Monolithic Architecture
To start explaining the microservice style it’s useful to compare it to the monolithic style: a monolithic application built as a single unit. Enterprise Applications are often built in three main parts: a client-side user interface (consisting of HTML pages and javascript running in a browser on the user’s machine) a database (consisting of many tables inserted into a common, and usually relational, database management system), and a server-side application. The server-side application will handle HTTP requests, execute domain logic, retrieve and update data from the database, and select and populate HTML views to be sent to the browser. This server-side application is a monolith - a single logical executable. Any changes to the system involve building and deploying a new version of the server-side application.
Such a monolithic server is a natural way to approach building such a system. All your logic for handling a request runs in a single process, allowing you to use the basic features of your language to divide up the application into classes, functions, and namespaces. With some care, you can run and test the application on a developer’s laptop, and use a deployment pipeline to ensure that changes are properly tested and deployed into production. You can horizontally scale the monolith by running many instances behind a load-balancer.
以Java为例,所有的功能打包在一个 WAR包里,基本没有外部依赖(除了容器),部署在一个JEE容器(Tomcat,JBoss,WebLogic)里,包含了 DO/DAO,Service,UI等所有逻辑。
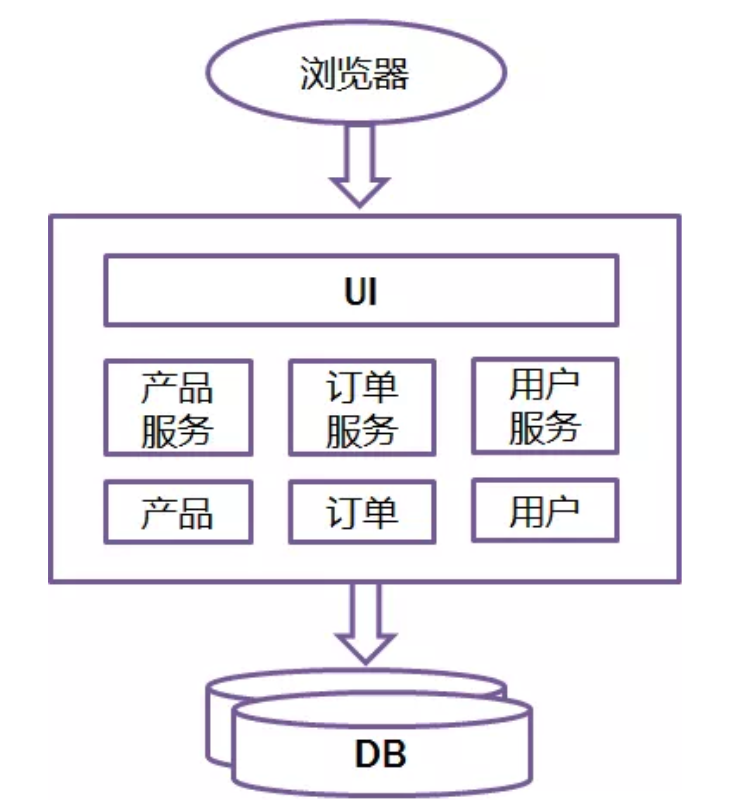
Evaluation
Monolithic比较适合小项目,优点是:
- 开发简单直接,集中式管理
- 代码的复用性高
- 具体来说,一些util code可以被高度的复用,比如获取本地时间,生成MD5之类
- 比如在 Golang 里,没有Set可以直接使用,所以我们要么自己定义一个(build from scratch),要么引入一个第三方库。如果在一个 monolithic repo中,往往这样的Set已经被大面积的时候,因而我们就不需要去再花额外的时间去调研
- 性能相对较高
- 没有分布式的管理开销和调用开销
它的缺点也非常明显,特别对于高速发展的互联网公司(这意味着业务逻辑在短时间内变得越来越复杂,同时团队的成员数量增加得非常快)来说:
- 开发效率可能较低
- 所有的开发在一个项目改代码,代码出现conflict的可能性增加
- 各个team 之间的boundary相对不清晰
- 当team越来越大时,通常我们会以folder或者file来划分team与team之间的boundary,但是这个boundary相对模糊,
- 代码相对更难维护
- 代码功能耦合在一起。比如,当需要修改一个function 的signature时,需要check该function的所有usage,以避免引入问题(如果)
- 同时,导致debug难度增大
- 负责不同业务模块的同学可能需要阅读其他业务的代码逻辑
- 部署不灵活
- 构建时间长,任何小修改必须重新构建整个项目,这个过程往往很长
- 稳定性不高
- 一个问题,可能可以导致整个application/service直接挂掉。比如如果是一个golang service,一个未处理的panic则会直接导致整个service退出
- 扩展性不够
- Scaling requires scaling of the entire application rather than parts of it that require greater resource.
