Eureka
Eureka是在Java语言上,基于Restful Api开发的服务注册与发现组件,由Netflix开源。遗憾的是,目前Eureka仅开源到1.X版本,2.X版本已经宣布闭源。
Eureka采用的是Server/Client的模式进行设计。Server扮演了服务注册中心的角色,为Client提供服务注册和发现的功能,维护着注册到自身的Client的相关信息,同时提供接口给Client获取到注册表中其他服务的信息。Client将有关自己的服务的信息通过一定的方式登记到Server上,并在正常范围内维护自己信息的一致性,方便其他服务发现自己,同时可以通过Server获取到自己的依赖的其他服务信息,从而完成服务调用。
它的架构图如下所示:
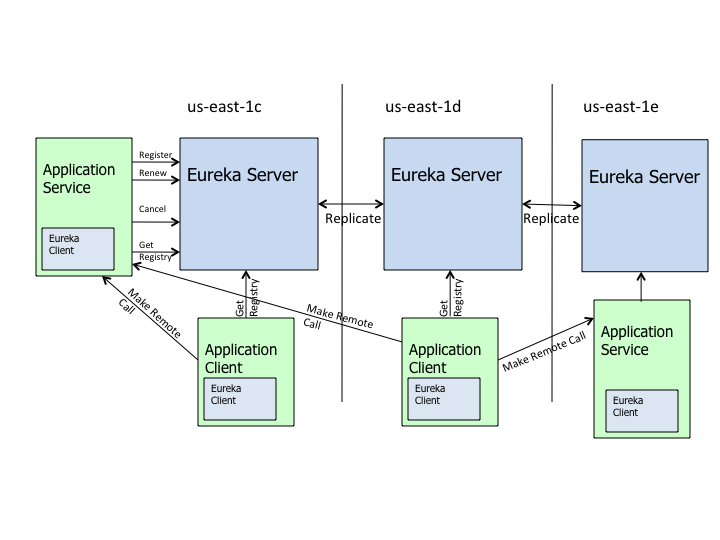
The architecture above depicts how Eureka is deployed at Netflix and this is how you would typically run it. There is one eureka cluster per region which knows only about instances in its region. There is at the least one eureka server per zone to handle zone failures.
Services register with Eureka and then send heartbeats to renew their leases every 30 seconds. If the client cannot renew the lease for a few times, it is taken out of the server registry in about 90 seconds. The registration information and the renewals are replicated to all the eureka nodes in the cluster. The clients from any zone can look up the registry information (happens every 30 seconds) to locate their services (which could be in any zone) and make remote calls.
- Application Service: 作为Eureka Client,扮演了服务的提供者,提供业务服务,向Eureka Server注册和更新自己的信息,同时能从Eureka Server的注册表中获取到其他服务的信息。
- Eureka Server:扮演服务注册中心的角色,提供服务注册和发现的功能,每个Eureka Cient向Eureka Server注册自己的信息,也可以通过Eureka Server获取到其他服务的信息达到发现和调用其他服务的目的。
