Service Discovery
Let’s imagine that you are writing some code that invokes a service that has a REST API or Thrift API. In order to make a request, your code needs to know the network location (IP address and port) of a service instance. In a traditional application running on physical hardware, the network locations of service instances are relatively static. For example, your code can read the network locations from a configuration file that is occasionally updated.
In a modern, cloud‑based microservices application, however, this is a much more difficult problem to solve as shown in the following diagram.
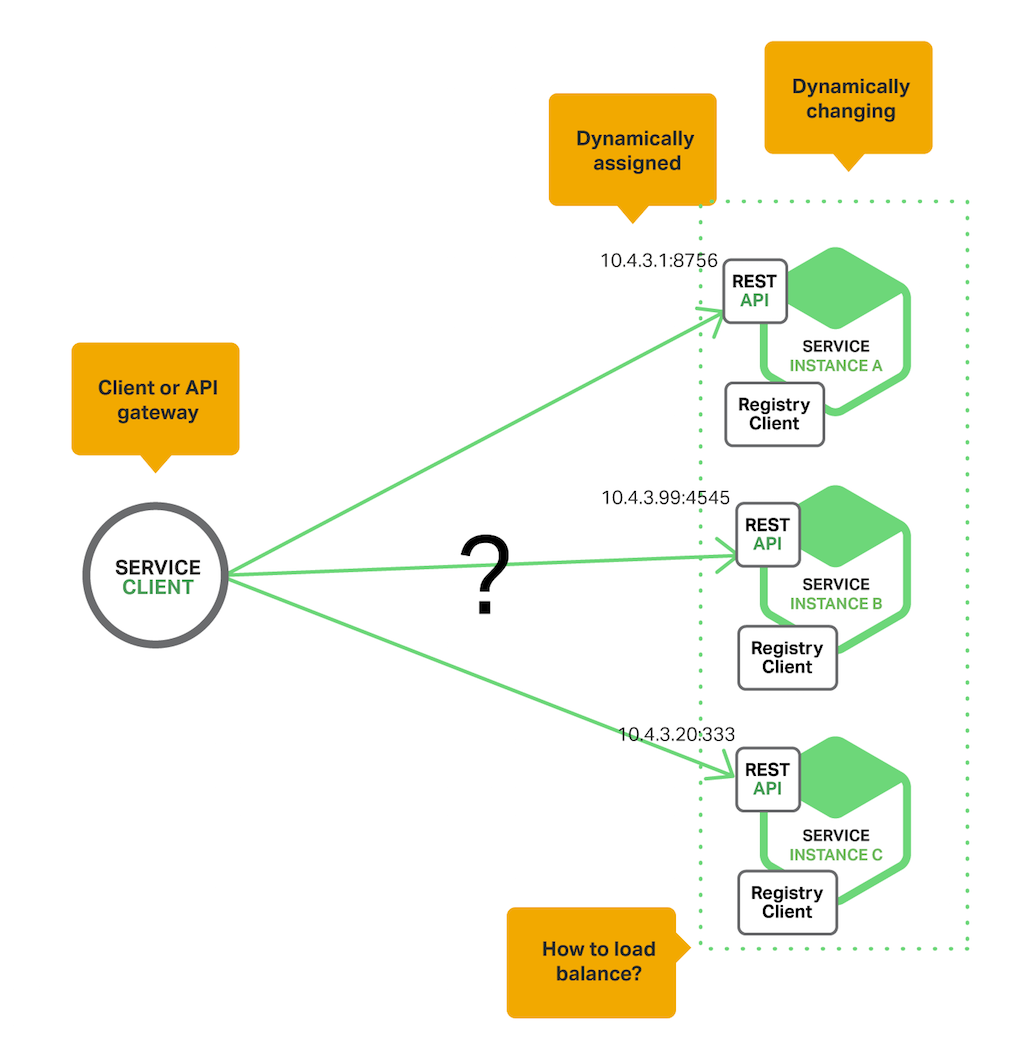
Service Discovery Pattern
The Client‑Side Discovery Pattern
When using client‑side discovery, the client is responsible for determining the network locations of available service instances and load balancing requests across them. The client queries a service registry, which is a database of available service instances. The client then uses a load‑balancing algorithm to select one of the available service instances and makes a request.