- 这可能会导致资源的浪费
- Scaling requires scaling of the entire application rather than parts of it that require greater resource.
- Ownership 可能很低
代码相对更难维护
Normally we would urge a large team building a monolithic application to divide itself along business lines. The main issue we have seen here, is that they tend to be organised around too many contexts. If the monolith spans many of these modular boundaries it can be difficult for individual members of a team to fit them into their short-term memory. Additionally we see that the modular lines require a great deal of discipline to enforce. The necessarily more explicit separation required by service components makes it easier to keep the team boundaries clear.
Ownership 很低 - Products not Projects
Most application development efforts that we see use a project model: where the aim is to deliver some piece of software which is then considered to be completed. On completion the software is handed over to a maintenance organization and the project team that built it is disbanded.
Microservice proponents tend to avoid this model, preferring instead the notion that a team should own a product over its full lifetime. A common inspiration for this is Amazon’s notion of “you build, you run it” where a development team takes full responsibility for the software in production. This brings developers into day-to-day contact with how their software behaves in production and increases contact with their users, as they have to take on at least some of the support burden.
The product mentality, ties in with the linkage to business capabilities. Rather than looking at the software as a set of functionality to be completed, there is an on-going relationship where the question is how can software assist its users to enhance the business capability.
Monolithic Repo with Multiple Services
一种变种,是一个monolithic codebase,但这个codebase中包含多个可以独立运行的services。
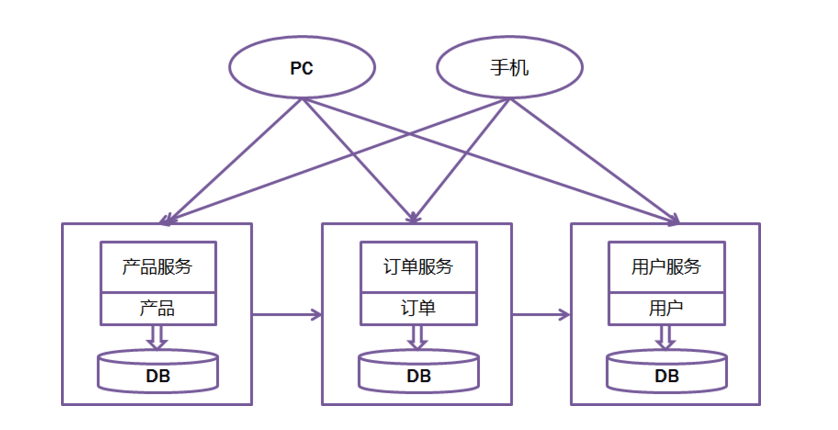
Microservice Architecture
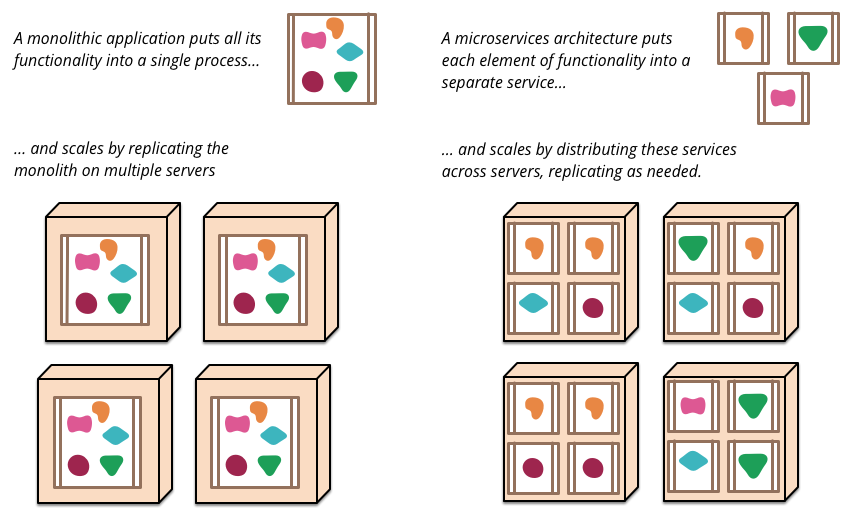
The microservices software-development pattern provides a method to build a single, unified service out of a collection of smaller services. Each microservice component focuses on a set of loosely coupled actions on a small, well-defined dataset. Each microservice includes an independent storage system so that all of its data is located in a single location. By reducing the number of blocking operations on the data-storage backend, this architecture enables the microservice to scale horizontally, increasing capacity by adding more nodes to the system rather than just increasing the resources (RAM, CPUs, storage) on a single node.