- Application Client:作为Eureka Client,扮演了服务消费者,通过Eureka Server获取到注册到上面的其他服务的信息,从而根据信息找到所需的服务发起远程调用。
- Replicate: Eureka Server中的注册表信息的同步拷贝,保持不同的Eureka Server集群中的注册表中的服务实例信息的一致性。提供了数据的最终一致性。
- Make Remote Call: 服务之间的远程调用。
- Register: 注册服务实例,Client端向Server端注册自身的元数据以进行服务发现。
- Renew:续约,通过发送心跳到Server维持和更新注册表中的服务实例元数据的有效性。当在一定时长内Server没有收到Client的心跳信息,将默认服务下线,将服务实例的信息从注册表中删除。
- Cancel:服务下线,Client在关闭时主动向Server注销服务实例元数据,这时Client的的服务实例数据将从Server的注册表中删除。
Eureka中没有使用任何的数据强一致性算法保证不同集群间的Server的数据一致,仅通过数据拷贝的方式争取注册中心数据的最终一致性,虽然放弃数据强一致性但是换来了Server的可用性,降低了注册的代价,提高了集群运行的健壮性。
Consul
Consul是由HashiCorp基于Go语言开发的支持多数据中心分布式高可用的服务发布和注册服务软件,采用Raft算法保证服务的一致性,且支持健康检查。
Consul采用主从模式的设计,使得集群的数量可以大规模扩展,集群间通过RPC的方式调用(HTTP和DNS)。它的结构图如下所示:
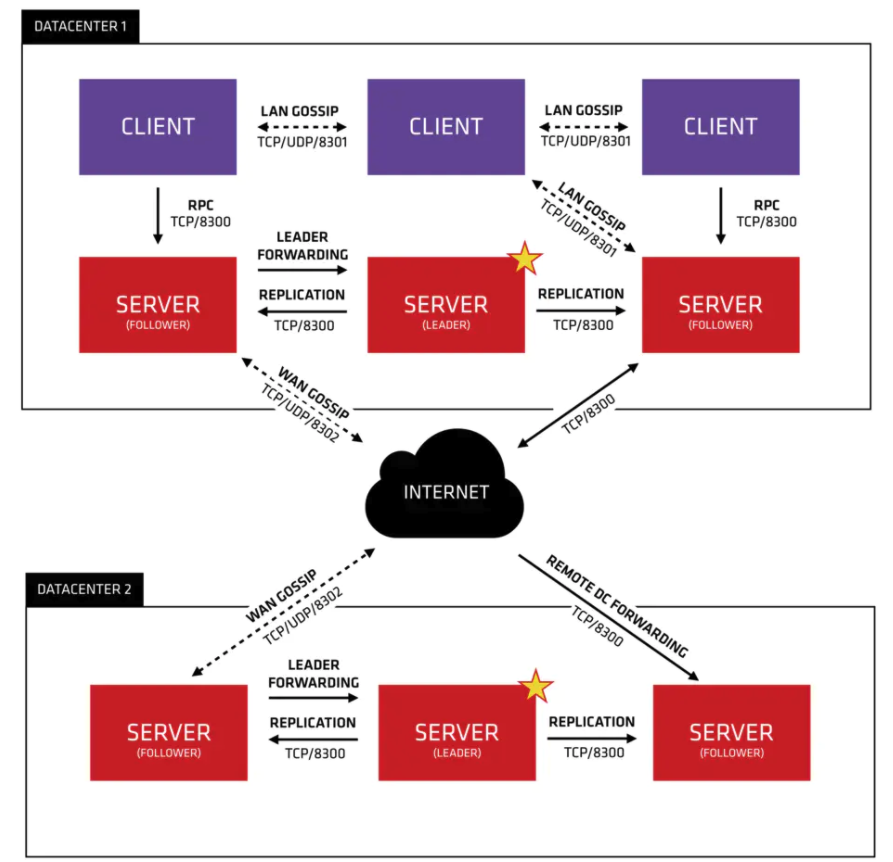
- Client:作为一个代理(非微服务实例),它将转发所有的RPC请求到Server中。作为相对无状态的服务,它不持有任何注册信息。
- Server:作为一个具备扩展功能的代理,它将响应RPC查询、参与Raft选举、维护集群状态和转发查询给Leader等。
- Leader-Server:一个数据中心的所有Server都作为Raft节点集合的一部分。其中Leader将负责所有的查询和事务(如服务注册),同时这些事务也会被复制到所有其他的节点。
- Data Center:数据中心作为一个私有的,低延迟和高带宽的一个网络环境。每个数据中心会存在Consul集群,一般建议Server是3-5台(考虑到Raft算法在可用性和性能上取舍),而Leader只能唯一,Client的数量没有限制,可以轻松扩展。
Raft算法
Raft算法将Server分为三种类型:Leader、Follower和Candidate。Leader处理所有的查询和事务,并向Follower同步事务。Follower会将所有的RPC查询和事务转发给Leader处理,它仅从Leader接受事务的同步。数据的一致性以Leader中的数据为准实现。
在节点初始启动时,节点的Raft状态机将处于Follower状态等待来来自Leader节点的心跳。如果在一定时间周期内没有收到Leader节点的心跳,节点将发起选举。