The following diagram shows the structure of this pattern.
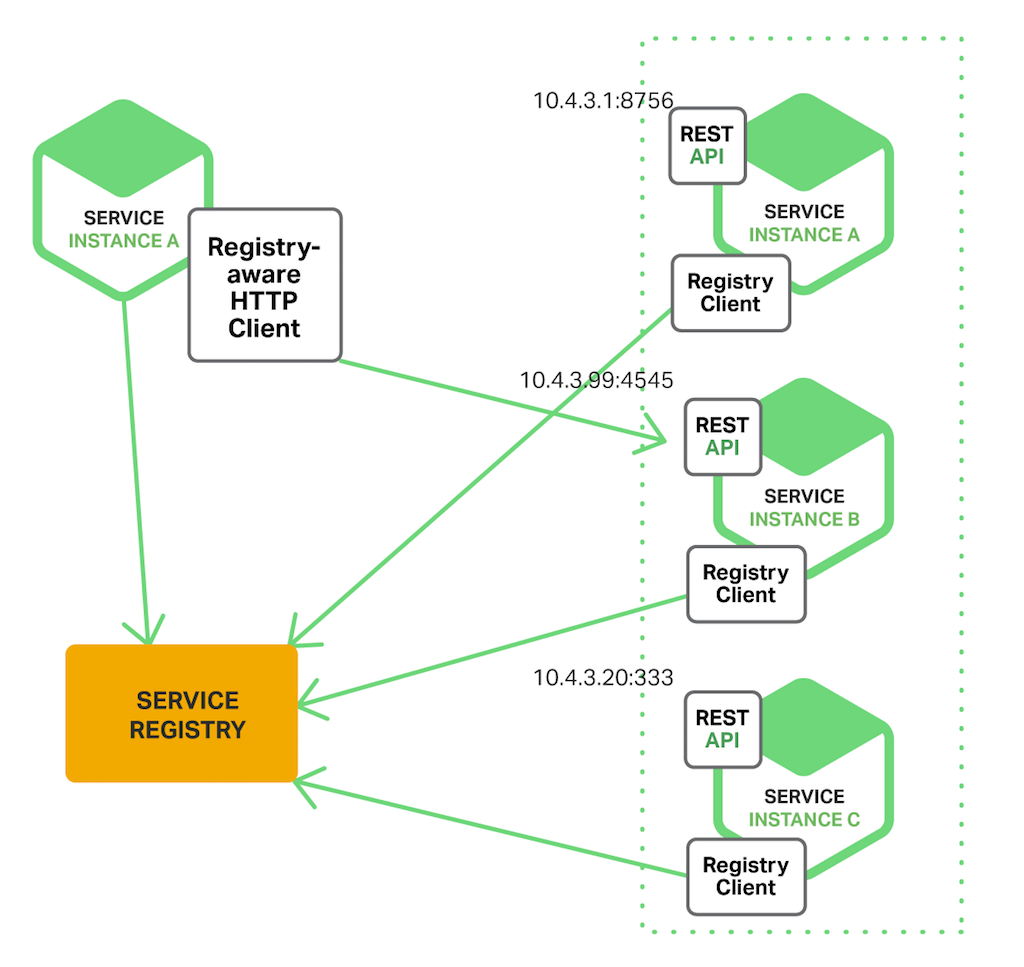
The network location of a service instance is registered with the service registry when it starts up. It is removed from the service registry when the instance terminates. The service instance’s registration is typically refreshed periodically using a heartbeat mechanism.