Microservices can be written in any programming language and can use whichever database, hardware, and software environment makes the most sense for the organization. An application programming interface (API) provides the only means for users and other services to access the microservice’s data.
The API need not be in any particular format, but representational state transfer (REST) is popular, in part because its human-readability and stateless nature make it useful for web interfaces. Other common API formats include gRPC and GraphQL, which each have different approaches and tradeoffs for how data is accessed.
Characteristics of a Microservice Architecture
We cannot say there is a formal definition of the microservices architectural style, but we can attempt to describe what we see as common characteristics for architectures that fit the label. As with any definition that outlines common characteristics, not all microservice architectures have all the characteristics, but we do expect that most microservice architectures exhibit most characteristics. While we authors have been active members of this rather loose community, our intention is to attempt a description of what we see in our own work and in similar efforts by teams we know of. In particular we are not laying down some definition to conform to.
- Componentization via Services
- Organized around Business Capabilities
Organized around Business Capabilities
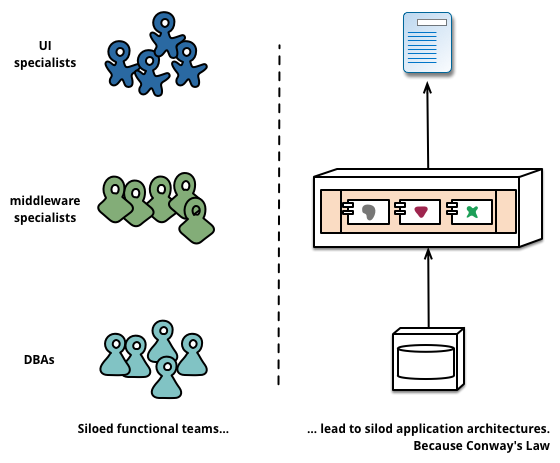
When looking to split a large application into parts, often management focuses on the technology layer, leading to UI teams, server-side logic teams, and database teams. When teams are separated along these lines, even simple changes can lead to a cross-team project taking time and budgetary approval. A smart team will optimise around this and plump for the lesser of two evils - just force the logic into whichever application they have access to. Logic everywhere in other words. This is an example of Conway’s Law[5] in action.
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.
– Melvin Conway, 1968
Service-Oriented Architecture (SOA) vs Microservices
Service-oriented architecture (SOA) is a design approach where multiple services collaborate to provide some end set of capabilities. A service here typically means a completely separate operating system process. Communication between these services occurs via calls across a network rather than method calls within a process boundary.
SOA emerged as an approach to combat the challenges of the large monolithic applications. It is an approach that aims to promote the reusability of software; two or more end-user applications, for example, could both use the same services. It aims to make it easier to maintain or rewrite software, as theoretically we can replace one service with another without anyone knowing, as long as the semantics of the service don’t change too much.
SOA at its heart is a very sensible idea. However, despite many efforts, there is a lack of good consensus on how to do SOA well. In my opinion, much of the industry has failed to look holistically enough at the problem and present a compelling alternative to the narrative set out by various vendors in this space.
