MySQL 中的锁
- 全局锁
- 表级锁
- 表锁 table locks
- AUTO-INC 锁
- 元数据锁 Metadata lock
- 意向锁 Intention Locks
- 行级锁
- 记录锁 Record Lock:也就是仅仅把一条记录锁上
- 间隙锁 Gap Lock:锁定一个范围,但是不包含记录本身
- Next-Key Lock:Record Lock + Gap Lock 的组合,锁定一个范围,并且锁定记录本身
全局锁
要使用全局锁,则要执行这条命令:
flush tables with read lock
执行后,整个数据库就处于只读状态了,这时其他线程执行以下操作,都会被阻塞:
- 对数据的增删改操作,比如 insert、delete、update等语句;
- 对表结构的更改操作,比如 alter table、drop table 等语句。
如果要释放全局锁,则要执行这条命令:
unlock tables
当然,当会话断开了,全局锁会被自动释放。
应用场景
全局锁主要应用于做全库逻辑备份,这样在备份数据库期间,不会因为数据或表结构的更新,而出现备份文件的数据与预期的不一样。
举个例子大家就知道了。
在全库逻辑备份期间,假设不加全局锁的场景,看看会出现什么意外的情况。
如果在全库逻辑备份期间,有用户购买了一件商品,一般购买商品的业务逻辑是会涉及到多张数据库表的更新,比如在用户表更新该用户的余额,然后在商品表更新被购买的商品的库存。
那么,有可能出现这样的顺序:
- 先备份了用户表的数据;
- 然后有用户发起了购买商品的操作;
- 接着再备份商品表的数据。
也就是在备份用户表和商品表之间,有用户购买了商品。
这种情况下,备份的结果是用户表中该用户的余额并没有扣除,反而商品表中该商品的库存被减少了,如果后面用这个备份文件恢复数据库数据的话,用户钱没少,而库存少了,等于用户白嫖了一件商品。
所以,在全库逻辑备份期间,加上全局锁,就不会出现上面这种情况了。
缺点
加上全局锁,意味着整个数据库都是只读状态。
那么如果数据库里有很多数据,备份就会花费很多的时间,关键是备份期间,业务只能读数据,而不能更新数据,这样会造成业务停滞。
既然备份数据库数据的时候,使用全局锁会影响业务,那有什么其他方式可以避免?
有的,如果数据库的引擎支持的事务支持可重复读的隔离级别,那么在备份数据库之前先开启事务,会先创建 Read View,然后整个事务执行期间都在用这个 Read View,而且由于 MVCC 的支持,备份期间业务依然可以对数据进行更新操作。
因为在可重复读的隔离级别下,即使其他事务更新了表的数据,也不会影响备份数据库时的 Read View,这就是事务四大特性中的隔离性,这样备份期间备份的数据一直是在开启事务时的数据。
备份数据库的工具是 mysqldump,在使用 mysqldump 时加上 –single-transaction 参数的时候,就会在备份数据库之前先开启事务。这种方法只适用于支持「可重复读隔离级别的事务」的存储引擎。
InnoDB 存储引擎默认的事务隔离级别正是可重复读,因此可以采用这种方式来备份数据库。
但是,对于 MyISAM 这种不支持事务的引擎,在备份数据库时就要使用全局锁的方法。
表级锁(Table-level Lock)
表锁 Table Locks
LOCK TABLES
tbl_name [[AS] alias] lock_type
[, tbl_name [[AS] alias] lock_type] ...
lock_type: {
READ [LOCAL]
| [LOW_PRIORITY] WRITE
}
UNLOCK TABLES
MySQL enables client sessions to acquire table locks explicitly for the purpose of cooperating with other sessions for access to tables, or to prevent other sessions from modifying tables during periods when a session requires exclusive access to them. A session can acquire or release locks only for itself. One session cannot acquire locks for another session or release locks held by another session.
Locks may be used to emulate transactions or to get more speed when updating tables.
LOCK TABLES explicitly acquires table locks for the current client session. Table locks can be acquired for base tables or views. You must have the LOCK TABLES privilege, and the SELECT privilege for each object to be locked.