Netflix OSS provides a great example of the client‑side discovery pattern. Netflix Eureka is a service registry. It provides a REST API for managing service‑instance registration and for querying available instances. Netflix Ribbon is an IPC client that works with Eureka to load balance requests across the available service instances. We will discuss Eureka in more depth later in this article.
The client‑side discovery pattern has a variety of benefits and drawbacks. This pattern is relatively straightforward and, except for the service registry, there are no other moving parts. Also, since the client knows about the available services instances, it can make intelligent, application‑specific load‑balancing decisions such as using hashing consistently.
One significant drawback of this pattern is that it couples the client with the service registry. You must implement client‑side service discovery logic for each programming language and framework used by your service clients.
The Server‑Side Discovery Pattern
The following diagram shows the structure of this pattern.
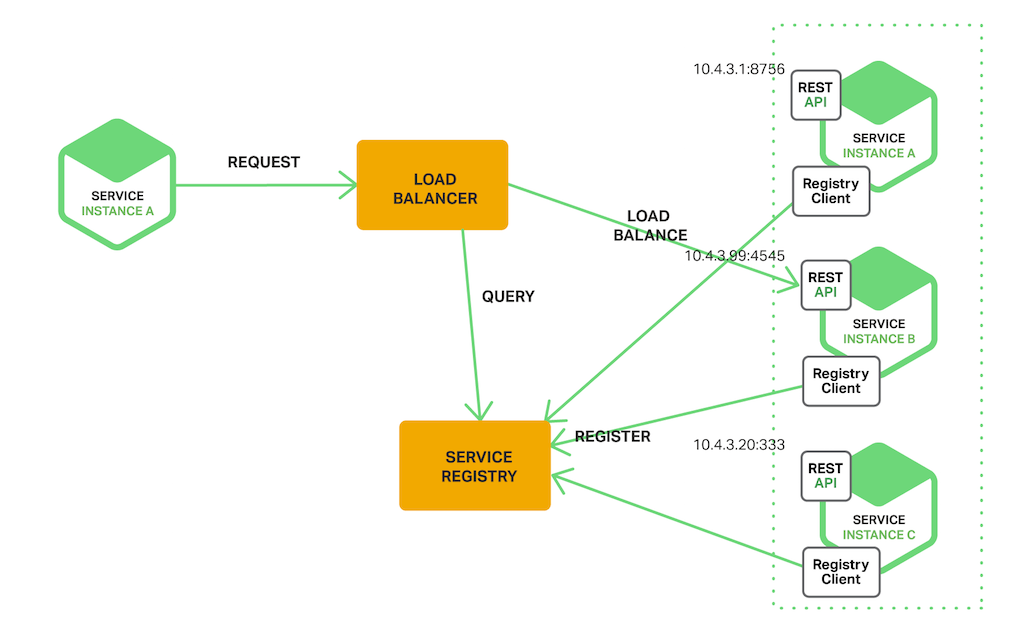
The client makes a request to a service via a load balancer. The load balancer queries the service registry and routes each request to an available service instance. As with client‑side discovery, service instances are registered and deregistered with the service registry.
HTTP servers and load balancers such as NGINX Plus and NGINX can also be used as a server-side discovery load balancer.
Some deployment environments such as Kubernetes and Marathon run a proxy on each host in the cluster. The proxy plays the role of a server‑side discovery load balancer. In order to make a request to a service, a client routes the request via the proxy using the host’s IP address and the service’s assigned port. The proxy then transparently forwards the request to an available service instance running somewhere in the cluster.
The server‑side discovery pattern has several benefits and drawbacks. One great benefit of this pattern is that details of discovery are abstracted away from the client. Clients simply make requests to the load balancer. This eliminates the need to implement discovery logic for each programming language and framework used by your service clients. Also, as mentioned above, some deployment environments provide this functionality for free. This pattern also has some drawbacks, however. Unless the load balancer is provided by the deployment environment, it is yet another highly available system component that you need to set up and manage.