Follower节点选举时会将自己的状态切换为Candidate,然后向集群中其它Follower节点发送请求,询问其是否选举自己成为Leader。当收到来自集群中过半数节点的接受投票后,节点即成为Leader,开始接收Client的事务处理和查询并向其它的Follower节点同步事务。Leader节点会定时向Follower发送心跳来保持其地位。
Gossip协议
Gossip协议是为了解决分布式环境下监控和事件通知的瓶颈。Gossip协议中的每个Agent会利用Gossip协议互相检查在线状态,分担了服务器节点的心跳压力,通过Gossip广播的方式发送消息。
所有的Agent都运行着Gossip协议。服务器节点和普通Agent都会加入这个Gossip集群,收发Gossip消息。每隔一段时间,每个节点都会随机选择几个节点发送Gossip消息,其他节点会再次随机选择其他几个节点接力发送消息。这样一段时间过后,整个集群都能收到这条消息。
基于Raft算法,Consul提供强一致性的注册中心服务,但是由于Leader节点承担了所有的处理工作,势必加大了注册和发现的代价,降低了服务的可用性。通过Gossip协议,Consul可以很好地监控Consul集群的运行,同时可以方便通知各类事件,如Leader选择发生、Server地址变更等。
Zookeeper
Zookeeper 最初是由 Yahoo 开源的分布式协调服务,是 Hadoop 和 Hbase 的重要组件,提供了数据/发布订阅、负载均衡、分布式同步等功能。
Zookeeper也是基于主从架构,搭建了一个可高扩展的服务集群,其服务架构如下:

- Leader-Server:Leader负责进行投票的发起和决议,更新系统中的数据状态
- Server:Server中存在两种类型:Follower和Observer。其中Follower接受客户端的请求并返回结果(事务请求将转发给Leader处理),并在选举过程中参与投票;Observer与Follower功能一致,但是不参与投票过程,它的存在是为了提高系统的读取速度
- Client:请求发起方,Server和Client之间可以通过长连接的方式进行交互。如发起注册或者请求集群信息等。
Zookeeper 如何实现服务注册/发现
在具体讨论怎么实现之前先看看 Zookeeper 的几个重要特性。
Zookeeper 实现了一个类似于文件系统的树状结构:
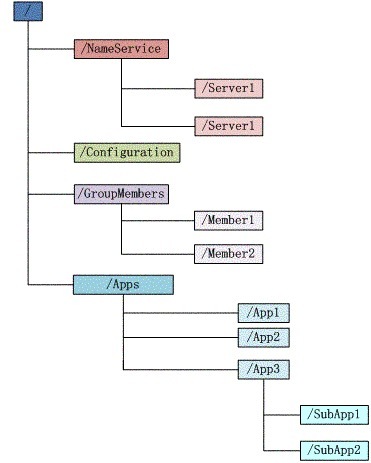
这些节点被称为 znode(名字叫什么不重要),其中每个节点都可以存放一定的数据。
最主要的是 znode 有四种类型:
- 永久节点(persistent node)(除非手动删除,节点永远存在)
- 永久有序节点(persistent sequential node)(按照创建顺序会为每个节点末尾带上一个序号如:
root-1) - 瞬时节点(ephemeral node)(创建客户端与 Zookeeper 保持连接时节点存在,断开时则删除并会有相应的通知)
- 瞬时有序节点(ephemeral sequential node)(在瞬时节点的基础上加上了顺序)
考虑下上文使用 Redis 最大的一个问题是什么?
其实就是不能实时的更新服务提供者的信息。
那利用 Zookeeper 是怎么实现的?