Many of the problems laid at the door of SOA are actually problems with things like communication protocols (e.g., SOAP), vendor middleware, a lack of guidance about service granularity, or the wrong guidance on picking places to split your system. We’ll tackle each of these in turn throughout the rest of the book. A cynic might suggest that vendors co-opted (and in some cases drove) the SOA movement as a way to sell more products, and those selfsame products in the end undermined the goal of SOA.
Much of the conventional wisdom around SOA doesn’t help you understand how to split something big into something small. It doesn’t talk about how big is too big. It doesn’t talk enough about real-world, practical ways to ensure that services do not become overly coupled. The number of things that go unsaid is where many of the pitfalls associated with SOA originate.
The microservice approach has emerged from real-world use, taking our better understanding of systems and architecture to do SOA well. So you should instead think of microservices as a specific approach for SOA in the same way that XP or Scrum are specific approaches for Agile software development.
Other Decompositional Techniques
When you get down to it, many of the advantages of a microservice-based architecture come from its granular nature and the fact that it gives you many more choices as to how to solve problems. But could similar decompositional techniques achieve the same benefits?
Shared Libraries
A very standard decompositional technique that is built into virtually any language is breaking down a codebase into multiple libraries. These libraries may be provided by third parties, or created in your own organization.
Libraries give you a way to share functionality between teams and services. I might create a set of useful collection utilities, for example, or perhaps a statistics library that can be reused.
Teams can organize themselves around these libraries, and the libraries themselves can be reused. But there are some drawbacks.
First, you lose true technology heterogeneity. The library typically has to be in the same language, or at the very least run on the same platform. Second, the ease with which you can scale parts of your system independently from each other is curtailed. Next, unless you’re using dynamically linked libraries, you cannot deploy a new library without redeploying the entire process, so your ability to deploy changes in isolation is reduced. And perhaps the kicker is that you lack the obvious seams around which to erect architectural safety measures to ensure system resiliency.
Shared libraries do have their place. You’ll find yourself creating code for common tasks that aren’t specific to your business domain that you want to reuse across the organization, which is an obvious candidate for becoming a reusable library. You do need to be careful, though. Shared code used to communicate between services can become a point of coupling.
Services can and should make heavy use of third-party libraries to reuse common code. But they don’t get us all the way there.
HOW - 怎么具体实践微服务
服务之间如何通信
正确性保证
在拆分一些非常critical的业务时,可以使用comparison mode来potentially capture issues。即比较拆分之后的服务返回结果和拆分之前的function的处理结果,如果有mismatch,说明可能存在bug,这时候就人为介入来对比这个mismatch是不是因为真实存在的bug导致的。
如果不是,这意味着这是false positive,导致false positive的情况有很多,比如cache导致的data inconsistency,两套一样的逻辑不在同一时刻执行导致的结果不同。比如一个promotion是00:00结束,一套逻辑在23:59:59:888执行,所以认为当前promotion还可用;而另套逻辑在00:00:00:001执行,因此认为当前promotion已经expire了。最终导致false positive mismatch出现。
