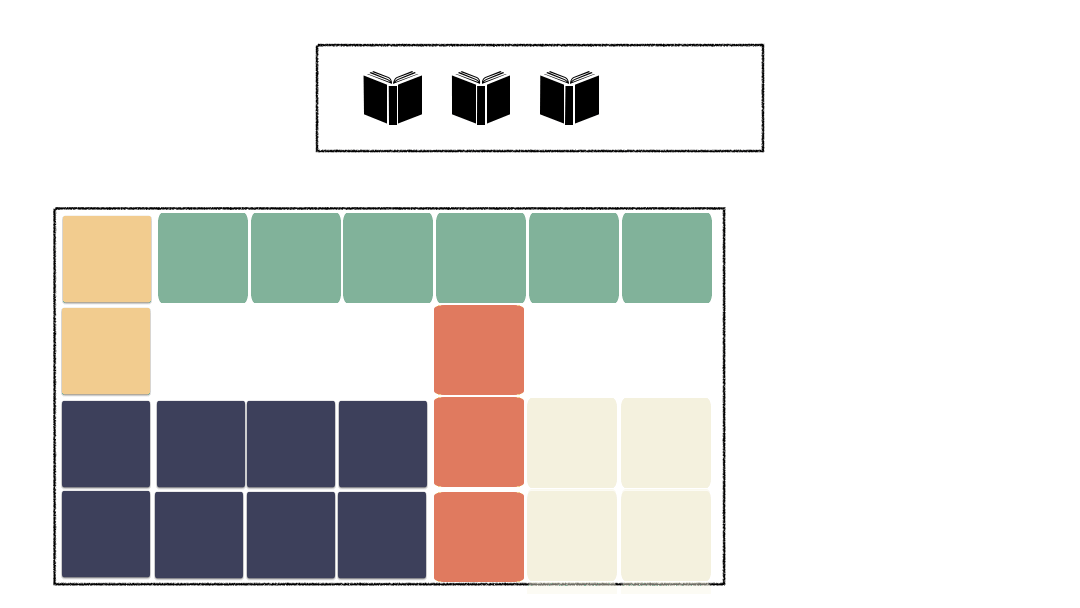
读文件流程则是:
- 先读inode,找到各个 Block 的位置;
- 然后读数据,构造一个完整的文件,给到用户;
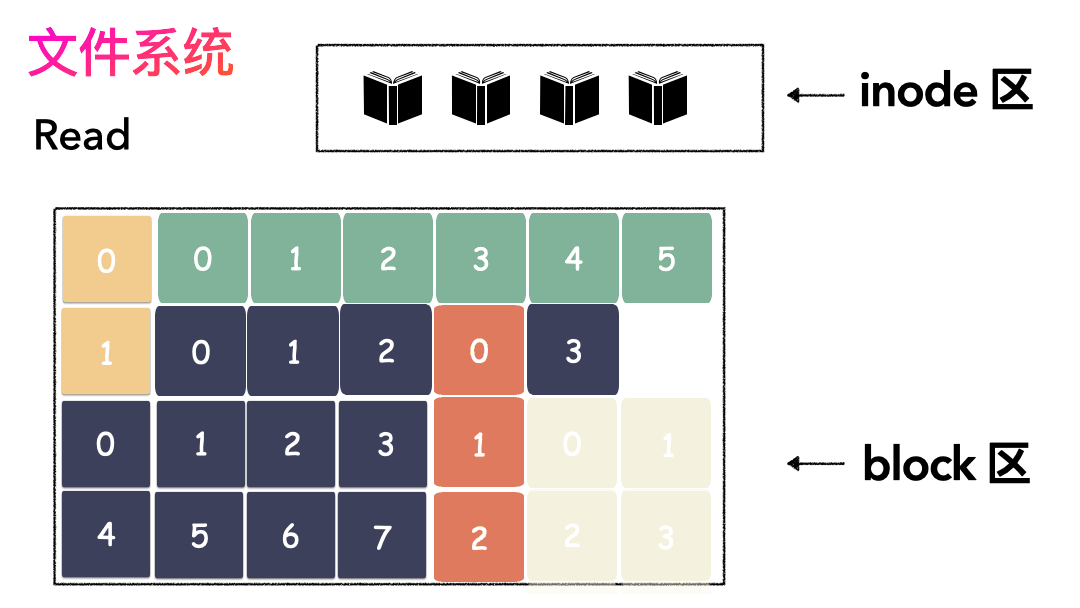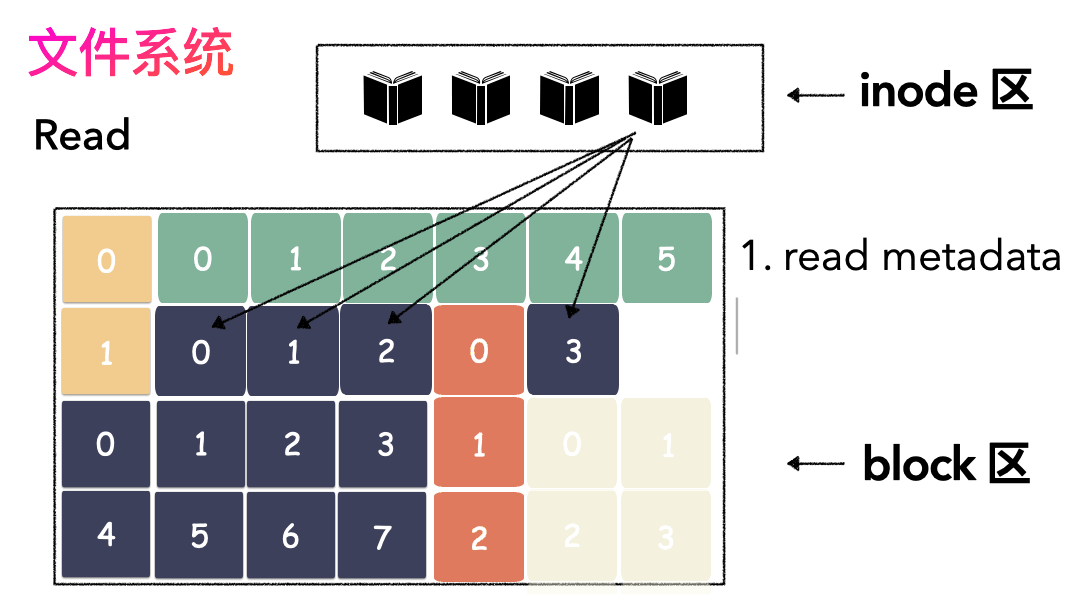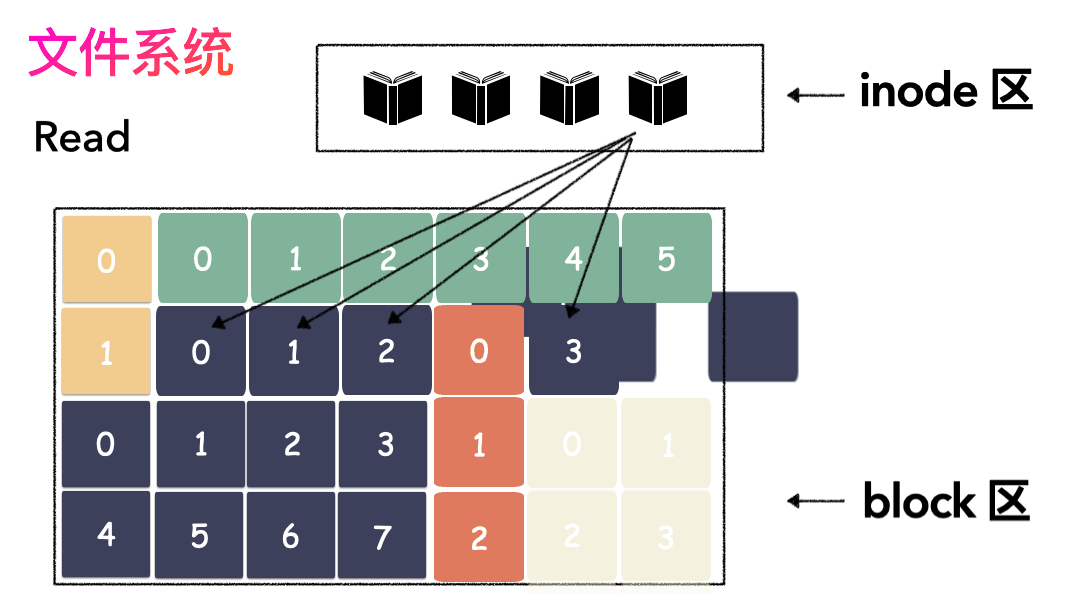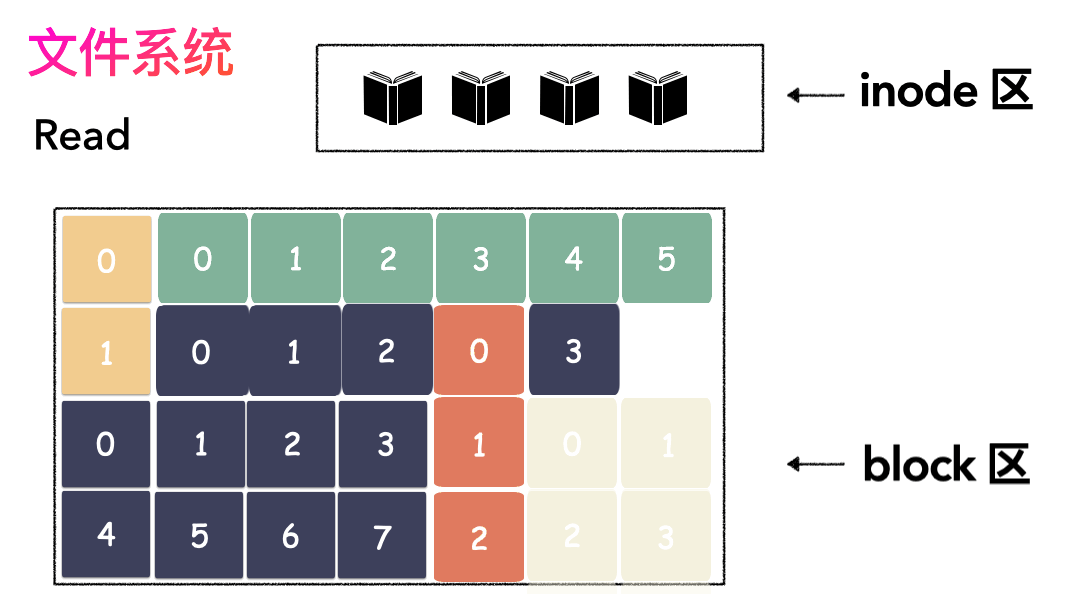
inode/block 概念
好,我们现在来看看inode,直观地感受一下:
这个inode有文件元数据和Block数组(长度是15),数组中前两项指向Block 3和Block 101,表示数据在这两个块中存着。
你肯定会意识到:Block数组只有15个元素,每个Block是4K, 难道一个文件最大只能是 15 * 4K = 60 K ?
这是绝对不行的!
最简单的办法就是:把这个Block数组长度给扩大!
比如我们想让文件系统最大支持100G的文件,Block数组需要这么长:
(10010241024)/4 = 26214400
Block数组中每一项是4个字节,那就需要(26214400*4)/1024/1024 = 100M
为了支持100G的文件,我们的Block数组本身就得100M !
并且对每个文件都是如此 !即使这个文件只有1K! 这将是巨大浪费!
肯定不能这么干,解决方案就是间接索引,按照约定,把这 15 个槽位分作 4 个不同类别来用:
- 前 12 个槽位(也就是 0 - 11 )我们成为直接索引;
- 第 13 个位置,我们称为 1 级索引;
- 第 14 个位置,我们称为 2 级索引;
- 第 15 个位置,我们称为 3 级索引;
直接索引:能存 12 个 block 编号,每个 block 4K,就是 48K,也就是说,48K 以内的文件,前 12 个槽位存储编号就能完全 hold 住。
一级索引:
也就是说这里存储的编号指向的 block 里面存储的也是 block 编号,里面的编号指向用户数据。一个 block 4K,每个元素 4 字节,也就是有 1024 个编号位置可以存储。
所以,一级索引能寻址 4M(1024 * 4K)空间 。
二级索引:
二级索引是在一级索引的基础上多了一级而已,换算下来,有了 4M 的空间用来存储用户数据的编号。所以二级索引能寻址 4G (4M/4 * 4K) 的空间。
三级索引:
三级索引是在二级索引的基础上又多了一级,也就是说,有了 4G 的空间来存储用户数据的 block 编号。所以二级索引能寻址 4T (4G/4 * 4K) 的空间。
所以,在这种文件系统(如ext2)上,通过这种间接块索引的方式,最大能支撑的文件大小 = 48K + 4M + 4G + 4T ,约等于 4 T。
这种多级索引寻址性能表现怎么样?
在不超过 12 个数据块的小文件的寻址是最快的,访问文件中的任意数据理论只需要两次读盘,一次读 inode,一次读数据块。
访问大文件中的数据则需要最多五次读盘操作:inode、一级间接寻址块、二级间接寻址块、三级间接寻址块、数据块。
为什么cp那么快?
接下来我们要写入一个奇怪的文件,这个文件很大,但是真正的数据只有8K:
在[0,4K]这位置有4K的数据
在[1T , 1T+4K] 处也有4K数据
中间没有数据,这样的文件该如何写入硬盘?