主要看第三个特性:瞬时节点
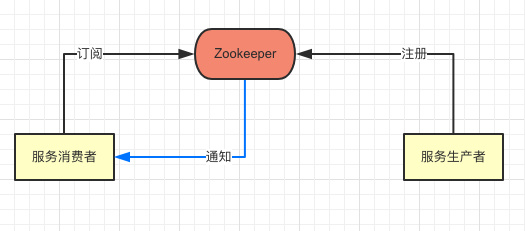
Zookeeper 是一个典型的观察者模式。
- 由于瞬时节点的特点,我们的消费者可以订阅瞬时节点的父节点。
- 当新增、删除节点时所有的瞬时节点也会自动更新。
- 更新时会给订阅者发起通知告诉最新的节点信息。
这样我们就可以实时获取服务节点的信息,同时也只需要在第一次获取列表时缓存到本地;也不需要频繁和 Zookeeper 产生交互,只用等待通知更新即可。
并且不管应用什么原因节点 down 掉后也会在 Zookeeper 中删除该信息。
效果演示
这样实现方式就变为这样。
Zab协议
ZooKeeper Atomic Broadcast protocol是专门设计给Zookeeper用于实现分布式系统数据的一致性,是在Paxos算法基础上发展而来。它使用了单一的Leader来接受和处理客户端的所有事务请求,并将服务器数据的状态变更以事务Proposal的形式广播到所有的Server中。同时它保证Leader出现异常时,集群依旧能够正常工作。Zab包含两种基本模式:崩溃恢复和消息广播。
- 崩溃恢复:Leader服务器出现宕机,或者因为网络原因导致Leader服务器失去了与过半 Follower的联系,那么就会进入崩溃恢复模式从而选举新的Leader。Leader选举算法不仅仅需要让Leader自己知道其自身已经被选举为Leader,同时还需要让集群中的所有其他服务器也能够快速地感知到选举产生的新的Leader。当选举产生了新的Leader,同时集群中有过半的服务器与该Leader完成了状态同步之后,Zab协议就会退出崩溃恢复模式,进入消息广播模式。
- 消息广播:Zab协议的消息广播过程类似二阶段提供过程,是一种原子广播的协议。当接受到来自Client的事务请求(如服务注册)(所有的事务请求都会转发给Leader),Leader会为事务生成对应的Proposal,并为其分配一个全局唯一的ZXID。Leader服务器与每个Follower之间都有一个单独的队列进行收发消息,Leader将生成的Proposal发送到队列中。Follower从队列中取出Proposal进行事务消费,消费完毕后发送一个ACK给Leader。当Leader接受到半数以上的Follower发送的ACK投票,它将发送Commit给所有Follower通知其对事务进行提交,Leader本身也会提交事务,并返回给处理成功给对应的客户端。Follower只有将队列中Proposal都同步消费后才可用。