Insights
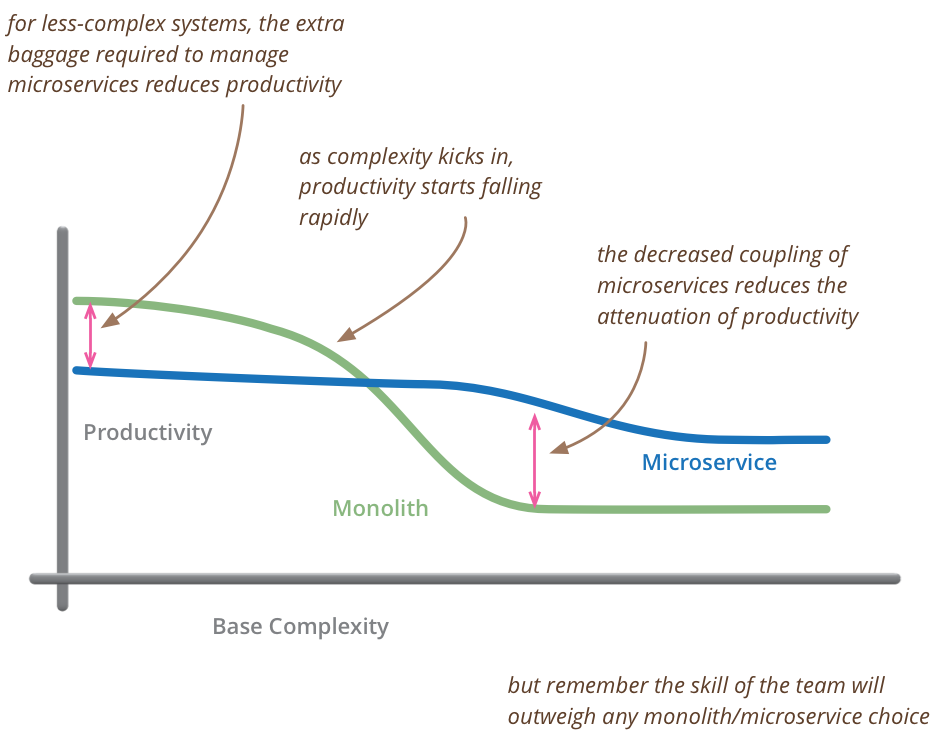
When do Microservices
So my primary guideline would be don’t even consider microservices unless you have a system that’s too complex to manage as a monolith. The majority of software systems should be built as a single monolithic application. Do pay attention to good modularity within that monolith, but don’t try to separate it into separate services.
Organized around Business Capabilities
When looking to split a large application into parts, often management focuses on the technology layer, leading to UI teams, server-side logic teams, and database teams. When teams are separated along these lines, even simple changes can lead to a cross-team project taking time and budgetary approval. A smart team will optimise around this and plump for the lesser of two evils - just force the logic into whichever application they have access to. Logic everywhere in other words. This is an example of Conway’s Law[5] in action.
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.
– Melvin Conway, 1968
How big is a microservice?
Although “microservice” has become a popular name for this architectural style, its name does lead to an unfortunate focus on the size of service, and arguments about what constitutes “micro”. In our conversations with microservice practitioners, we see a range of sizes of services. The largest sizes reported follow Amazon’s notion of the Two Pizza Team (i.e. the whole team can be fed by two pizzas), meaning no more than a dozen people. On the smaller size scale we’ve seen setups where a team of half-a-dozen would support half-a-dozen services.
This leads to the question of whether there are sufficiently large differences within this size range that the service-per-dozen-people and service-per-person sizes shouldn’t be lumped under one microservices label. At the moment we think it’s better to group them together, but it’s certainly possible that we’ll change our mind as we explore this style further.
SOA vs Microservice
我个人理解,Microservice是SOA的传承,但一个最本质的区别就在于Smart endpoints and dumb pipes,或者说是真正的分布式的、去中心化的。Smart endpoints and dumb pipes本质就是去ESB,把所有的“思考”逻辑包括路由、消息解析等放在服务内部(Smart endpoints),去掉一个大一统的ESB,服务间轻(dumb pipes)通信,是比SOA更彻底的拆分。
微服务的优点和缺点
优点
Scalability is one of the primary motivations for moving to a microservice architecture. Moreover, the scalability effect on rarely used components is negligible. Components that are used by the most users should therefore be considered for migration first.
- Strong Module Boundaries
- 各个团队之间的boundary非常清晰
- 进而带来的好处是,比如:在debug的时候界限非常清晰,即每个team只需要保证自己的service在给定的input时,output是正确的即可
- 同时带来更高的cohesive和更低的coupling
- 各个团队之间的boundary非常清晰
技术栈灵活
One of the consequences of centralised governance is the tendency to standardise on single technology platforms. Experience shows that this approach is constricting - not every problem is a nail and not every solution a hammer. We prefer using the right tool for the job and while monolithic applications can take advantage of different languages to a certain extent, it isn’t that common.
Splitting the monolith’s components out into services we have a choice when building each of them. You want to use Node.js to standup a simple reports page? Go for it. C++ for a particularly gnarly near-real-time component? Fine. You want to swap in a different flavour of database that better suits the read behaviour of one component? We have the technology to rebuild him.
