Background
由于在select和poll中,每一次检查监听的 fd 状态变化时,都需要遍历一次用户传入的 fd 集合,因而如果当 fd 的数量很多时,一次集合遍历将会非常耗时。
为了解决这个问题,在select和poll的基础上进行优化,在Linux kernel 2.6中,引入了event poll(epoll)方法。
epoll将 fd 的监测声明和真正的监测进行了分离。
从实现的角度来说,epoll会创建一个epoll instance ,这个epoll instance 对应一个 fd 。同时,这个epoll instance 中包含一个 fd 集合(称为epoll set或interest list),集合中存储了所有希望被监听的 fd 。当某个 fd 对应的I/O操作完成时,这个 fd 会被放入ready list,ready list是epoll set的子集。
该方案是Linux下效率最高的I/O事件通知机制。本质在于epoll基于内核层面的事件通知。具体来说,epoll不是在用户线程发起轮询调用后,不断地去检查所有监听的 fd 是否状态发生变化(poll和select是这样做的),而是在当这些 fd 中任何一个发生状态变化时,内核就将这些对应的 fd 移动到epoll实例中的ready list中(这里发生了一次内核事件通知)。因此,当用户线程调用轮询方法epoll_wait时,内核不再需要进行一次 fd 的状态变化检查的遍历,而是直接返回结果。
下图为通过epoll方式实现轮询的示意图:
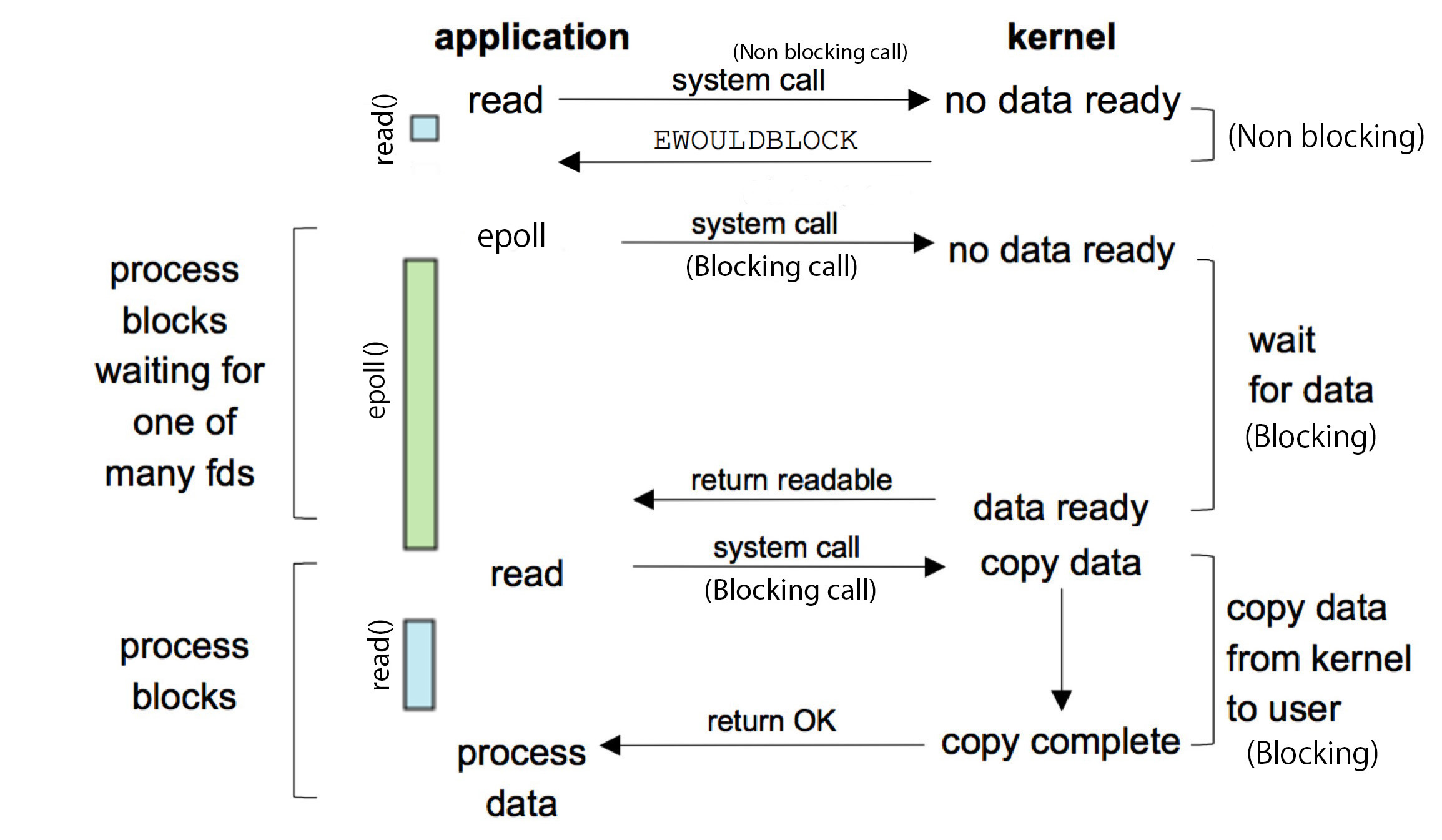
epoll
epoll stands for event poll and is a Linux kernel system call for a scalable I/O event notification mechanism, first introduced in version 2.5.44 of the Linux kernel.
Its function is to monitor multiple file descriptors to see whether I/O is possible on any of them. It is meant to replace the older POSIX select(2) and poll(2) system calls, to achieve better performance