基于Zab协议,Zookeeper可以用于构建具备数据强一致性的服务注册与发现中心,而与此相对地牺牲了服务的可用性和提高了注册需要的时间。
Etcd
Nacos
异同点
| Feature | Consul | ZooKeeper | etcd | Euerka |
|---|---|---|---|---|
| 服务健康检查 | 服务状态,内存,硬盘等 | (弱) 长连接,keepalive | 连接心跳 | 可配置 |
| 多数据中心 | 支持 | — | — | — |
| kv 存储服务 | 支持 | 支持 | 支持 | — |
| 一致性 | Raft | Paxos | Raft | — |
| CAP | CA | CP | CP | AP |
| 使用接口 (多语言能力) | 支持 http 和 dns | 客户端 | http/grpc | http(sidecar) |
| watch 支持 | 全量 / 支持 long polling | 支持 | 支持 long polling | 支持 long polling/ 大部分增量 |
| 自身监控 | metrics | — | metrics | metrics |
| 安全 | acl /https | acl | HTTPS 支持(弱) | — |
| spring cloud 集成 | 已支持 | 已支持 | 已支持 | 已支持 |
| 语言 | Golang | Java | Golang | Java |
| 对外暴露接口 | HTTP/DNS | 客户端 | gRPC | HTTP |
一般而言注册中心的特性决定了其使用的场景,例如很多框架支持 zookeeper,在我自己看来是因为其老牌,易用,但业界也有很多人认为 zookeeper 不适合做注册中心,它本身是一个分布式协调组件,并不是为注册服务而生,server 端注册一个服务节点,client 端并不需要在同一时刻拿到完全一致的服务列表,只要最终一致性即可。在跨 IDC,多数据中心等场景下 consul 发挥了很大的优势,这也是很多互联网公司选择使用 consul 的原因。 eureka 是 ap 注册中心,并且是 spring cloud 默认使用的组件,spring cloud eureka 较为贴近 spring cloud 生态。
一致性对比
- ZK 的设计原则是 CP,即强一致性和分区容错性。他保证数据的强一致性,但舍弃了可用性,如果出现网络问题可能会影响 ZK 的选举,导致 ZK 注册中心的不可用。