Of course, just because you can do something, doesn’t mean you should - but partitioning your system in this way means you have the option.
Teams building microservices prefer a different approach to standards too. Rather than use a set of defined standards written down somewhere on paper they prefer the idea of producing useful tools that other developers can use to solve similar problems to the ones they are facing. These tools are usually harvested from implementations and shared with a wider group, sometimes, but not exclusively using an internal open source model. Now that git and github have become the de facto version control system of choice, open source practices are becoming more and more common in-house .
Resilience
A key concept in resilience engineering is the bulkhead. If one component of a system fails, but that failure doesn’t cascade, you can isolate the problem and the rest of the system can carry on working. Service boundaries become your obvious bulkheads. In a monolithic service, if the service fails, everything stops working. With a monolithic system, we can run on multiple machines to reduce our chance of failure, but with microservices, we can build systems that handle the total failure of services and degrade functionality accordingly.
We do need to be careful, however. To ensure our microservice systems can properly embrace this improved resilience, we need to understand the new sources of failure that distributed systems have to deal with. Networks can and will fail, as will machines. We need to know how to handle this, and what impact (if any) it should have on the end user of our software.
Scaling
With a large, monolithic service, we have to scale everything together. One small part of our overall system is constrained in performance, but if that behavior is locked up in a giant monolithic application, we have to handle scaling everything as a piece. With smaller services, we can just scale those services that need scaling, allowing us to run other parts of the system on smaller, less powerful hardware,
Gilt, an online fashion retailer, adopted microservices for this exact reason. Starting in 2007 with a monolithic Rails application, by 2009 Gilt’s system was unable to cope with the load being placed on it. By splitting out core parts of its system, Gilt was better able to deal with its traffic spikes, and today has over 450 microservices, each one running on multiple separate machines.
When embracing on-demand provisioning systems like those provided by Amazon Web Services, we can even apply this scaling on demand for those pieces that need it. This allows us to control our costs more effectively. It’s not often that an architectural approach can be so closely correlated to an almost immediate cost savings.
Ease of Deployment
A one-line change to a million-line-long monolithic application requires the whole application to be deployed in order to release the change. That could be a largeimpact, high-risk deployment. In practice, large-impact, high-risk deployments end up happening infrequently due to understandable fear. Unfortunately, this means that our changes build up and build up between releases, until the new version of our application hitting production has masses of changes. And the bigger the delta between releases, the higher the risk that we’ll get something wrong!
With microservices, we can make a change to a single service and deploy it independently of the rest of the system. This allows us to get our code deployed faster. If a problem does occur, it can be isolated quickly to an individual service, making fast rollback easy to achieve. It also means we can get our new functionality out to customers faster. This is one of the main reasons why organizations like Amazon and Netflix use these architectures—to ensure they remove as many impediments as possible to getting software out the door.
Organizational Alignment/Strong Module Boundaries
Many of us have experienced the problems associated with large teams and large codebases. These problems can be exacerbated when the team is distributed. We also know that smaller teams working on smaller codebases tend to be more productive.
Microservices allow us to better align our architecture to our organization, helping us minimize the number of people working on any one codebase to hit the sweet spot of team size and productivity. We can also shift ownership of services between teams to try to keep people working on one service colocated.
这其实跟 Unix 的 Do one thing and do it well 的 align的。
Applications built from microservices aim to be as decoupled and as cohesive as possible - they own their own domain logic and act more as filters in the classical Unix sense - receiving a request, applying logic as appropriate and producing a response.
Higher business capacity
Advocates of microservices are quick to introduce Conways Law, the notion that the structure of a software system mirrors the communication structure of the organization that built it. With larger teams, particularly if these teams are based in different locations, it’s important to structure the software to recognize that inter-team communications will be less frequent and more formal than those within a team. Microservices allow each team to look after relatively independent units with that kind of communication pattern.
代码相对更好维护
Normally we would urge a large team building a monolithic application to divide itself along business lines. The main issue we have seen here, is that they tend to be organised around too many contexts. If the monolith spans many of these modular boundaries it can be difficult for individual members of a team to fit them into their short-term memory. Additionally we see that the modular lines require a great deal of discipline to enforce. The necessarily more explicit separation required by service components makes it easier to keep the team boundaries clear.