Example
如果我们想对学生表(t_student)加表锁,可以使用下面的命令:
-- 表级别的共享锁,也就是读锁;
lock tables t_student read;
-- 表级别的独占锁,也就是写锁;
lock tables t_stuent write;
需要注意的是,表锁除了会限制别的线程的读写外,也会限制本线程接下来的读写操作。
也就是说如果本线程对学生表加了「共享表锁」,那么本线程接下来如果要对学生表执行写操作的语句,是会被阻塞的,当然其他线程对学生表进行写操作时也会被阻塞,直到锁被释放。
要释放表锁,可以使用下面这条命令,会释放当前会话的所有表锁:
unlock tables
另外,当会话退出后,也会释放所有表锁。
不过尽量避免在使用 InnoDB 引擎的表使用表锁,因为表锁的颗粒度太大,会影响并发性能,InnoDB 牛逼的地方在于实现了颗粒度更细的行级锁。
AUTO-INC Locks
表里的主键通常都会设置成自增的,这是通过对主键字段声明 AUTO_INCREMENT 属性实现的。
之后可以在插入数据时,可以不指定主键的值,数据库会自动给主键赋值递增的值,这主要是通过 AUTO-INC 锁实现的。
AUTO-INC 锁是特殊的表锁机制,锁不是再一个事务提交后才释放,而是再执行完插入语句后就会立即释放。
在插入数据时,会加一个表级别的 AUTO-INC 锁,然后为被 AUTO_INCREMENT 修饰的字段赋值递增的值,等插入语句执行完成后,才会把 AUTO-INC 锁释放掉。
那么,一个事务在持有 AUTO-INC 锁的过程中,其他事务的如果要向该表插入语句都会被阻塞,从而保证插入数据时,被 AUTO_INCREMENT 修饰的字段的值是连续递增的。
但是, AUTO-INC 锁再对大量数据进行插入的时候,会影响插入性能,因为另一个事务中的插入会被阻塞。
The innodb_autoinc_lock_mode variable controls the algorithm used for auto-increment locking. It allows you to choose how to trade off between predictable sequences of auto-increment values and maximum concurrency for insert operations.
元数据锁 Metadata lock
再来说说元数据锁(MDL)。
我们不需要显示的使用 MDL,因为当我们对数据库表进行操作时,会自动给这个表加上 MDL:
- 对一张表进行 CRUD 操作时,加的是 MDL 读锁;
- 对一张表做结构变更操作的时候,加的是 MDL 写锁;
MDL 是为了保证当用户对表执行 CRUD 操作时,防止其他线程对这个表结构做了变更。
当有线程在执行 select 语句( 加 MDL 读锁)的期间,如果有其他线程要更改该表的结构( 申请 MDL 写锁),那么将会被阻塞,直到执行完 select 语句( 释放 MDL 读锁)。
反之,当有线程对表结构进行变更( 加 MDL 写锁)的期间,如果有其他线程执行了 CRUD 操作( 申请 MDL 读锁),那么就会被阻塞,直到表结构变更完成( 释放 MDL 写锁)。
Notes
MDL 不需要显示调用,那它是在什么时候释放的?
MDL 是在事务提交后才会释放,这意味着事务执行期间,MDL 是一直持有的。
那如果数据库有一个长事务(所谓的长事务,就是开启了事务,但是一直还没提交),那在对表结构做变更操作的时候,可能会发生意想不到的事情,比如下面这个顺序的场景:
- 首先,线程 A 先启用了事务(但是一直不提交),然后执行一条 select 语句,此时就先对该表加上 MDL 读锁;
- 然后,线程 B 也执行了同样的 select 语句,此时并不会阻塞,因为「读读」并不冲突;
- 接着,线程 C 修改了表字段,此时由于线程 A 的事务并没有提交,也就是 MDL 读锁还在占用着,这时线程 C 就无法申请到 MDL 写锁,就会被阻塞,
那么在线程 C 阻塞后,后续有对该表的 select 语句,就都会被阻塞,如果此时有大量该表的 select 语句的请求到来,就会有大量的线程被阻塞住,这时数据库的线程很快就会爆满了。
为什么线程 C 因为申请不到 MDL 写锁,而导致后续的申请读锁的查询操作也会被阻塞?
这是因为申请 MDL 锁的操作会形成一个队列,队列中写锁获取优先级高于读锁,一旦出现 MDL 写锁等待,会阻塞后续该表的所有 CRUD 操作。
所以为了能安全的对表结构进行变更,在对表结构变更前,先要看看数据库中的长事务,是否有事务已经对表加上了 MDL 读锁,如果可以考虑 kill 掉这个长事务,然后再做表结构的变更。
意向锁 Intention Lock
Intention locks are table-level locks that indicate which type of lock (shared or exclusive) a transaction requires later for a row in a table. There are two types of intention locks:
- An intention shared lock (
IS, 意向共享锁) indicates that a transaction intends to set a shared lock on individual rows in a table. - An intention exclusive lock (
IX, 意向独占锁) indicates that a transaction intends to set an exclusive lock on individual rows in a table.
For example, SELECT ... FOR SHARE sets an IS lock, and SELECT ... FOR UPDATE sets an IX lock.