- Eureka 的设计原则是 AP,即可用性和分区容错性。他保证了注册中心的可用性,但舍弃了数据一致性,各节点上的数据有可能是不一致的(会最终一致)。
Example
Dubbo
Dubbo支持多种注册中心的实现,常用的是:
- Redis
- Zookeeper
官方推荐 Zookeeper。
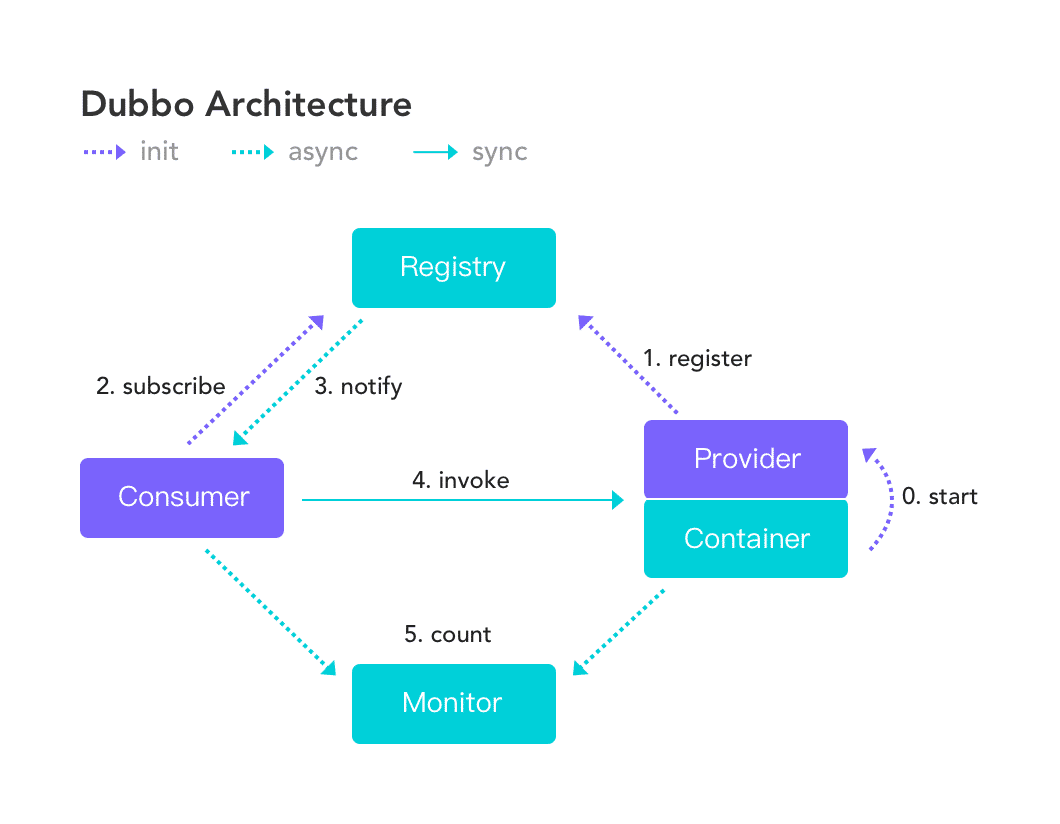
在Dubbo架构图中,可以看到注册中心(Registry)位于顶端,所有的服务治理相关的操作都围绕它进行。服务提供者(Provider)注册到注册中心,服务消费者(Comsumer)到注册中心订阅,同时,注册中心中的变更也会通知服务消费者。
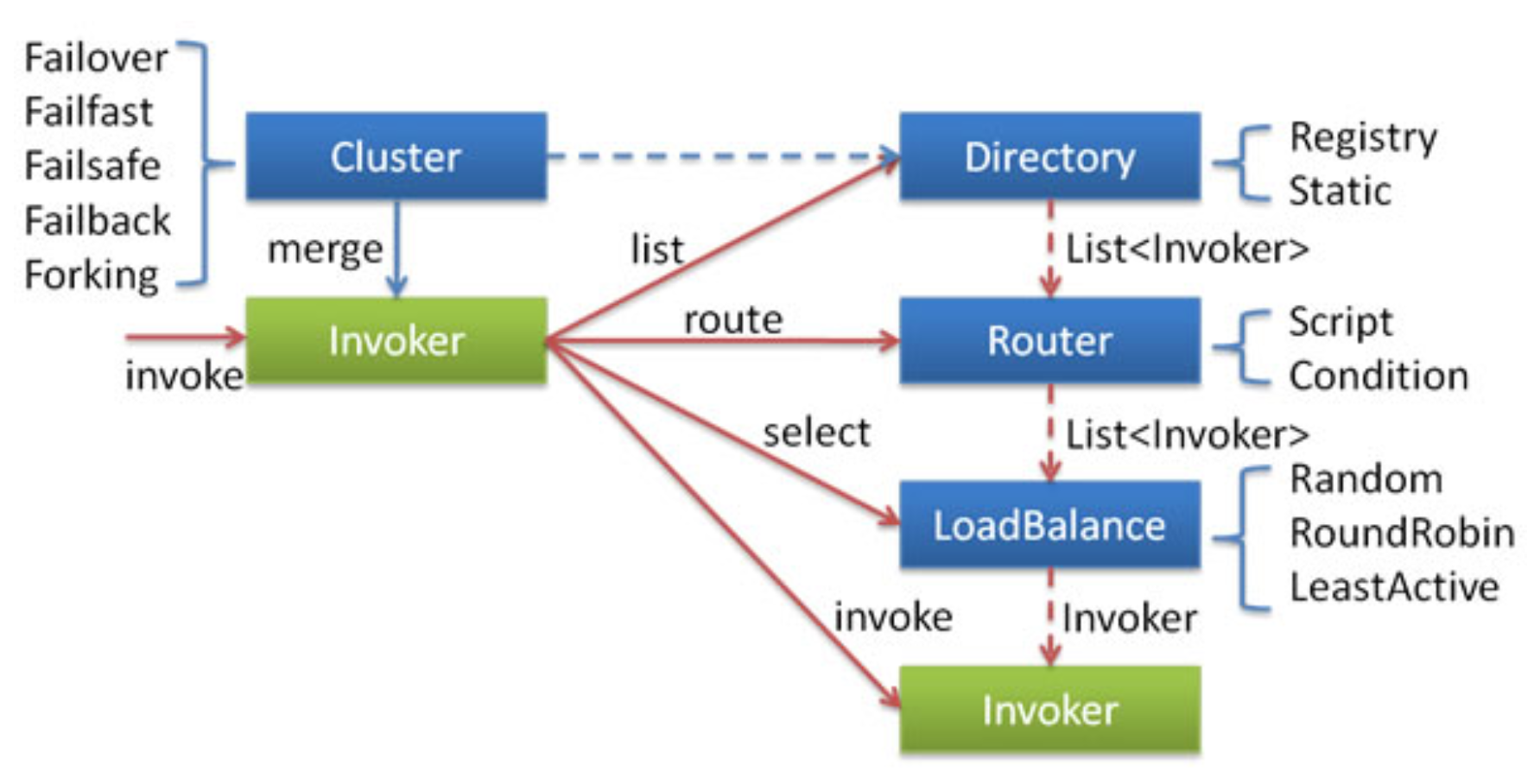
面对服务消费方,当业务逻辑中需要调用一个服务时,真正调用的其实是 Dubbo 创建的一个 Proxy,该 Proxy 会把调用转化成调用指定的 Invoker(Cluster 将 Directory 中的多个 Invoker 伪装成一个 Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个(通过 LoadBalance),Invoker 封装了 Provider 地址及 Service 接口信息)。而在这一系列的委托调用的过程里就完成了服务治理的逻辑,最终完成调用。
Spring Cloud
目前,SpringCloud可以说是最流行的微服务架构,SpingCloud整个体系功能完备,与Spring框架完美契合,开箱即用,极大降低了落地微服务架构的开发成本。在SpringCloud中,也是支持多种注册中心的:
- Spring Cloud Netflix Eureka
- Spring Cloud Zookeeper
- Spring Cloud Consul
以上三种,最常用的主要是Eureka(这也是官方推荐的),官方是这样定义的:
Eureka is a REST (Representational State Transfer) based service that is primarily used in the AWS cloud for locating services for the purpose of load balancing and failover of middle-tier servers.