in more demanding applications, where the number of watched file descriptors is large (unlike the older system calls, which operate in O(n) time, epoll operates in O(1) time.
The central concept of the epoll API is the epoll instance, an in-kernel data structure which, from a user-space perspective, can be considered as a container for two lists:
- The interest list (sometimes also called the epoll set): the set of file descriptors that the process has registered an interest in monitoring.
- The ready list: the set of file descriptors that are “ready” for I/O. The ready list is a subset of (or, more precisely, a set of references to) the file descriptors in the interest list. The ready list is dynamically populated by the kernel as a result of I/O activity on those file descriptors.
红黑树 based
在实现上 epoll 采用红黑树来存储所有监听的 fd,而红黑树本身插入和删除性能比较稳定,时间复杂度 O(logN)。通过 epoll_ctl 函数添加进来的 fd 都会被放在红黑树的某个节点内,所以,重复添加是没有用的。
ep_poll_callback
当把 fd 添加进来的时候时候会完成关键的一步:该 fd 会与相应的设备(网卡)驱动程序建立回调关系,也就是在内核中断处理程序为它注册一个回调函数,在 fd 相应的事件触发(中断)之后(设备就绪了),内核就会调用这个回调函数,该回调函数在内核中被称为: ep_poll_callback ,这个回调函数其实就是把这个 fd 添加到 rdllist 这个双向链表(就绪链表)中。epoll_wait 实际上就是去检查 rdlist 双向链表中是否有就绪的 fd,当 rdlist 为空(无就绪 fd)时挂起当前进程,直到 rdlist 非空时进程才被唤醒并返回。