Service Registry
The service registry is a key part of service discovery. It is a database containing the network locations of service instances. A service registry needs to be highly available and up to date. Clients can cache network locations obtained from the service registry. However, that information eventually becomes out of date and clients become unable to discover service instances. Consequently, a service registry consists of a cluster of servers that use a replication protocol to maintain consistency.
As mentioned earlier, Netflix Eureka is good example of a service registry. It provides a REST API for registering and querying service instances. A service instance registers its network location using a POST request. Every 30 seconds it must refresh its registration using a PUT request. A registration is removed by either using an HTTP DELETE request or by the instance registration timing out. As you might expect, a client can retrieve the registered service instances by using an HTTP GET request.
Service Registry Patterns
As previously mentioned, service instances must be registered with and deregistered from the service registry. There are a couple of different ways to handle the registration and deregistration. One option is for service instances to register themselves, the self‑registration pattern. The other option is for some other system component to manage the registration of service instances, the third‑party registration pattern.
The Self‑Registration Pattern
When using the self‑registration pattern, a service instance is responsible for registering and deregistering itself with the service registry. Also, if required, a service instance sends heartbeat requests to prevent its registration from expiring. The following diagram shows the structure of this pattern.
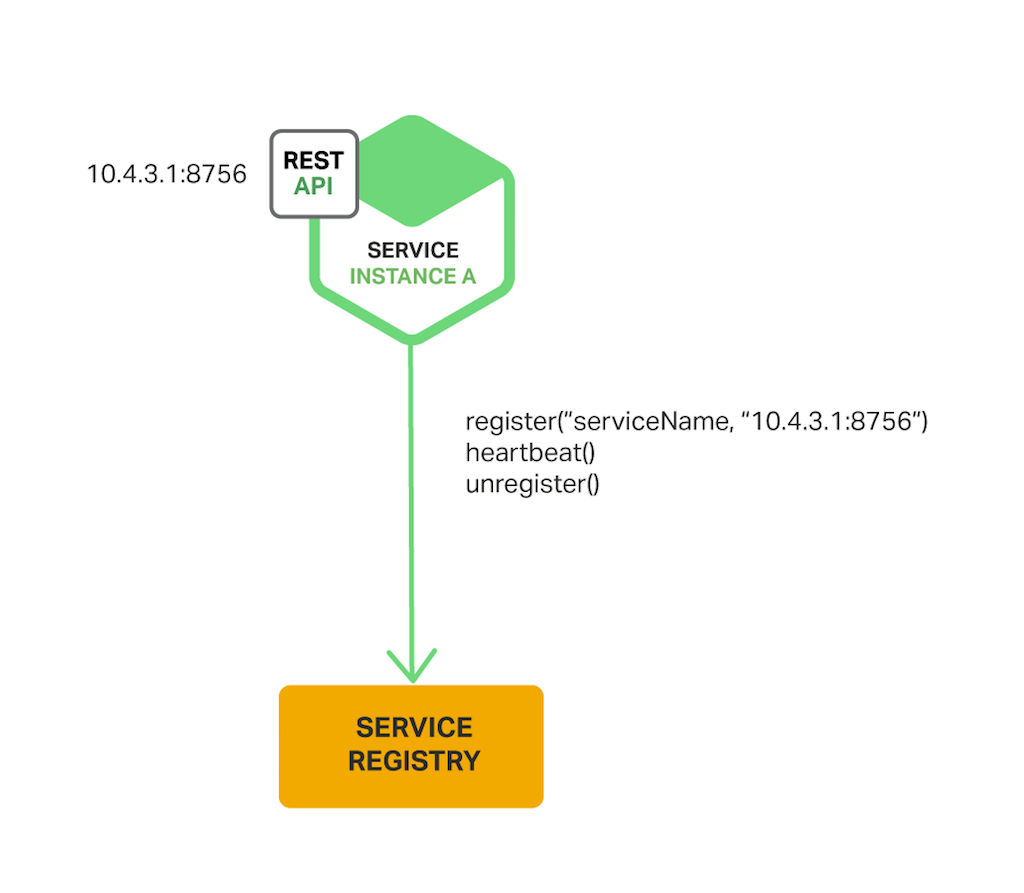
A good example of this approach is the Netflix OSS Eureka client. The Eureka client handles all aspects of service instance registration and deregistration. The Spring Cloud project, which implements various patterns including service discovery, makes it easy to automatically register a service instance with Eureka. You simply annotate your Java Configuration class with an @EnableEurekaClient annotation.