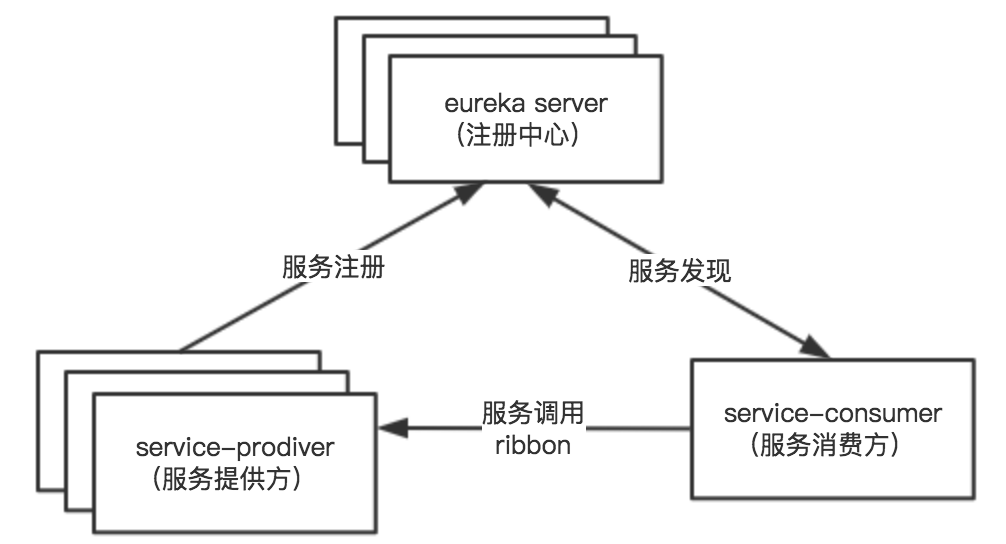
与Dubbo对于服务注册的抽象有所不同,Eureka使用的是C/S架构:
- Eureka Server,注册中心
- Eureka Client,服务消费者和服务提供者
而且,Eureka支持多节点的部署,从而保证高可用。生产环境中,常用的方式是部署两台节点,做成一个P2P的集群。
Reference
- https://juejin.im/post/5bb77923f265da0af3348aa3
- https://github.com/Netflix/eureka/wiki/Eureka-at-a-glance
- https://etcd.io/
- https://github.com/etcd-io/etcd
- http://jm.taobao.org/2018/06/26/%E8%81%8A%E8%81%8A%E5%BE%AE%E6%9C%8D%E5%8A%A1%E7%9A%84%E6%9C%8D%E5%8A%A1%E6%B3%A8%E5%86%8C%E4%B8%8E%E5%8F%91%E7%8E%B0/
- https://crossoverjie.top/2018/08/27/distributed/distributed-discovery-zk/
- https://www.cnkirito.moe/rpc-registry/
- https://segmentfault.com/a/1190000016097418
- https://www.infoq.cn/article/jlDJQ*3wtN2PcqTDyokh