缺点
- 复杂的多服务运维
- 服务管理
- 服务monitor
- 潜在的更高的沟通成本
- 当一个unpexected behaviour出现时(from user’s perspective),入口端的service的owner通常会先排查问题,如果发现他的dependency的output异常时,需要把问题raise给这个dependency。而这个异常又可能是因为这个dependency的dependency导致的,从而就要将问题从一个team传递到多个team,直到定位到问题
- 但是,如果换个角度分析,当业务系统变得非常复杂的时候,将其拆分成多个service,且分别又不同的team来维护是非常合理的。换句话说,如果不这样做,这仍然会导致一个问题需要花费非常多的时间来debug(由于不同业务对应不同的 context),因而虽然沟通成本不高,但解决问题的效率并不是非常高(因为可能先去了解业务本身,然后再去debug)
- 当一个unpexected behaviour出现时(from user’s perspective),入口端的service的owner通常会先排查问题,如果发现他的dependency的output异常时,需要把问题raise给这个dependency。而这个异常又可能是因为这个dependency的dependency导致的,从而就要将问题从一个team传递到多个team,直到定位到问题
- 可能存在重复工作
- 更复杂的异常/错误处理 - design for failure
- Testing is more difficult
- 潜在的性能降低
- Remote calls are more expensive than in-process calls
- Developers must deal with the additional complexity of creating a distributed system
- 比如distributed transaction、distributed tracing
- 更复杂的系统集成测试
- 数据一致性保证的成本增加
- 服务间通信成本增加
- Deployment complexity. In production, there is also the operational complexity of deploying and managing a system comprised of many different service types.
更复杂的异常/错误处理
A consequence of using services as components, is that applications need to be designed so that they can tolerate the failure of services. Any service call could fail due to unavailability of the supplier, the client has to respond to this as gracefully as possible. This is a disadvantage compared to a monolithic design as it introduces additional complexity to handle it. The consequence is that microservice teams constantly reflect on how service failures affect the user experience.
Some technics
- Circuit breaker
潜在的性能降低
The first of these is performance. You have to be in a really unusual spot to see in-process function calls turn into a performance hot spot these days, but remote calls are slow. If your service calls half-a-dozen remote services, each which calls another half-a-dozen remote services, these response times add up to some horrible latency characteristics.
Of course you can do a great deal to mitigate this problem. Firstly you can increase the granularity of your calls, so you make fewer of them. This complicates your programming model, you now have to think of how to batch up your inter-service interactions. It will also only get you so far, as you are going to have to call each collaborating service at least once.
The second mitigation is to use asynchrony. If make six asynchronous calls in parallel you’re now only as slow as the slowest call instead of the sum of their latencies. This can be a big performance gain, but comes at another cognitive cost. Asynchronous programming is hard: hard to get right, and much harder to debug. But most microservice stories I’ve heard need asynchrony in order to get acceptable performance.
Reference
Martin Fowler
- definition - https://martinfowler.com/articles/microservices.html
- https://martinfowler.com/articles/break-monolith-into-microservices.html
- https://martinfowler.com/articles/microservice-trade-offs.html
- https://martinfowler.com/bliki/MonolithFirst.html
- https://martinfowler.com/bliki/MicroservicePremium.html
- https://martinfowler.com/bliki/MicroservicePrerequisites.html
Misc
- https://insights.sei.cmu.edu/blog/8-steps-for-migrating-existing-applications-to-microservices/
- https://microservices.io/refactoring/
- https://microservices.io/patterns/microservices.html
- https://microservices.io/patterns/monolithic.html
- Building Microservices: Designing Fine-Grained Systems - Sam Newman
- Monolith to Microservices : Evolutionary Patterns to Transform Your Monolith - Sam Newman
- There is no such thing as a microservice! - https://microservices.io/microservices/news/2018/02/20/no-such-thing-as-a-microservice.html
- What are microservices? - https://microservices.io/index.html
- Event-Driven Data Management for Microservices - https://www.nginx.com/blog/introduction-to-microservices/