The self‑registration pattern has various benefits and drawbacks. One benefit is that it is relatively simple and doesn’t require any other system components. However, a major drawback is that it couples the service instances to the service registry. You must implement the registration code in each programming language and framework used by your services.
The alternative approach, which decouples services from the service registry, is the third‑party registration pattern.
The Third‑Party Registration Pattern
When using the third-party registration pattern, service instances aren’t responsible for registering themselves with the service registry. Instead, another system component known as the service registrar handles the registration. The service registrar tracks changes to the set of running instances by either polling the deployment environment or subscribing to events. When it notices a newly available service instance it registers the instance with the service registry. The service registrar also deregisters terminated service instances. The following diagram shows the structure of this pattern.
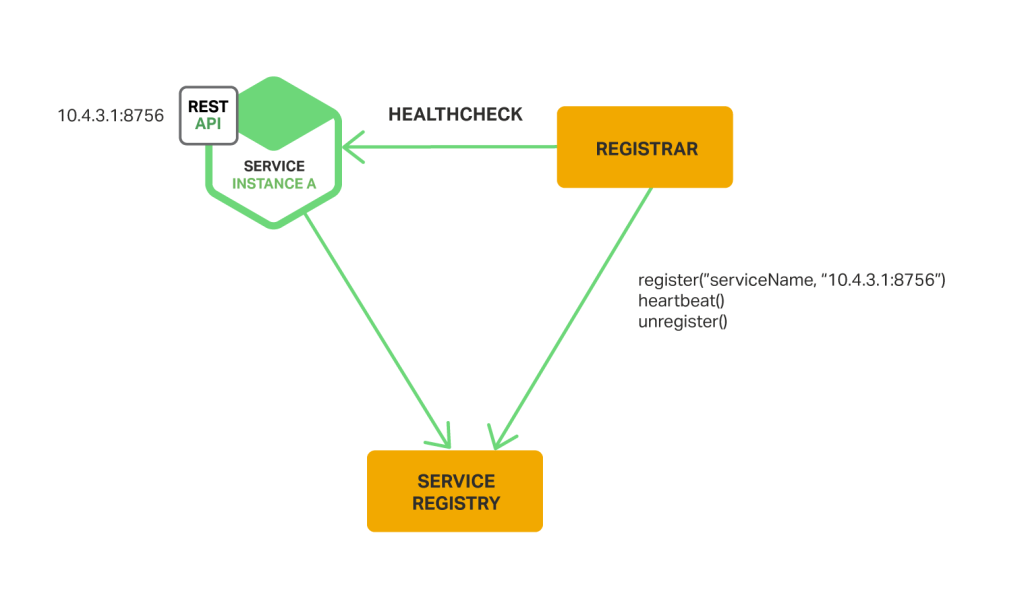
One example of a service registrar is the open source Registrator project. It automatically registers and deregisters service instances that are deployed as Docker containers. Registrator supports several service registries, including etcd and Consul.
Another example of a service registrar is NetflixOSS Prana. Primarily intended for services written in non‑JVM languages, it is a sidecar application that runs side by side with a service instance. Prana registers and deregisters the service instance with Netflix Eureka.
The service registrar is a built‑in component of deployment environments. The EC2 instances created by an Autoscaling Group can be automatically registered with an ELB. Kubernetes services are automatically registered and made available for discovery.