Intention locks do not block anything except full table requests (for example, LOCK TABLES ... WRITE). The main purpose of intention locks is to show that someone is locking a row, or going to lock a row in the table.
Transaction data for an intention lock appears similar to the following in SHOW ENGINE INNODB STATUS and InnoDB monitor output:
TABLE LOCK table `test`.`t` trx id 10080 lock mode IX
Note
- 在使用 InnoDB 引擎的表里对某些记录加上「共享锁」之前,需要先在表级别加上一个「意向共享锁」;
- 在使用 InnoDB 引擎的表里对某些纪录加上「独占锁」之前,需要先在表级别加上一个「意向独占锁」;
也就是,当执行插入、更新、删除操作,需要先对表加上「意向独占锁」,然后对该记录加独占锁。
而普通的 select 是不会加行级锁的,普通的 select 语句是利用 MVCC 实现一致性读,是无锁的。
不过,select 也是可以对记录加记录共享锁和记录独占锁的,具体方式如下:
-- 先在表上加上意向共享锁,然后对读取的记录加记录共享锁
select ... lock in share mode;
-- 先表上加上意向独占锁,然后对读取的记录加记录独占锁
select ... for update;
意向共享锁和意向独占锁是表级锁,不会和行级的共享锁和独占锁发生冲突,而且意向锁之间也不会发生冲突。意向共享锁和意向独占锁只会和共享表锁(*lock tables … read*)和独占表锁(*lock tables … write*)发生冲突。
表锁和行锁是满足读读共享、读写互斥、写写互斥的。
如果没有「意向锁」,那么加「独占表锁」时,就需要遍历表里所有记录,查看是否有记录存在独占锁,这样效率会很慢。
那么有了「意向锁」,由于在对记录加独占锁前,先会加上表级别的意向独占锁,那么在加「独占表锁」时,直接查该表是否有意向独占锁,如果有就意味着表里已经有记录被加了独占锁,这样就不用去遍历表里的记录。
所以,意向锁的目的是为了快速判断表里是否有记录被加锁(表里是否有行级锁)。
行级锁(Record-level Lock)
InnoDB 引擎是支持行级锁的,而 MyISAM 引擎并不支持行级锁。
前面也提到,普通的 select 语句是不会对记录加锁的,因为它属于快照读(基于MVCC)。
如果要在查询时对记录加行锁,可以使用下面这两个方式,这种查询会加锁的语句称为锁定读。
-- 对读取的记录加共享锁
select ... lock in share mode;
-- 对读取的记录加独占锁
select ... for update;
上面这两条语句必须在一个事务中,因为当事务提交了,锁就会被释放,所以在使用这两条语句的时候,要加上 begin、start transaction 或者 set autocommit = 0。
记录锁(Record Locks)
A record lock is a lock on an index record. For example, SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE; prevents any other transaction from inserting, updating, or deleting rows where the value of t.c1 is 10.
Record locks always lock index records, even if a table is defined with no indexes. For such cases, InnoDB creates a hidden clustered index and uses this index for record locking.
记录锁是有 S 锁和 X 锁之分的:
- 当一个事务对一条记录加了 S 型记录锁后,其他事务也可以继续对该记录加 S 型记录锁(S 型与 S 锁兼容),但是不可以对该记录加 X 型记录锁(S 型与 X 锁不兼容);
- 当一个事务对一条记录加了 X 型记录锁后,其他事务既不可以对该记录加 S 型记录锁(S 型与 X 锁不兼容),也不可以对该记录加 X 型记录锁(X 型与 X 锁不兼容)。
举个例子,当一个事务执行了下面这条语句:
mysql > begin;
mysql > select * from t_test where id = 1 for update;
就是对 t_test 表中主键 id 为 1 的这条记录加上 X 型的记录锁,这样其他事务就无法对这条记录进行修改了。
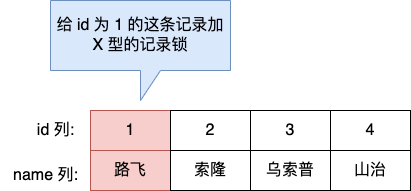
当事务执行 commit 后,事务过程中生成的锁都会被释放。
间隙锁(Gap Locks)
Gap Lock 称为间隙锁,只存在于可重复读隔离级别,目的是为了解决可重复读隔离级别下幻读的现象。
间隙锁是前开后开区间。
假设,表中有一个范围 id 为(3,5)间隙锁,那么其他事务就无法插入 id = 4 这条记录了,这样就有效的防止幻读现象的发生。

间隙锁虽然存在 X 型间隙锁和 S 型间隙锁,但是并没有什么区别,间隙锁之间是兼容的,即两个事务可以同时持有包含共同间隙范围的间隙锁,并不存在互斥关系,因为间隙锁的目的是防止插入幻影记录而提出的。而间隙锁和与其有交集的记录锁或者与其有交集的插入意向锁则会互斥。
以下为证明:
-- Prepare the data
delete from test;
INSERT INTO `test` VALUES ('7', '小明');
INSERT INTO `test` VALUES ('11', '小红');
CREATE TABLE `test` (
`id` int(1) NOT NULL AUTO_INCREMENT,
`name` varchar(8) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- t1
Begin
SELECT * FROM `test` WHERE `id` BETWEEN 8 AND 10 FOR UPDATE
-- t2
Begin
SELECT * FROM `test` WHERE `id` BETWEEN 8 AND 10 FOR UPDATE -- Able to execute
Next-Key 锁
A next-key lock is a combination of a record lock on the index record and a gap lock on the gap before the index record.