相比于 select&poll 调用时会将全部监听的 fd 从用户态空间拷贝至内核态空间,并线性扫描一遍找出就绪的 fd 再返回到用户态,epoll_wait 则是直接返回已就绪 fd,因此 epoll 的 I/O 性能不会像 select&poll 那样随着监听的 fd 数量增加而出现线性衰减,是一个非常高效的 I/O 事件驱动技术。
Comparison
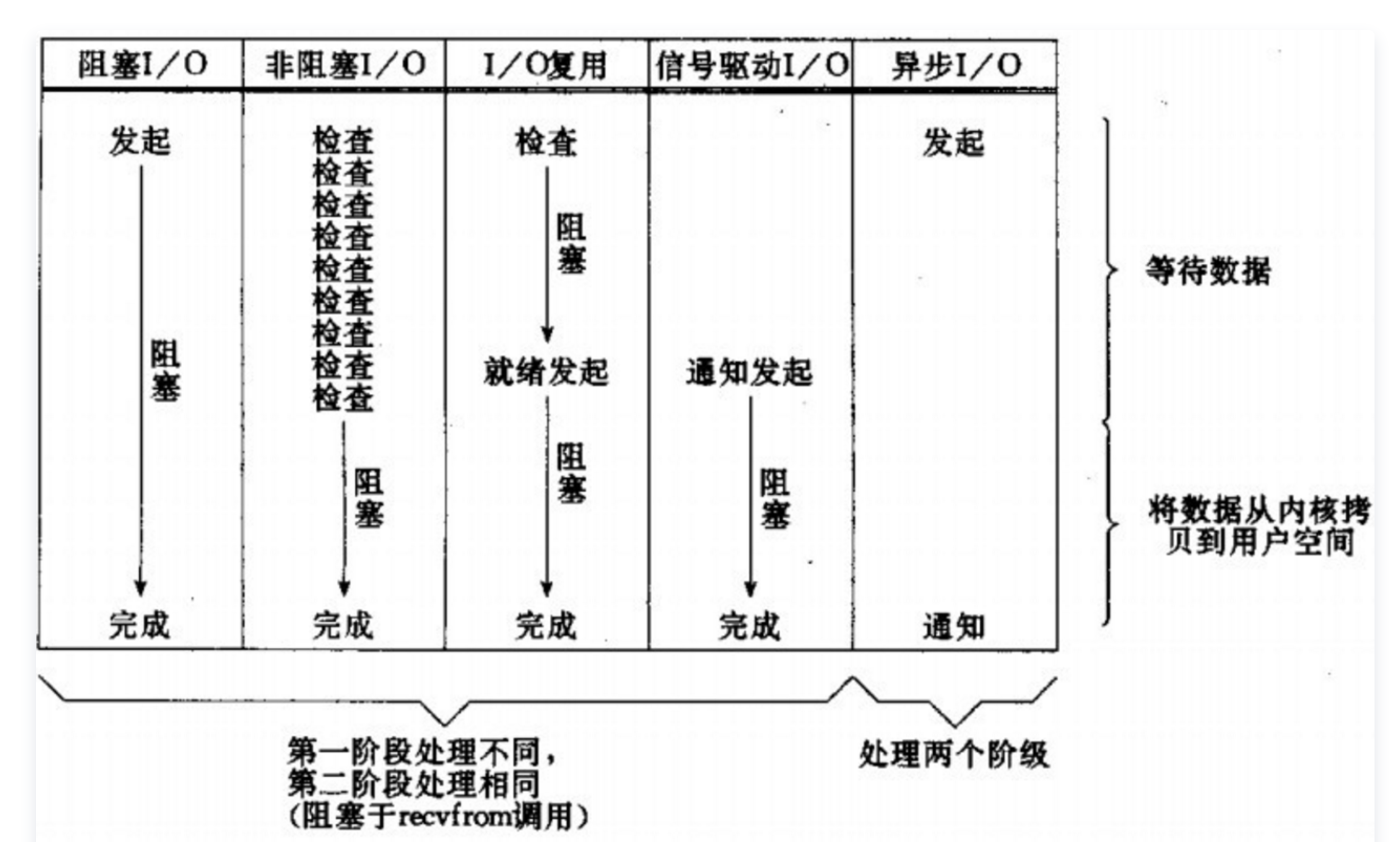
由于使用 epoll 的 I/O 多路复用需要用户进程自己负责 I/O 读写,从用户进程的角度看,读写过程是阻塞的,所以 select&poll&epoll 本质上都是同步 I/O 模型,而像 Windows 的 IOCP 这一类的异步 I/O,只需要在调用 WSARecv 或 WSASend 方法读写数据的时候把用户空间的内存 buffer 提交给 kernel,kernel 负责数据在用户空间和内核空间拷贝,完成之后就会通知用户进程,整个过程不需要用户进程参与,所以是真正的异步 I/O。
Use epoll
epoll对应一组系统调用,包括epoll_create, epoll_ctl, epoll_wait。
create epoll fd
#include <sys/epoll.h>
int epoll_create1 (int flags);
/* deprecated. use epoll_create1() in new code. */
int epoll_create(int size);
// `size`参数标示了希望被监听的 fd 的数量。从Linux 2.6.8后,这个参数被忽略(当其数量发生变化时,内核会动态的计算 fd 的数量)
调用epoll_create()会返回一个 fd,这个 fd 也被称为epoll fd。用户线程通过这个 fd (epoll fd)来增加、删除或者修改希望被观察的fd(epoll实例中存储了一个 fd 集合(称为epoll set或interest list),集合中包含所有希望被观察的 fd )。
The *flags* argument can either be 0 or EPOLL_CLOEXEC.