The third‑party registration pattern has various benefits and drawbacks. A major benefit is that services are decoupled from the service registry. You don’t need to implement service‑registration logic for each programming language and framework used by your developers. Instead, service instance registration is handled in a centralized manner within a dedicated service.
One drawback of this pattern is that unless it’s built into the deployment environment, it is yet another highly available system component that you need to set up and manage.
问题讨论
负载均衡和调用策略
- 对相同服务下的不同节点设置不同的权重,进行流量调度。
优雅的服务注册与服务下线
绝大多数的服务注册中心都提供了健康检查功能,在应用停止后会自动摘除服务所对应的节点。但是我们也不能完全依赖此功能,应用应该在停止时主动调用服务注册中心的服务下线接口。
在Dubbo中,我们利用ZooKeeper 中的瞬时节点(ephemeral node)了,即当服务的消费者 subscribe 了自己依赖的一个服务生产者的信息后,当服务生产者在Zookeeper中心更新了自己的节点信息时,服务的消费者可以实时的收到通知。
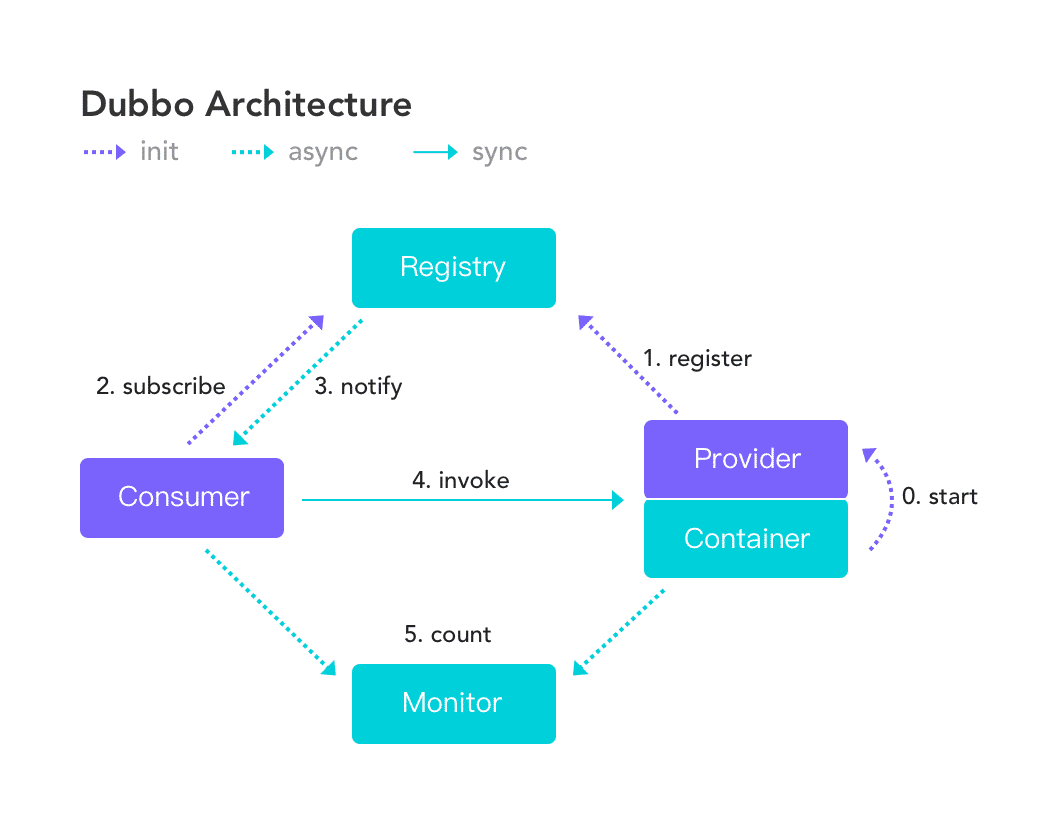
这意味着我们可以实现“优雅的服务注册与服务下线”,即服务消费者可以(通过被push的形式)实时的感知到服务生产者的节点变化。
或者,首先切断流量,再进行 server 的下线。具体的做法便是:先关闭心跳开关,客户端感知停止调用后,再关闭服务进程。
感知服务的下线
服务上线时自然要注册到注册中心,但下线时也得从注册中心中摘除。注册是一个主动的行为,这没有特别要注意的地方,但服务下线却是一个值得思考的问题。服务下线包含了主动下线和系统宕机等异常方式的下线。
临时节点 + 长连接
在 zookeeper 中存在持久化节点和临时节点的概念。持久化节点一经创建,只要不主动删除,便会一直持久化存在;临时节点的生命周期则是和客户端的连接同生共死的,应用连接到 zookeeper 时创建一个临时节点,使用长连接维持会话,这样无论何种方式服务发生下线,zookeeper 都可以感知到,进而删除临时节点。zookeeper 的这一特性和服务下线的需求契合的比较好,所以临时节点被广泛应用。
主动下线 + 心跳检测