InnoDB performs row-level locking in such a way that when it searches or scans a table index, it sets shared or exclusive locks on the index records it encounters. Thus, the row-level locks are actually index-record locks. A next-key lock on an index record also affects the “gap” before that index record. That is, a next-key lock is an index-record lock plus a gap lock on the gap preceding the index record. If one session has a shared or exclusive lock on record R in an index, another session cannot insert a new index record in the gap immediately before R in the index order.
Suppose that an index contains the values 10, 11, 13, and 20. The possible next-key locks for this index cover the following intervals, where a round bracket denotes exclusion of the interval endpoint and a square bracket denotes inclusion of the endpoint:
(negative infinity, 10]
(10, 11]
(11, 13]
(13, 20]
(20, positive infinity)
For the last interval, the next-key lock locks the gap above the largest value in the index and the “supremum” pseudo-record having a value higher than any value actually in the index. The supremum is not a real index record, so, in effect, this next-key lock locks only the gap following the largest index value.
By default, InnoDB operates in REPEATABLE READ transaction isolation level. In this case, InnoDB uses next-key locks for searches and index scans, which prevents phantom rows (see Section 15.7.4, “Phantom Rows”).
Transaction data for a next-key lock appears similar to the following in SHOW ENGINE INNODB STATUS and InnoDB monitor output:
RECORD LOCKS space id 58 page no 3 n bits 72 index `PRIMARY` of table `test`.`t`
trx id 10080 lock_mode X
Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0
0: len 8; hex 73757072656d756d; asc supremum;;
Record lock, heap no 2 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 4; hex 8000000a; asc ;;
1: len 6; hex 00000000274f; asc 'O;;
2: len 7; hex b60000019d0110; asc ;;
假设,表中有一个范围 id 为(3,5] 的 next-key lock,那么其他事务即不能插入 id = 4 记录,也不能修改 id = 5 这条记录。
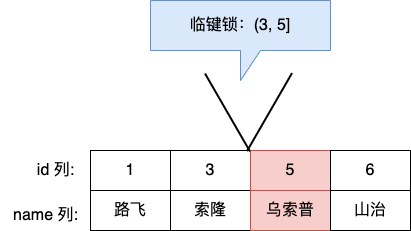
所以,next-key lock 即能保护该记录,又能阻止其他事务将新纪录插入到被保护记录前面的间隙中。
next-key lock 是包含间隙锁+记录锁的,如果一个事务获取了 X 型的 next-key lock,那么另外一个事务在获取相同范围的 X 型的 next-key lock 时,是会被阻塞的。
比如,一个事务持有了范围为 (1, 10] 的 X 型的 next-key lock,那么另外一个事务在获取相同范围的 X 型的 next-key lock 时,就会被阻塞。
虽然相同范围的间隙锁是多个事务相互兼容的,但对于记录锁,我们是要考虑 X 型与 S 型关系,X 型的记录锁与 X 型的记录锁是冲突的。
插入意向锁(Insert Intention Locks)
一个事务在插入一条记录的时候,需要判断插入位置是否已被其他事务加了间隙锁(next-key lock 也包含间隙锁)。
next-key lock 是前开后闭区间。
如果有的话,插入操作就会发生阻塞,直到拥有间隙锁的那个事务提交为止(释放间隙锁的时刻),在此期间会生成一个插入意向锁,表明有事务想在某个区间插入新记录,但是现在处于等待状态。
举个例子,假设事务 A 已经对表加了一个范围 id 为(3,5)间隙锁。
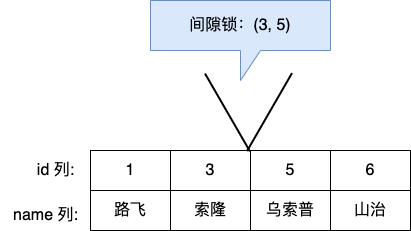