When the EPOLL_CLOEXEC flag is set**,** any child process forked by the current process will close the epoll descriptor before it execs, so the child process won’t have access to the epoll instance anymore.
It’s important to note that the file descriptor associated with the epoll instance needs to be released with a close() system call. Multiple processes might hold a descriptor to the same epoll instance, since, for example, a fork without the EPOLL_CLOEXEC flag will duplicate the descriptor to the epoll instance in the child process). When all of these processes have relinquished their descriptor to the epoll instance (by either calling close() or by exiting), the kernel destroys the epoll instance.
Add/remove fd into epoll object
epoll_ctl controls (configures) which file descriptors are watched by this object, and for which events. op can be ADD, MODIFY or DELETE.
#include <sys/epoll.h>
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
struct epoll_event {
__u32 events; /* events */
union {
void *ptr;
int fd;
__u32 u32;
__u64 u64;
} data;
};
- epfd: is the file descriptor returned by
epoll_createwhich identifies the epoll instance in the kernel. - fd: is the file descriptor we want to add to the epoll list/interest list.
- op: refers to the operation to be performed on the file descriptor fd. In general, three operations are supported:
- Register fd with the epoll instance (EPOLL_CTL_ADD) and get notified about events that occur on fd
- Delete/deregister fd from the epoll instance. This would mean that the process would no longer get any notifications about events on that file descriptor (EPOLL_CTL_DEL). If a file descriptor has been added to multiple epoll instances, then closing it will remove it from all of the epoll interest lists to which it was added.
- Modify the events fd is monitoring (EPOLL_CTL_MOD)
- event: is a pointer to a structure called *epoll_event* which stores the event we actually want to monitor fd for.
- The first field *events* of the epoll_event structure is a bitmask that indicates which events fd is being monitored for.
- Like so, if fd is a socket, we might want to monitor it for the arrival of new data on the socket buffer (EPOLLIN). We might also want to monitor fd for edge-triggered notifications which is done by OR-ing EPOLLET with EPOLLIN. We might also want to monitor fd for the occurrence of a registered event but only once and stop monitoring fd for subsequent occurrences of that event. This can be accomplished by OR-ing the other flags (EPOLLET, EPOLLIN) we want to set for descriptor fd with the flag for only-once notification delivery EPOLLONESHOT. All possible flags can be found in the man page.
- The second field of the epoll_event struct is a union field.
A process can add file descriptors it wants monitored to the epoll instance by calling epoll_ctl. All the file descriptors registered with an epoll instance are collectively called an epoll set* or the interest list*.

In the above diagram, process 483 has registered file descriptors *fd1*, *fd2*, *fd3*, *fd4* and *fd5* with the epoll instance. This is the *interest list* or the epoll set* of that particular epoll instance. Subsequently, when any of the file descriptors registered become ready for I/O, then they are considered to be in the ready list*.
The *ready list* is a subset of the *interest list*.