并不是所有注册中心都有临时节点的概念,另外一种感知服务下线的方式是主动下线。例如在 eureka 中,会有 eureka-server 和 eureka-client 两个角色,其中 eureka-server 保存注册信息,地位等同于 zookeeper。当 eureka-client 需要关闭时,会发送一个通知给 eureka-server,从而让 eureka-server 摘除自己这个节点。但这么做最大的一个问题是,如果仅仅只有主动下线这么一个手段,一旦 eureka-client 非正常下线(如断电,断网),eureka-server 便会一直存在一个已经下线的服务节点,一旦被其他服务发现进而调用,便会带来问题。为了避免出现这样的情况,需要给 eureka-server 增加一个心跳检测功能,它会对服务提供者进行探测,比如每隔 30s 发送一个心跳,如果三次心跳结果都没有返回值,就认为该服务已下线。
服务的健康检查是如何做的 ?
健康检查分为客户端心跳和服务端主动探测两种方式。
- 客户端心跳
- 客户端每隔一定时间主动发送“心跳”的方式来向服务端表明自己的服务状态正常,心跳可以是 TCP 的形式,也可以是 HTTP 的形式。
- 也可以通过维持客户端和服务端的一个 socket 长连接自己实现一个客户端心跳的方式。
- ZooKeeper 并没有主动的发送心跳,而是依赖了组件本身提供的临时节点的特性,通过 ZooKeeper 连接的 session 来维持临时节点。
但是客户端心跳中,长连接的维持和客户端的主动心跳都只是表明链路上的正常,不一定是服务状态正常。
服务端主动调用服务进行健康检查是一个较为准确的方式,返回结果成功表明服务状态确实正常。
- 服务端主动探测
- 服务端调用服务发布者某个 HTTP 接口来完成健康检查。
- 对于没有提供 HTTP 服务的 RPC 应用,服务端调用服务发布者的接口来完成健康检查。
- 可以通过执行某个脚本的形式来进行综合检查。
服务端主动探测也存在问题。服务注册中心主动调用 RPC 服务的某个接口无法做到通用性;在很多场景下服务注册中心到服务发布者的网络是不通的,服务端无法主动发起健康检查。
所以如何取舍,还是需要根据实际情况来决定,根据不同的场景,选择不同的策略。
Reference
- https://www.nginx.com/blog/service-discovery-in-a-microservices-architecture/
- https://microservices.io/patterns/service-registry.html
- https://juejin.im/post/5bb77923f265da0af3348aa3
- http://jm.taobao.org/2018/06/26/%E8%81%8A%E8%81%8A%E5%BE%AE%E6%9C%8D%E5%8A%A1%E7%9A%84%E6%9C%8D%E5%8A%A1%E6%B3%A8%E5%86%8C%E4%B8%8E%E5%8F%91%E7%8E%B0/
- https://crossoverjie.top/2018/08/27/distributed/distributed-discovery-zk/
- https://www.cnkirito.moe/rpc-registry/