当事务 A 还没提交的时候,事务 B 向该表插入一条 id = 4 的新记录,这时会判断到插入的位置已经被事务 A 加了间隙锁,于是事务 B 会生成一个插入意向锁,然后将锁的状态设置为等待状态(PS:MySQL 加锁时,是先生成锁结构,然后设置锁的状态,如果锁状态是等待状态,并不是意味着事务成功获取到了锁,只有当锁状态为正常状态时,才代表事务成功获取到了锁),此时事务 B 就会发生阻塞,直到事务 A 提交了事务。
插入意向锁名字虽然有意向锁,但是它并不是意向锁,它是一种特殊的间隙锁,属于行级别锁。
如果说间隙锁锁住的是一个区间,那么「插入意向锁」锁住的就是一个点。因而从这个角度来说,插入意向锁确实是一种特殊的间隙锁。
插入意向锁与间隙锁的另一个非常重要的差别是:尽管「插入意向锁」也属于间隙锁,但两个事务却不能在同一时间内,一个拥有间隙锁,另一个拥有该间隙区间内的插入意向锁(当然,插入意向锁如果不在间隙锁区间内则是可以的)。
Show Open Tables
The output can be restricted to a single databases as follows.
mysql> show open tables in test2;
+--------------------+----------------------------------------------------+--------+-------------+
| Database | Table | In_use | Name_locked |
+--------------------+----------------------------------------------------+--------+-------------+
| test2 | tab3 | 1 | 0 |
+--------------------+----------------------------------------------------+--------+-------------+
1 row in set (0.00 sec)
mysql>
Show the Current Locks
select * from performance_schema.data_locks\G;
***************************[ 1. row ]***************************
ENGINE | INNODB
ENGINE_LOCK_ID | 140437116521608:1584:140437369148848
ENGINE_TRANSACTION_ID | 14478934
THREAD_ID | 302
EVENT_ID | 16
OBJECT_SCHEMA | test
OBJECT_NAME | test
PARTITION_NAME | <null>
SUBPARTITION_NAME | <null>
INDEX_NAME | <null>
OBJECT_INSTANCE_BEGIN | 140437369148848
LOCK_TYPE | TABLE
LOCK_MODE | IX # X 的 Intention 锁
LOCK_STATUS | GRANTED
LOCK_DATA | <null>
***************************[ 2. row ]***************************
ENGINE | INNODB
ENGINE_LOCK_ID | 140437116521608:44:4:3:140437360800288
ENGINE_TRANSACTION_ID | 14478934
THREAD_ID | 302
EVENT_ID | 16
OBJECT_SCHEMA | test
OBJECT_NAME | test
PARTITION_NAME | <null>
SUBPARTITION_NAME | <null>
INDEX_NAME | PRIMARY
OBJECT_INSTANCE_BEGIN | 140437360800288
LOCK_TYPE | RECORD
LOCK_MODE | X,REC_NOT_GAP # X 的 Record Lock
LOCK_STATUS | GRANTED
LOCK_DATA | 5
从上图可以看到,共加了两个锁,分别是:
- Table-level locks:IX 是指 X 类型的 Intention Lock;
- Record-level locks:X 类型的 Gap Lock;
LOCK_TYPE
TABLE:Table-level locks, 比如 Table Lock、metadata Lock、Intention Lock、AUTO-INC Lock。通过 LOCK_MODE 可以确认具体是哪种。LOCK_MODEIX: X 的 Intention LockIS: S 的 Intention Lock
RECORD:Record-level locks(而不是 Record Lock 的意思),比如Record Lock, Gap lock。通过 LOCK_MODE 可以确认是 next-key Lock,还是 Gap Lock,还是 Record Lock:- 如果 LOCK_MODE 为
X,说明是 next-key Lock; - 如果 LOCK_MODE 为
X, REC_NOT_GAP,说明是Record Lock; - 如果 LOCK_MODE 为
X, GAP,说明是 Gap Lock; - 根据我的经验,如果 LOCK_MODE 是 next-key Lock或者 Gap Lock,那么 LOCK_DATA 就表示锁的范围最右值
- 如果 LOCK_MODE 为
Reference
- https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.html
- https://xiaolincoding.com/mysql/lock/mysql_lock.html
- https://dev.mysql.com/doc/refman/8.0/en/lock-tables.html
- https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.html
- 《MySQL技术内幕:innodb》
- 《MySQL实战45讲》
- 《从根儿上理解MySQL》