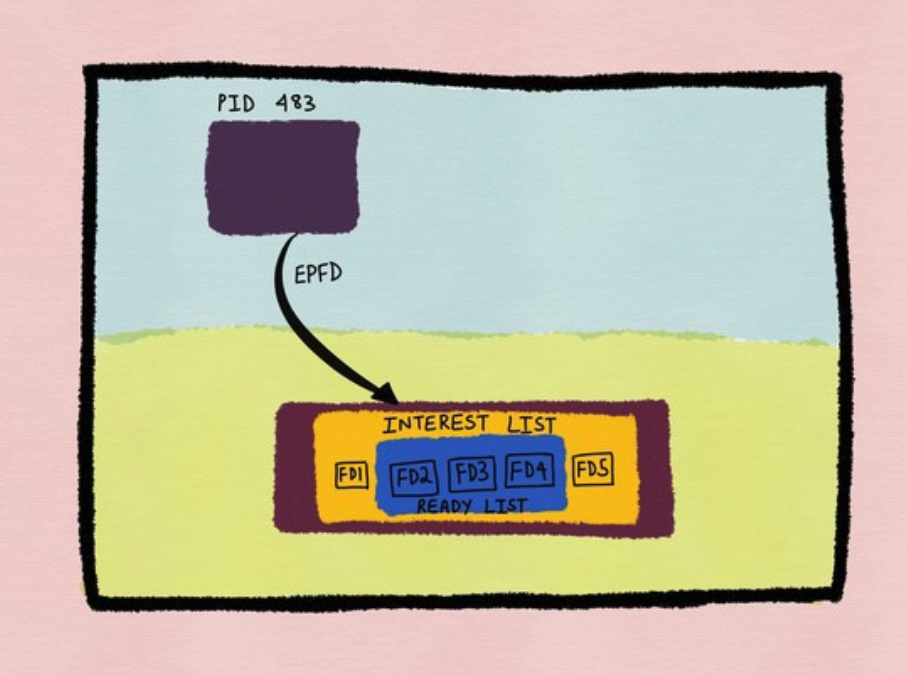
在上图中,进程483注册了 fd fd1、fd2、fd3、fd4和fd5在epoll实例中(这5个 fd 存储在epoll实例的interest list中)。此时,fd2、fd3和fd4对应的I/O操作完成了,fd2、fd3和fd4就会移动到了ready list中(ready list是interest list的子集)。
epoll_wait
当用户线程调用epoll_wait()后,用户线程会被阻塞,Waits for any of the events registered, until at least one occurs or the timeout elapses. Returns the occurred events in events, up to maxevents at once.
#include <sys/epoll.h>
int epoll_wait(int epfd, struct epoll_event *evlist, int maxevents, int timeout);
- **epfd —**对应于通过调用
epoll_create创建的epoll fd; - evlist —是一个 epoll_event 结构数组,当调用
epoll_ctl()时会被返回。当调用epoll_wait()时,这个数组会修改,以标示哪些I/O操作完成了(从实现的角度来说,这些I/O操作对应的 fd 会被移动到ready list集合中)。 - maxevents: is the length of the evlist array
- timeout: this argument behaves the same way as it does for *poll* or *select*. This value specifies for how long the *epoll_wait* system call will block:
- when the *timeout* is set to 0, *epoll_wait* does not block but returns immediately after checking which file descriptors in the interest list for epfd are ready
- when *timeout* is set to -1, *epoll_wait* will block “forever”. When *epoll_wait* blocks, the kernel can put the process to sleep until *epoll_wait* returns. *epoll_wait* will block until 1) one or more descriptors specified in the interest list for epfd become ready or 2) the call is interrupted by a signal handler
- when *timeout* is set to a non negative and non zero value, then *epoll_wait* will block until 1) one or more descriptors specified in the interest list for epfd becomes ready or 2) the call is interrupted by a signal handler or 3) the amount of time specified by *timeout* milliseconds have expired
The return values of *epoll_wait* are the following:
— if an error (EBADF or EINTR or EFAULT or EINVAL) occurred, then the return code is -1 — if the call timed out before any file descriptor in the interest list became ready, then the return code is 0 — if one or more file descriptors in the interest list became ready, then the return code is a positive integer which indicates the total number of file descriptors in the evlist array. The evlist is then examined to determine which events occurred on which file descriptors.
Level-triggered and Edge-triggered
Edge-triggered (ET)
By default, epoll provides level-triggered notifications. Every call to epoll_wait only returns the subset of file descriptors belonging to the interest list that are ready.