- 创建一个文件,这个时候分配一个 inode;
- 在 [ 0,4K ] 的位置写入 4K 数据,这个时候只需要 一个 block,把这个编号写到
block[0]这个位置保存起来; - 在 [ 1T,1T+4K ] 的位置写入 4K 数据,这个时候需要分配一个 block,因为这个位置已经落到三级索引才能表现的空间了,所以需要还需要分配出 3 个索引块;
- 写入完成,close 文件;
实际存储如图:
这个时候,我们的文件看起来是超大文件,size 等于 1T+4K ,但里面实际的数据只有 8 K,位置分别是 [ 0,4K ] ,[ 1T,1T+4K ]。
由于没写数据的地方不用分配物理block块,所以实际占用的物理空间只有8K。
重点:文件 size 只是 inode 里面的一个属性,实际物理空间占用则是要看用户数据放了多少个 block ,没写数据的地方不用分配物理block块。
这样的文件其实就是稀疏文件, 它的逻辑大小和实际物理空间是不相等的。
所以当我们用cp命令去复制一个这样的文件时,那肯定迅速就完成了。
Inode
Inode Metadata
To see the inode number of a file, we can use ls with the -i (inode) option:
$4 ls -i linux-amd64-1.1.0.tar.gz
524310 linux-amd64-1.1.0.tar.gz
$ stat linux-amd64-1.1.0.tar.gz
File: linux-amd64-1.1.0.tar.gz
Size: 1241295 Blocks: 2432 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 524310 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ sw) Gid: ( 1000/ sw)
Access: 2021-10-19 23:57:10.665816888 +0800
Modify: 2017-05-21 23:11:39.000000000 +0800
Change: 2021-10-19 23:57:05.149126971 +0800
The inode number for this file is 1441801, so this inode holds the metadata for this file and, traditionally, the pointers to the disk blocks where the file resides on the hard drive. If the file is fragmented, very large, or both, some of the blocks the inode points to might hold further pointers to other disk blocks. And some of those other disk blocks might also hold pointers to another set of disk blocks. This overcomes the problem of the inode being a fixed size and able to hold a finite number of pointers to disk blocks.
debugfs
$ ls -i 10g_file.img
524359 10g_file.img
$ sudo debugfs -R "stat <524359>" /dev/mapper/ubuntu--vg-ubuntu--lv
Inode: 524359 Type: regular Mode: 0664 Flags: 0x80000
Generation: 3755623796 Version: 0x00000000:00000001
User: 1000 Group: 1000 Project: 0 Size: 10737418240
File ACL: 0
Links: 1 Blockcount: 20971528
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x616eec81:0ffb0d50 -- Wed Oct 20 00:04:17 2021
atime: 0x616eecc9:dc9dfd54 -- Wed Oct 20 00:05:29 2021
mtime: 0x616eec81:0ffb0d50 -- Wed Oct 20 00:04:17 2021
crtime: 0x616eec81:0f072cac -- Wed Oct 20 00:04:17 2021
Size of extra inode fields: 32
Inode checksum: 0xd3aea088
EXTENTS:
(ETB0):2177328, (0-30719[u]):9732096-9762815, (30720-61439[u]):9762816-9793535, (61440-92159[u]):9793536-9824255, (92160-122879[u]):9824256-9854975, ...
We’re shown the following information:
- Inode: The number of the inode we’re looking at.
- Type: This is a regular file, not a directory or symbolic link.
- Mode: The file permissions in octal.
- Flags: Indicators that represent different features or functionality. The 0x80000 is the “extents” flag (more on this below).
- Generation: A Network File System (NFS) uses this when someone accesses remote file systems over a network connection as though they were mounted on the local machine. The inode and generation numbers are used as a form of file handle.
- Version: The inode version.
- User: The owner of the file.
- Group: The group owner of the file.
- Project: Should always be zero.
- Size: The size of the file.
- File ACL: The file access control list. These were designed to allow you to give controlled access to people who aren’t in the owner group.
- Links: The number of hard links to the file.
- Blockcount: The amount of hard drive space allocated to this file, given in 512-byte chunks. Our file has been allocated eight of these, which is 4,096 bytes. So, our 98-byte file sits within a single 4,096-byte disk block.
- Fragment: This file is not fragmented. (This is an obsolete flag.)
- Ctime: The time at which the file was created.
- Atime: The time at which this file was last accessed.
- Mtime: The time at which this file was last modified.
- Crtime: The time at which the file was created.
- Size of extra inode fields: The ext4 file system introduced the ability to allocate a larger on-disk inode at format time. This value is the number of extra bytes the inode is using. This extra space can also be used to accommodate future requirements for new kernels or to store extended attributes.
- Inode checksum: A checksum for this inode, which makes it possible to detect if the inode is corrupted.
- Extents: If extents are being used (on ext4, they are, by default), the metadata regarding the disk block usage of files has two numbers that indicate the start and end blocks of each portion of a fragmented file. This is more efficient than storing every disk block taken up by each portion of a file. We have one extent because our small file sits in one disk block at this block offset.
Reference
- https://en.wikipedia.org/wiki/Inode
- https://man7.org/linux/man-pages/man7/inode.7.html
- https://stackoverflow.com/questions/257844/quickly-create-a-large-file-on-a-linux-system
- https://mp.weixin.qq.com/s/NPJnXjXXXv0w_AYe-FQlDg
- https://www.howtogeek.com/465350/everything-you-ever-wanted-to-know-about-inodes-on-linux/