So if we have four file descriptors (*fd1*, *fd2*, *fd3* and *fd4*) registered, and only two (*fd2* and *fd3*) are ready at the time of calling epoll_wait, then only information about these two descriptors are returned.
It’s also interesting to note that in the default level-triggered case, the nature of the descriptors (blocking versus non-blocking) in epoll’s interest won’t really affect the result of an epoll_waitcall, since epoll only ever updates its ready list when the underlying open file description becomes ready.
Sometimes we might just want to find the status of any descriptor (say fd1, for example) in the interest list, irrespective of whether it’s ready or not. epoll allows us to find out whether I/O is possible on any particular file descriptor (even if it’s not ready at the time of calling epoll_wait) by means of supporting edge-triggered notifications. If we want information about whether there has been any I/O activity on a file descriptor since the previous call to epoll_wait (or since the descriptor was opened, if there was no previous epoll_wait call made by the process), we can get edge-triggered notifications by ORing the EPOLLET flag while calling epoll_ctl while registering a file descriptor with the epoll instance.
Level-triggered (LT)
Why epoll is more performant that select and poll
As stated in the previous post, the cost of *select*/*poll* is O(N), which means when N is very large (think of a web server handling tens of thousands of mostly sleepy clients), every time *select*/*poll* is called, even if there might only be a small number of events that actually occurred, the kernel still needs to scan every descriptor in the list.
Since epoll monitors the underlying file description, every time the open file description becomes ready for I/O, the kernel adds it to the ready list without waiting for a process to call epoll_wait to do this. *When* a process does call epoll_wait, then at that time the kernel doesn’t have to do any additional work to respond to the call, but instead returns all the information about the ready list it’s been maintaining all along.
Furthermore, with every call to select/poll requires passing the kernel the information about the descriptors we want to monitored. This is obvious from the signature to both calls. The kernel returns the information about all the file descriptors passed in which the process again needs to examine (by scanning all the descriptors) to find out which ones are ready for I/O.
int poll(struct pollfd *fds, nfds_t nfds, int timeout);int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
With epoll, once we add the file descriptors to the epoll instance’s *interest list* using the epoll_ctl call, then when we call epoll_waitin the future, we don’t need to subsequently pass the file descriptors whose readiness information we wish to find out. The kernel again only returns back information about those descriptors which are ready for I/O, as opposed to the select/poll model where the kernel returns information about *every descriptor passed in*.
As a result, the cost of epoll is O(number of events that have occurred) and not O(number of descriptors being monitored) as was the case with select/poll.
总结
相比较select/poll模型和epoll模型:
select/poll模型的代价为O(N),因此,当N很大时(比如,一个Web服务器连接了一万个客户端,而这些客户端与服务器的交互频率很低),当调用select/poll后,每一次进行轮询时,内核都需要扫描用户传入的 fd 集合中所有的 fd (尽管此时只有个别的 fd 状态改变了),以了解这些 fd 中到底哪些 fd 的状态改变了。
而在epoll中,当某个 fd 的状态改变时(发生了一次内核层面的事件通知),内核会直接将这个 fd 添加到ready list中(而不是等到用户线程调用epoll_wait时才执行这个操作)。因此,当用户线程调用轮询方法epoll_wait时,内核不再需要进行一次 fd 的状态变化检查的遍历,而是直接返回结果。因此,epoll的代价为O(1)。
其他操作系统中的epoll
- kqueue -
kqueue方法的实现方式与epoll类似,不过它仅在FreeBSD系统下存在(包括macOS)。 - event ports - event ports相当于Solaris下的epoll。
epoll的应用
- Node.js使用libuv,而libuv正是基于epoll
- Python的gevent网络库使用libevent,而libevent基于epoll
Reference
- https://en.wikipedia.org/wiki/Epoll
- https://man7.org/linux/man-pages/man7/epoll.7.html
- https://man7.org/linux/man-pages/man2/poll.2.html
- https://copyconstruct.medium.com/the-method-to-epolls-madness-d9d2d6378642
- https://cloud.tencent.com/developer/news/600726